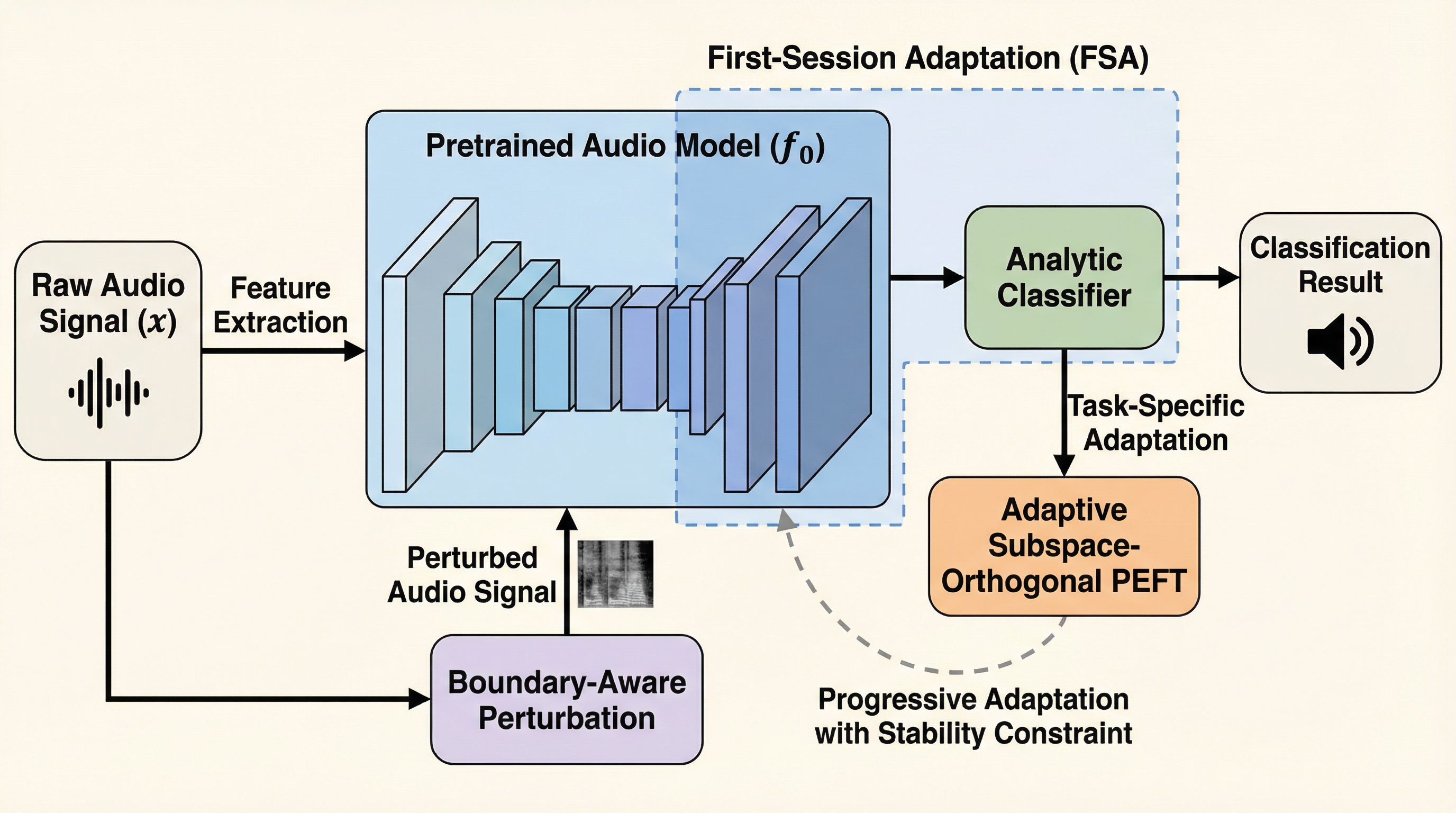
PACE:事前学習済みオーディオ継続学習
音声の事前学習モデルは、画像用モデルとは異なり、構造化された意味情報よりも低レベルなスペクトル情報に強く依存しているため、既存の持続的学習手法を適用するとセッション間で極めて大きな表現シフトが発生し、深刻な破滅的忘却を引き起こすことが本研究の分析によって解明された。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
