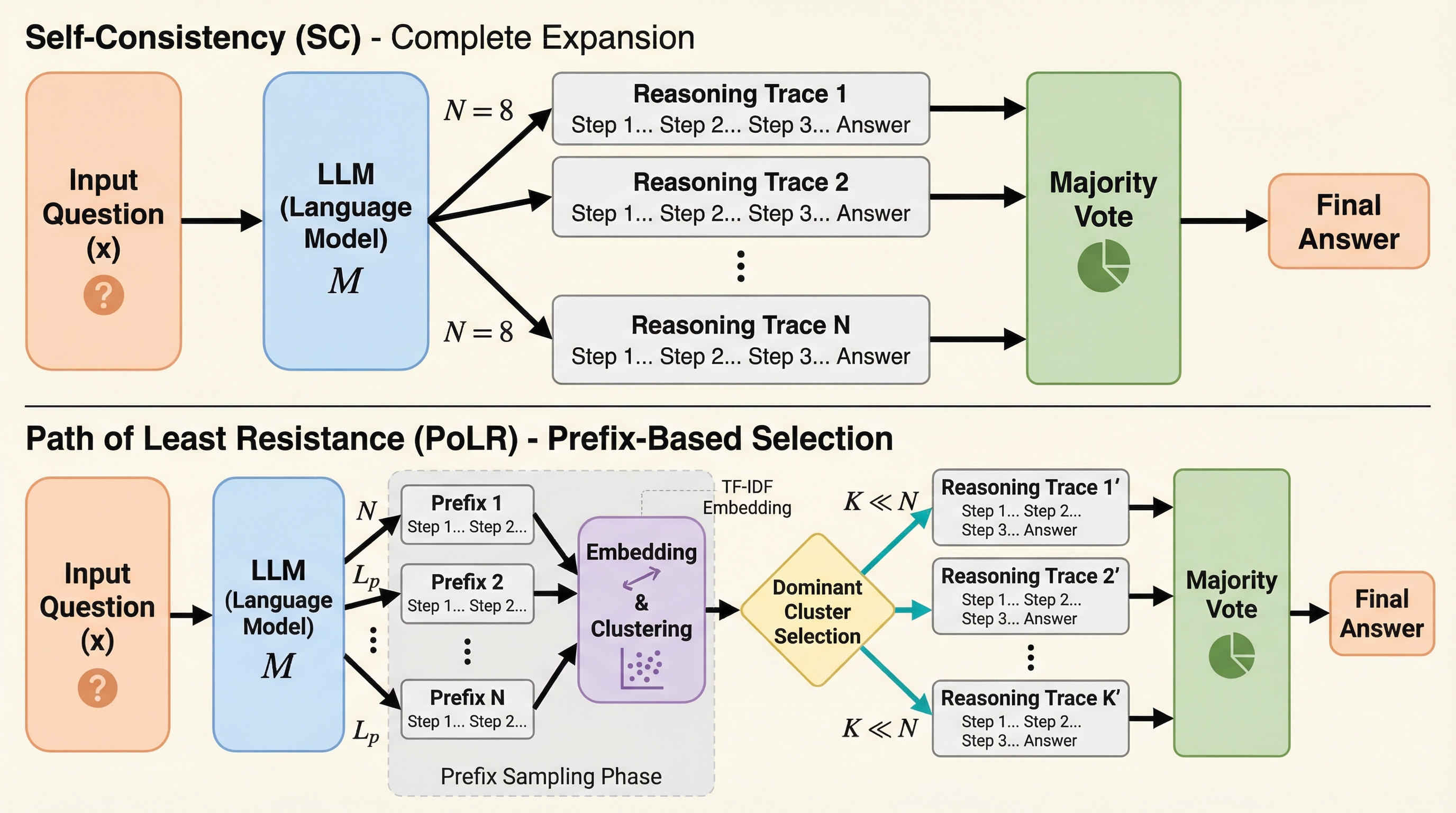
最小抵抗の道:プレフィックス・コンセンサスによるLLM推論軌跡の誘導
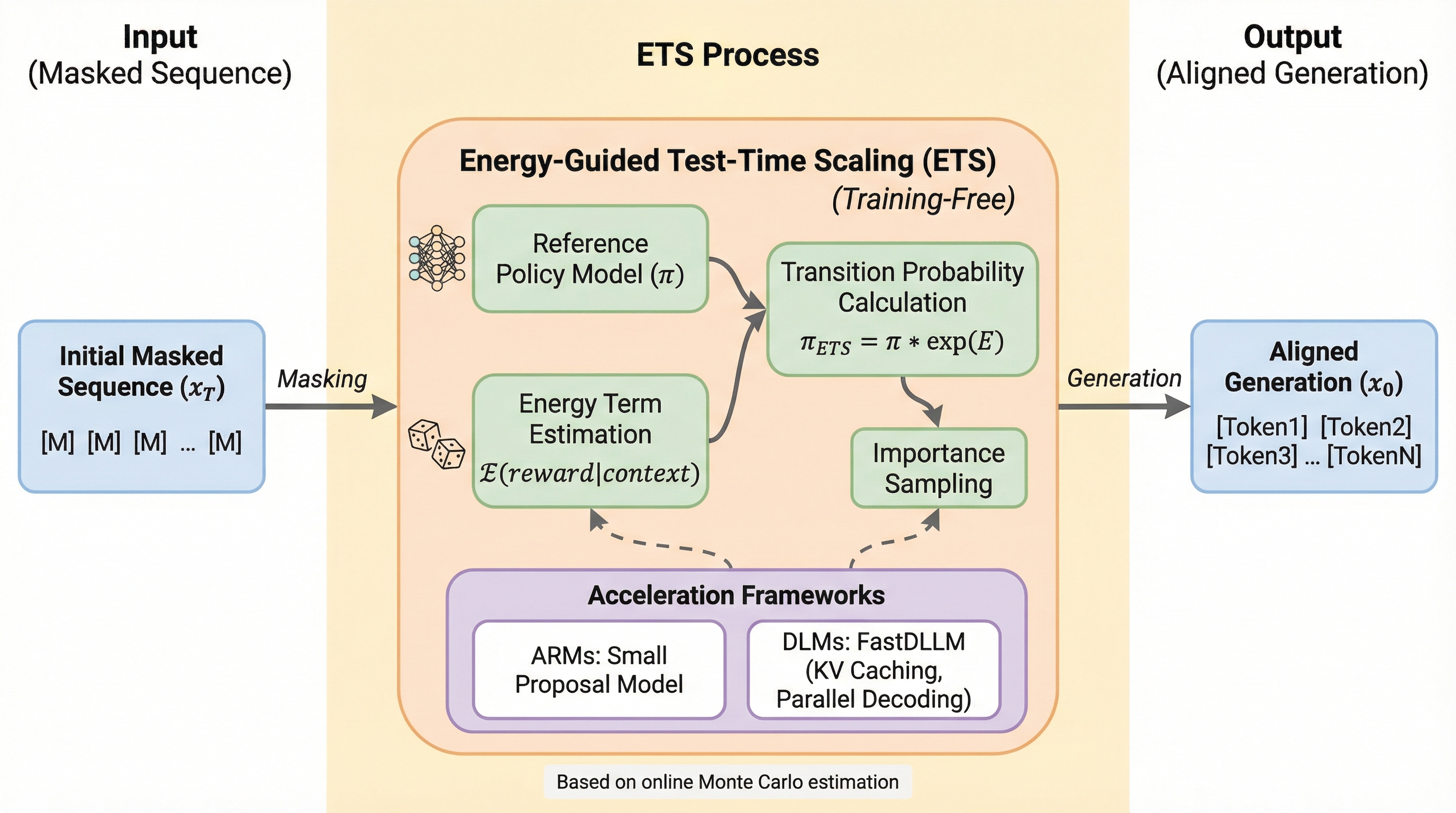
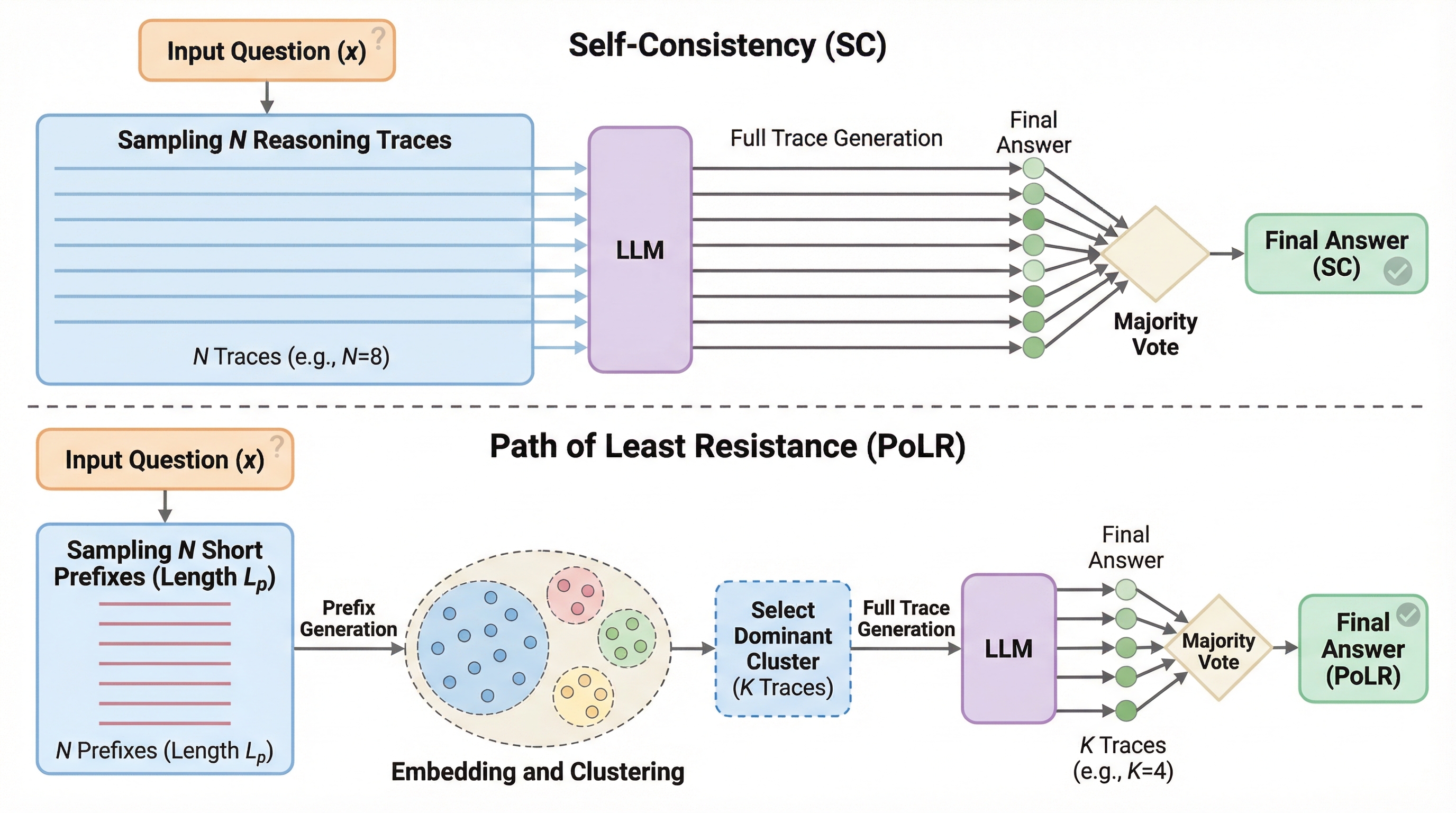
PoLR(Path of Least Resistance)は、大規模言語モデル(LLM)の推論コストを劇的に削減するために開発された、推論時に適用可能な新しいアルゴリズムである。従来のSelf-Consistency(SC)がすべての推論経路を最後まで生成して計算資源を浪費するのに対し、本手法は初期の短い断片(プレフィックス)を生成した段階でクラスタリングを行い、最も有力なグループのみを拡張することで無駄な計算を排除する。 数学や科学などの多様なベンチマークにおいて、SCと同等以上の精度を維持しながら、トークン使用量を最大60%、実行時間を最大50%削減することに成功しており、モデルの追加学習を必要としないドロップイン型の代替案として極めて高い実用性を持つ。 理論的な分析により、推論の初期段階には最終的な正解を予測するための強い信号が含まれていることが示されており、この「プレフィックスの一貫性」を利用することで、効率性と精度の両立を実現している。既存の適応的推論手法とも完全に補完関係にあり、それらと組み合わせることでさらなる計算資源の節約が可能となる。