音声の事前学習モデルは、画像用モデルとは異なり、構造化された意味情報よりも低レベルなスペクトル情報に強く依存しているため、既存の持続的学習手法を適用するとセッション間で極めて大きな表現シフトが発生し、深刻な破滅的忘却を引き起こすことが本研究の分析によって解明された。
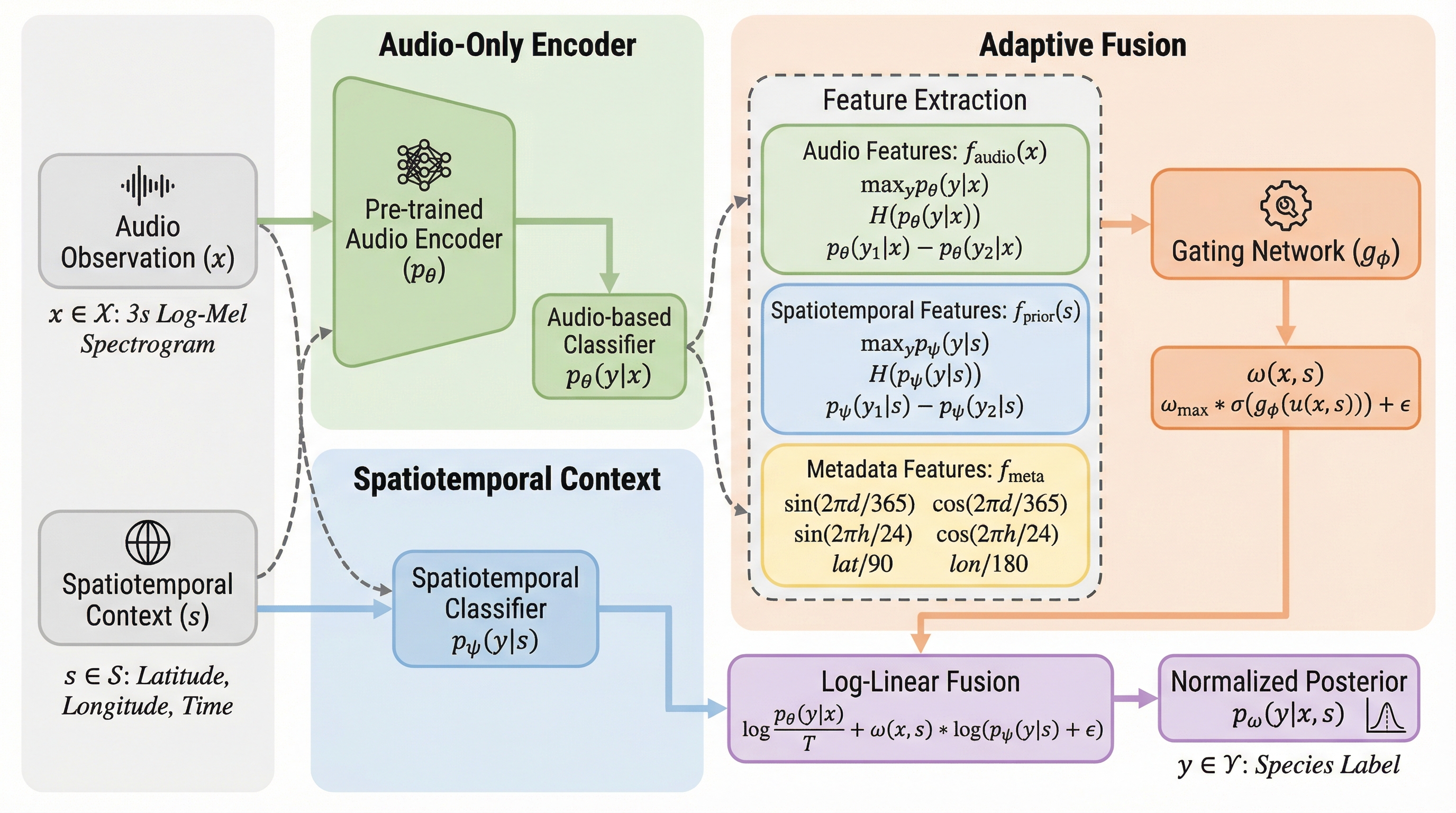
同じ正解にたどり着く手がかりが、複数あるとき——私たちはどう「足し合わせる」のが正解なのでしょうか? 単純に混ぜれば強くなる、とは限りません。状況によっては、弱い手がかりが全体を壊してしまうからです。
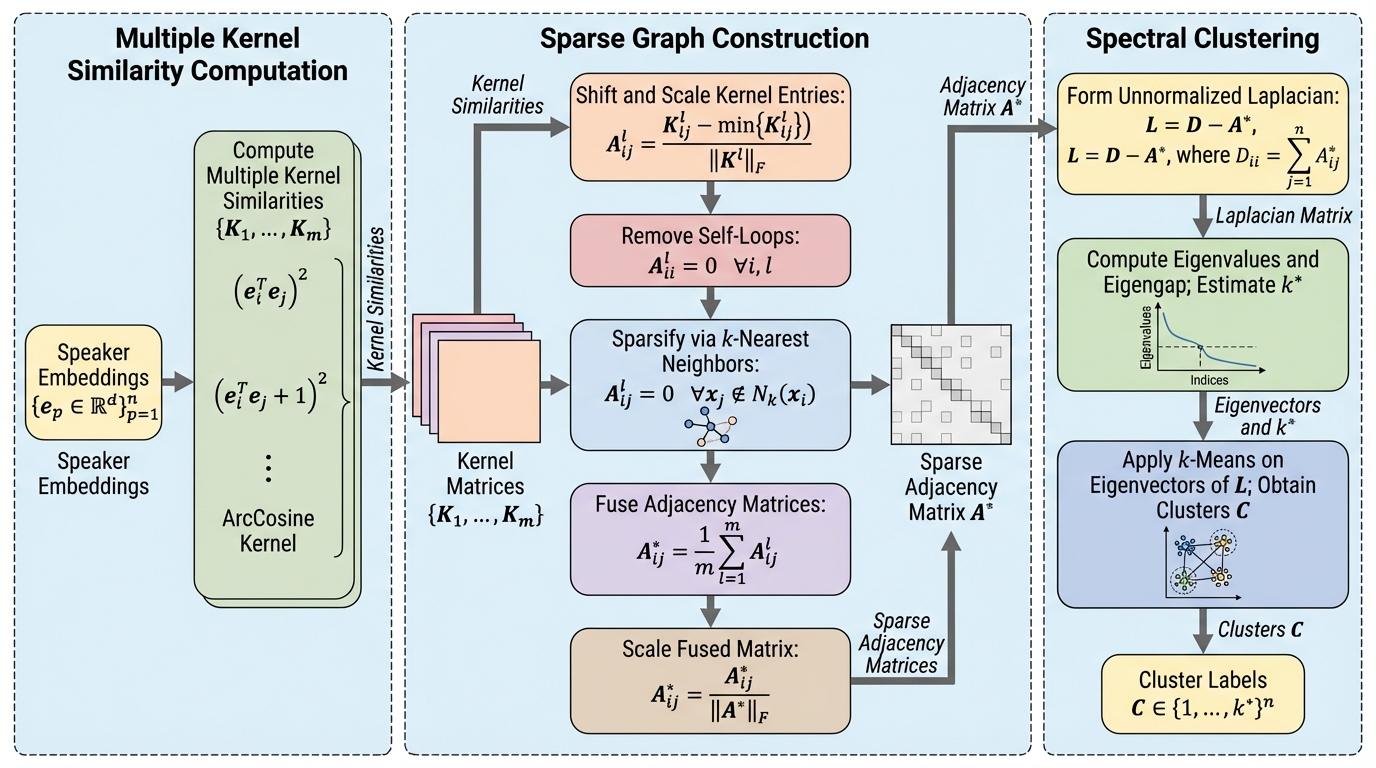
MK-SGC-SCは、4つの多項式カーネルと1つのアークコサインカーネルを統合し、話者埋め込み間の類似性を多角的に評価することで、事前学習や外部の教師情報を一切必要としない完全な教師なし設定において最高水準のダイアリゼーション精度を達成する手法である。
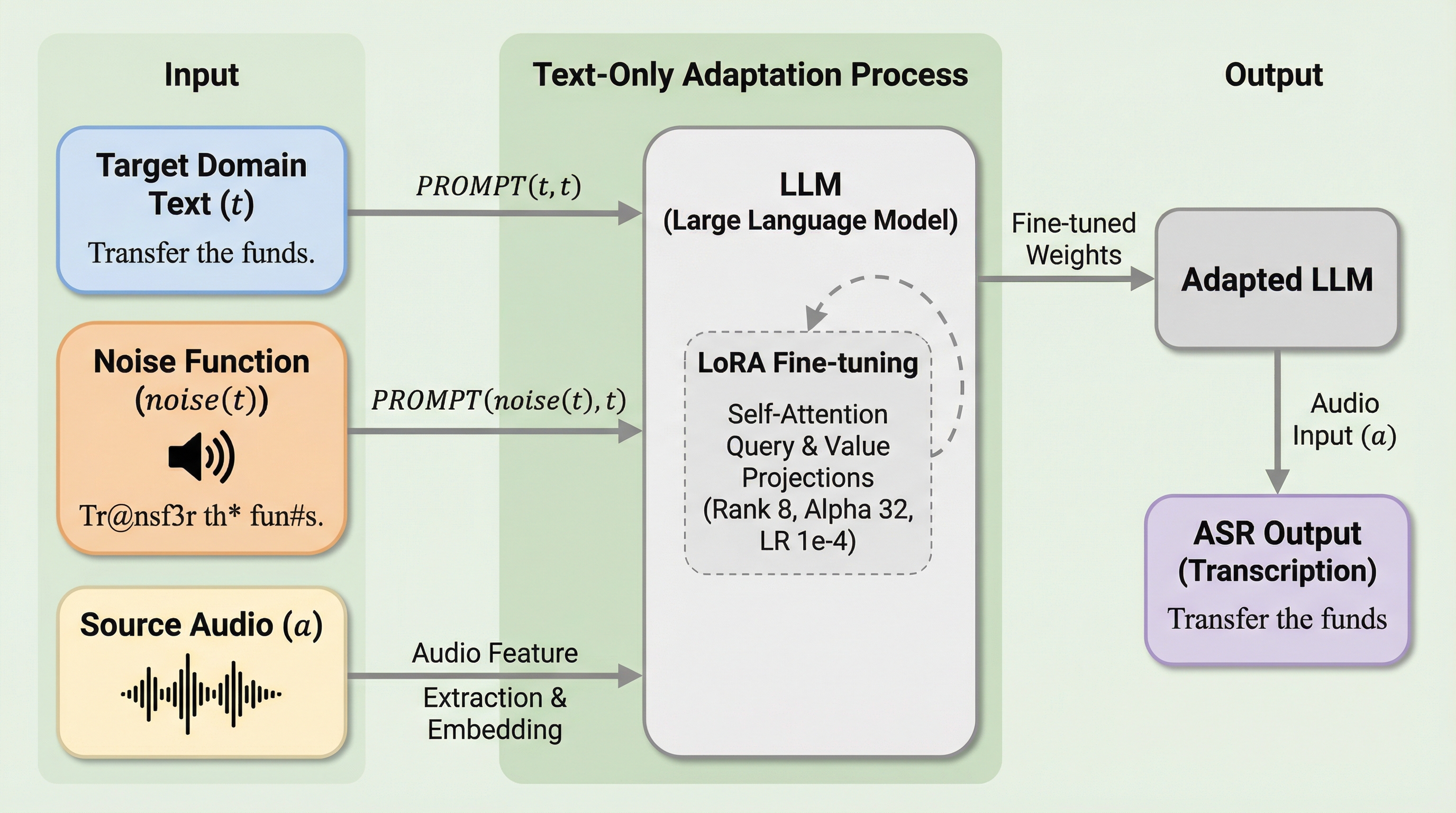
大規模言語モデル(LLM)を活用した音声認識システム(ASR)において、音声とテキストが対になっていないテキストのみのデータを用いて新しいドメインに適応させることは、音声とテキストの整合性を維持する観点から困難な課題であった。
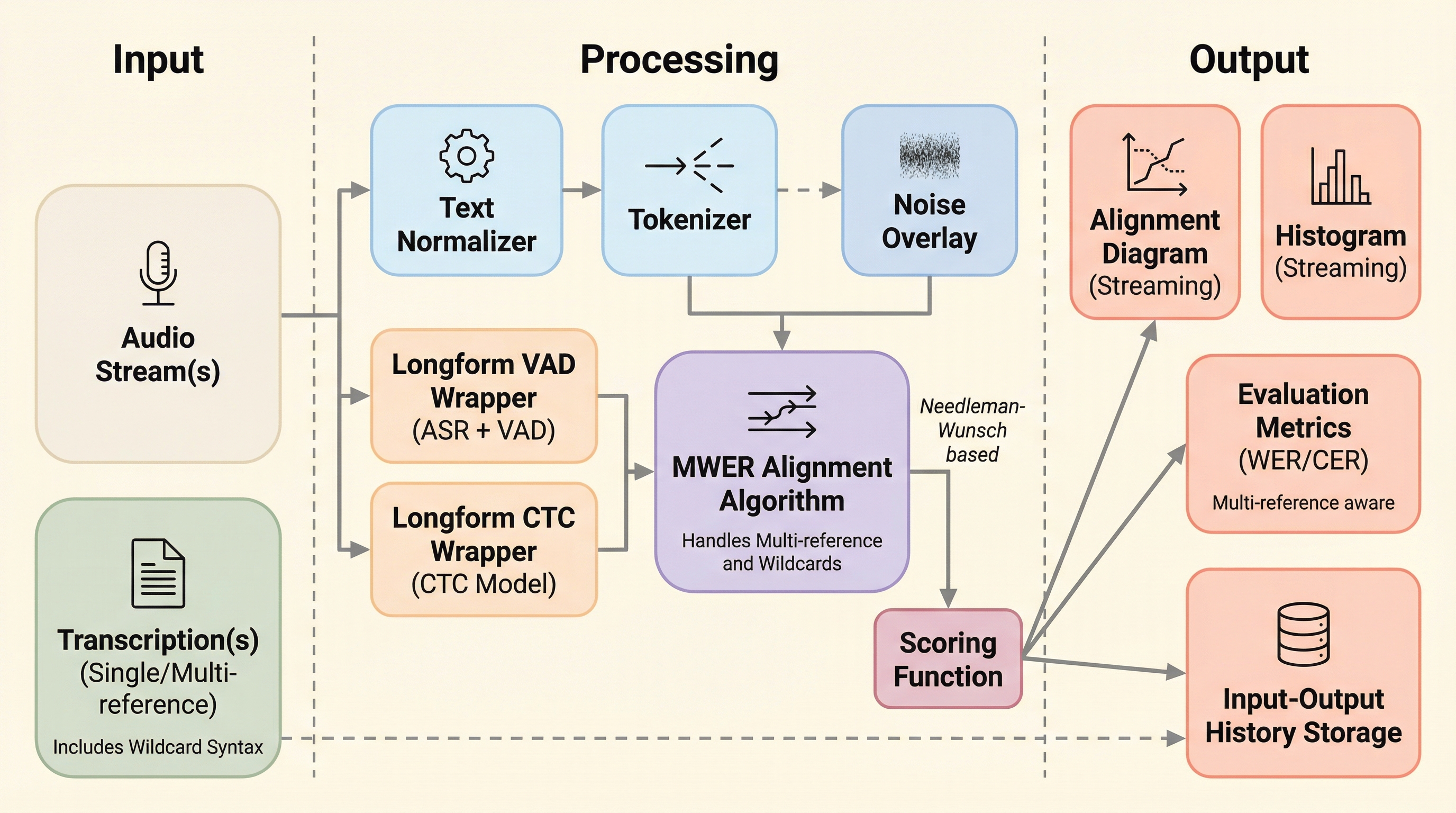
音声認識(ASR)の評価において、表記揺れや聞き取り困難な箇所を柔軟に扱うための新アルゴリズム「MWER」と、包括的な評価ライブラリ「asr_eval」が提案されました。 MWERは、複数の正解候補を波括弧で記述するマルチリファレンス構文、任意の挿入を許容するワイルドカード、ハルシネーションによる指標の歪みを抑える緩和ペナルティを導入し、より人間に近い評価を実現します。 ロシア語の長尺データセットを用いた検証では、従来のテキスト正規化に頼る評価が、モデルが特定の表記規則に過剰適合することで生じる「指標の錯覚」を引き起こし、真の性能向上を誤認させるリスクがあることが示されました。
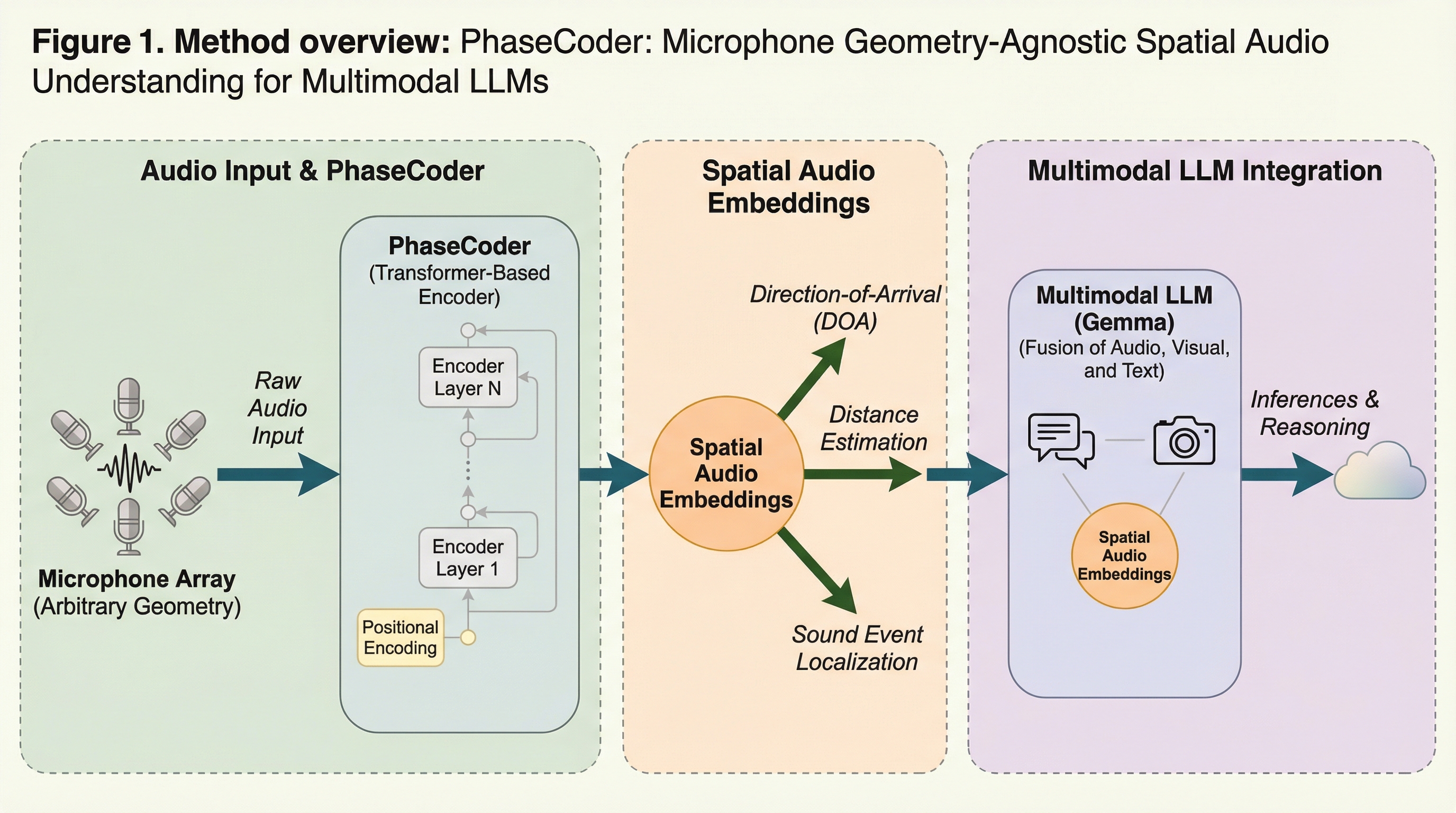
PhaseCoderは、マイクの個数や配置といった幾何学的な条件に依存することなく、多チャンネルの音声データから豊かな空間情報を抽出することが可能な、トランスフォーマーのみで構成された画期的な空間オーディオエンコーダである。
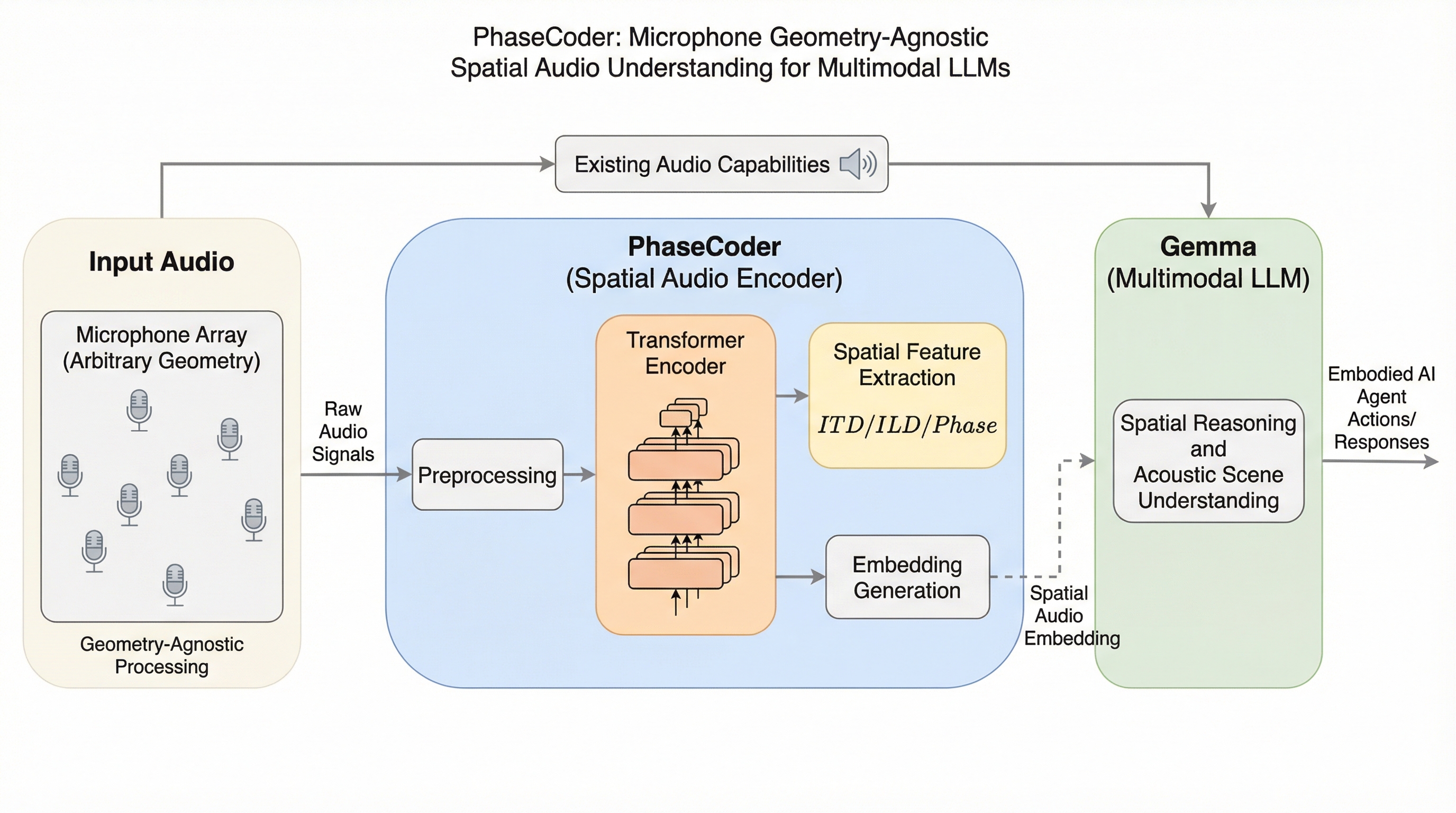
PhaseCoderは、マイクの数や配置に縛られず、多チャンネルの生音声とマイクの3次元座標から直接空間情報を抽出できる、トランスフォーマーのみで構成された革新的な空間オーディオエンコーダーである。
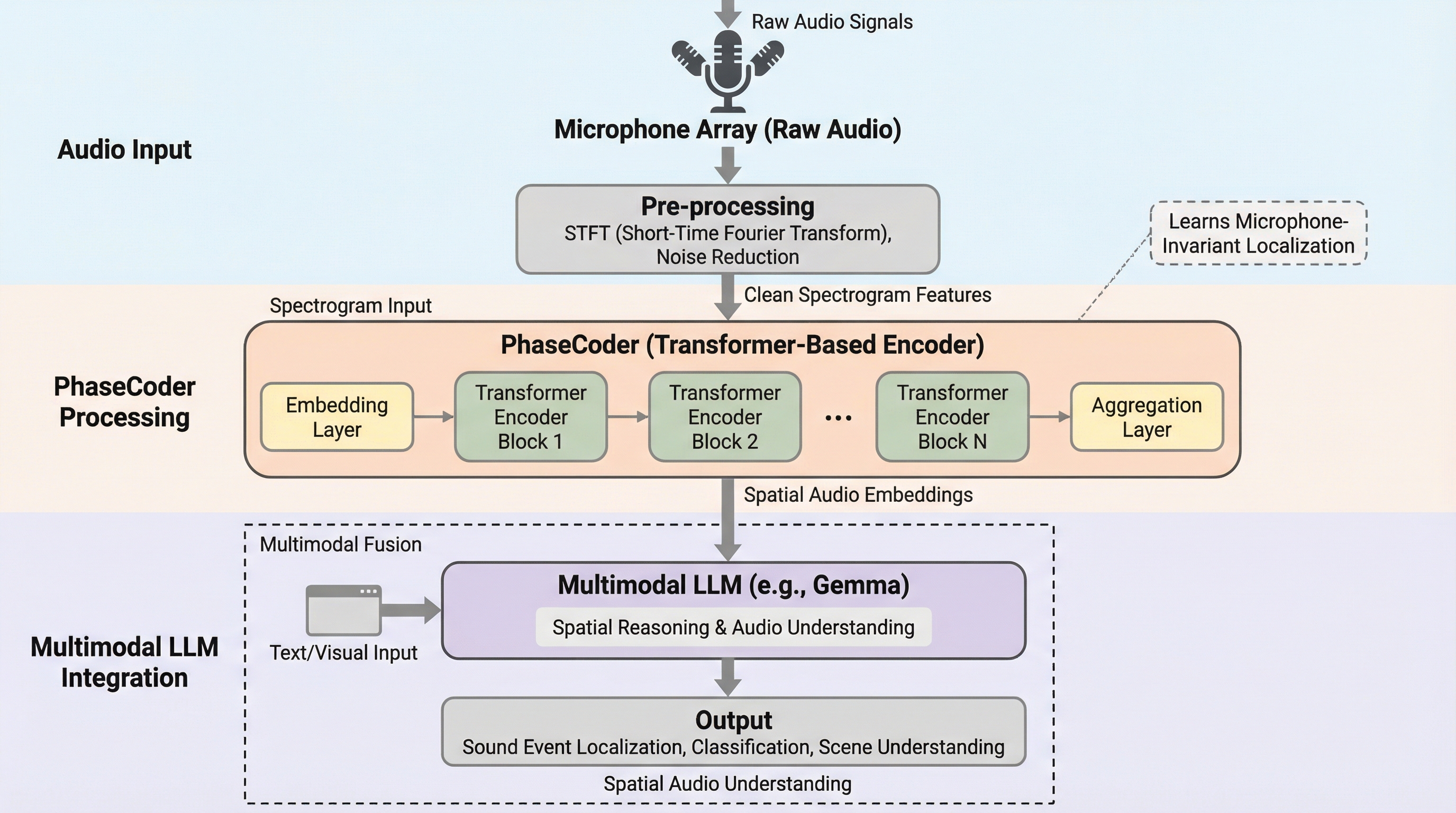
現在のマルチモーダル大規模言語モデル(LLM)は音声をモノラルとして処理しており、音の方向や距離といった空間情報の活用が困難であったが、本研究ではマイクの数や幾何学的配置に依存せず、あらゆるデバイスで利用可能な空間オーディオエンコーダ「PhaseCoder」を提案した。
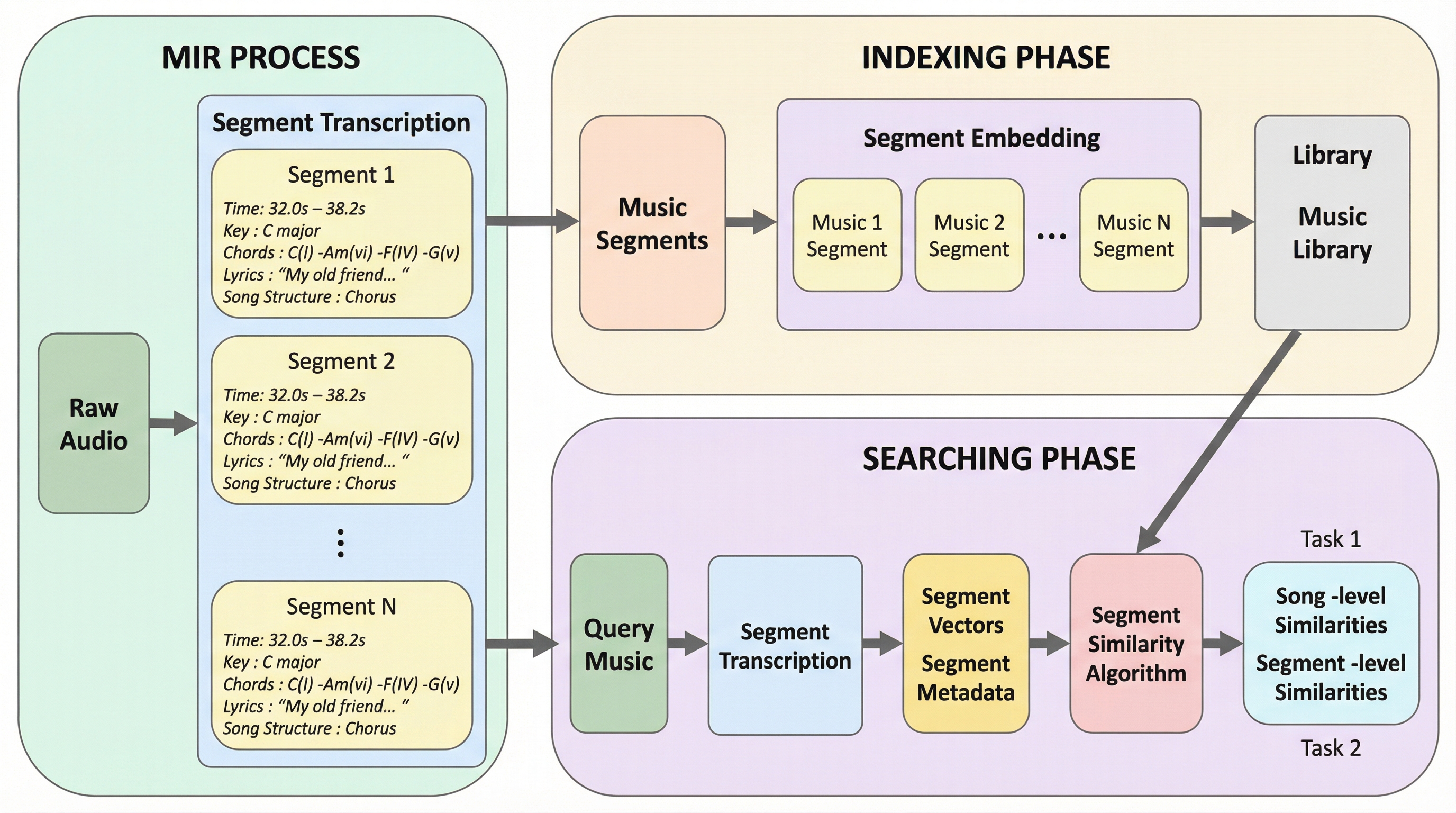
音楽盗作検知を、既存のカバー曲識別やオーディオフィンガープリンティングとは異なる独自の課題として定義し、楽曲全体ではなく部分的な類似性や特定の音楽要素(メロディ、コード、リズム)の模倣を特定する必要性を明確にした。
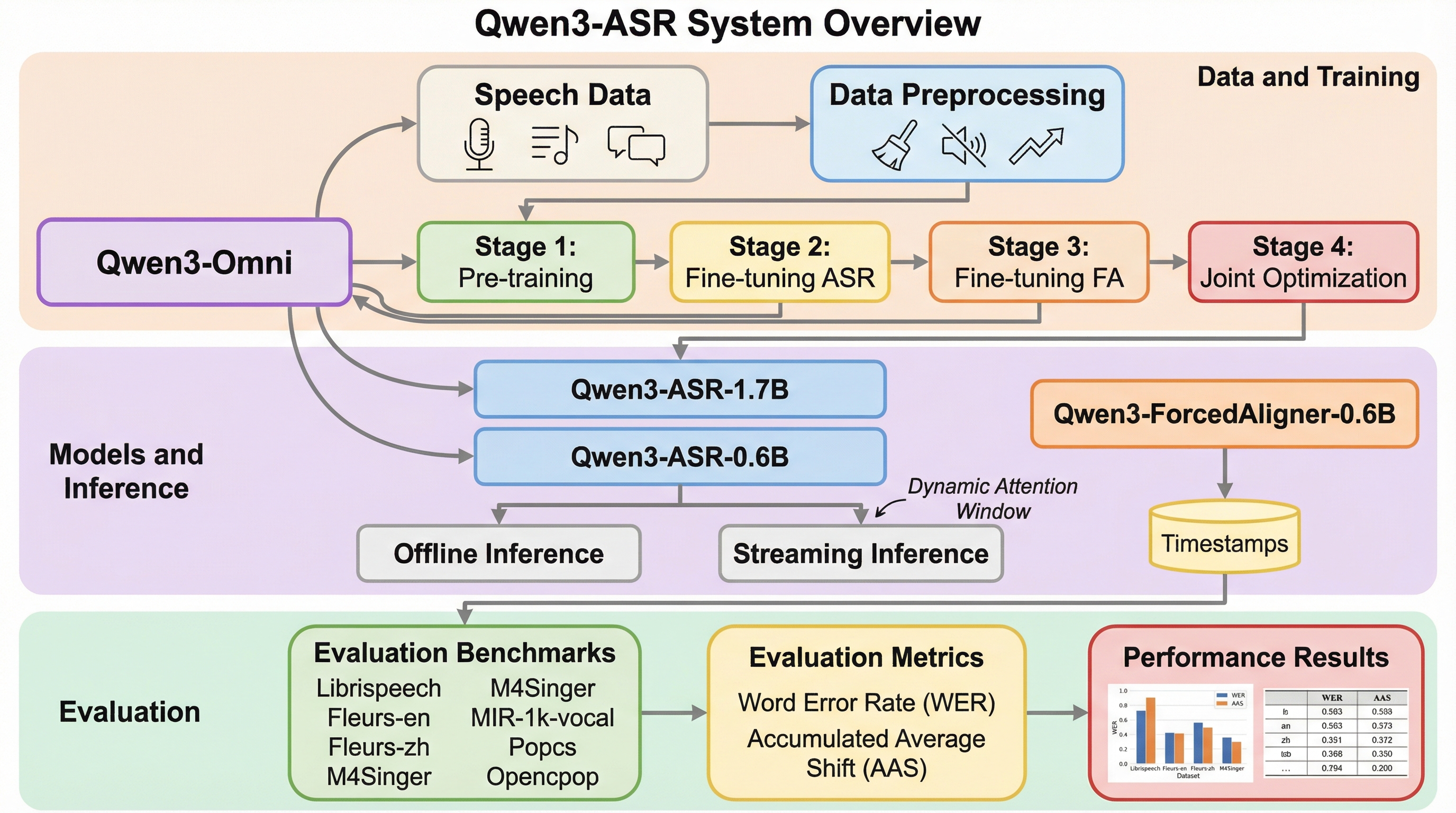
Qwen3-ASRは、52の言語と方言に対応する1.7Bおよび0.6Bの音声認識モデルと、11言語に対応した世界初のLLMベース非自己回帰型強制アライメントモデルで構成される強力な製品群である。