HumanLM:表層の文体模倣ではなく「状態の整合」で本人らしい応答を再現するユーザーシミュレータ
HumanLMは、応答の文体ではなく、信念・目標・価値観・立場・感情・伝え方という潜在状態を整合させることで、より本人らしいユーザーシミュレーションを目指す研究です。
TL;DR(結論)
- HumanLMは、ユーザーらしさを単なる文体模倣ではなく、応答の背後にある潜在状態の整合として学習する枠組みです。論文の中心は、「その人が何を信じ、何を望み、どういう立場と感情で、どのような伝え方をするか」を応答生成の前段で合わせに行く点にあります。
- その潜在状態は自然言語で表現され、信念(belief)・目標(goal)・価値観(value)・立場(stance)・感情(emotion)・伝え方(communication)の6次元で扱われます。著者らはこれを強化学習で整合させ、あわせて Humanual という 6データセット・約2.6万人・約21.6万応答・約6.6万トピックの評価基盤も整備しています。
- 論文では、評価用LLMによる応答整合スコアで既存手法に対して平均16.3%の相対改善を報告し、111人参加のリアルタイム実験でも「本人応答との近さ」の勝率 41.4% と「人間らしさ」の両面で最上位だったとしています。要するに、返答の表面ではなく、その返答を支える状態をそろえる方が本人らしさに効く、という主張です。
なぜこの問題か
ユーザーシミュレーションは、政策案への反応予測、記事や製品のフィードバック収集、対話エージェントの評価など、さまざまな場面で期待されています。しかし従来のやり方は、過去発話の言葉遣い、絵文字の使い方、文体の癖といった表層パターンをなぞる方向に寄りがちでした。これだと、一見それらしい文章は作れても、実際にその人がその話題にどういう立場をとり、何に怒り、何に共感するのかという中身の側面がずれやすくなります。
論文が問題にしているのは、まさにこの「口調は似ているのに、反応の芯が違う」というズレです。たとえば同じ否定的反応でも、皮肉なのか、直接的な批判なのか、被害者への共感なのか、政策への苛立ちなのかで、応答の意味はかなり変わります。表面だけ模倣する学習では、こうした高次の状態を取り逃しやすく、未知の文脈に出たときに本物のユーザー行動から外れやすい、というのが著者らの出発点です。
著者らが問題にしているのは、まさにこのズレが下流の評価やシミュレーション品質を崩す点です。ユーザーシミュレータが表層だけを再現しても、実際の立場や感情や伝え方が外れていれば、生成された応答はそれらしく見えても本人の反応としては不正確になります。したがって本研究は、単なる文体改善ではなく、ユーザー応答の再現精度をどこで支えるかという基礎設計を扱っていると整理できます。
核心:何を提案したのか
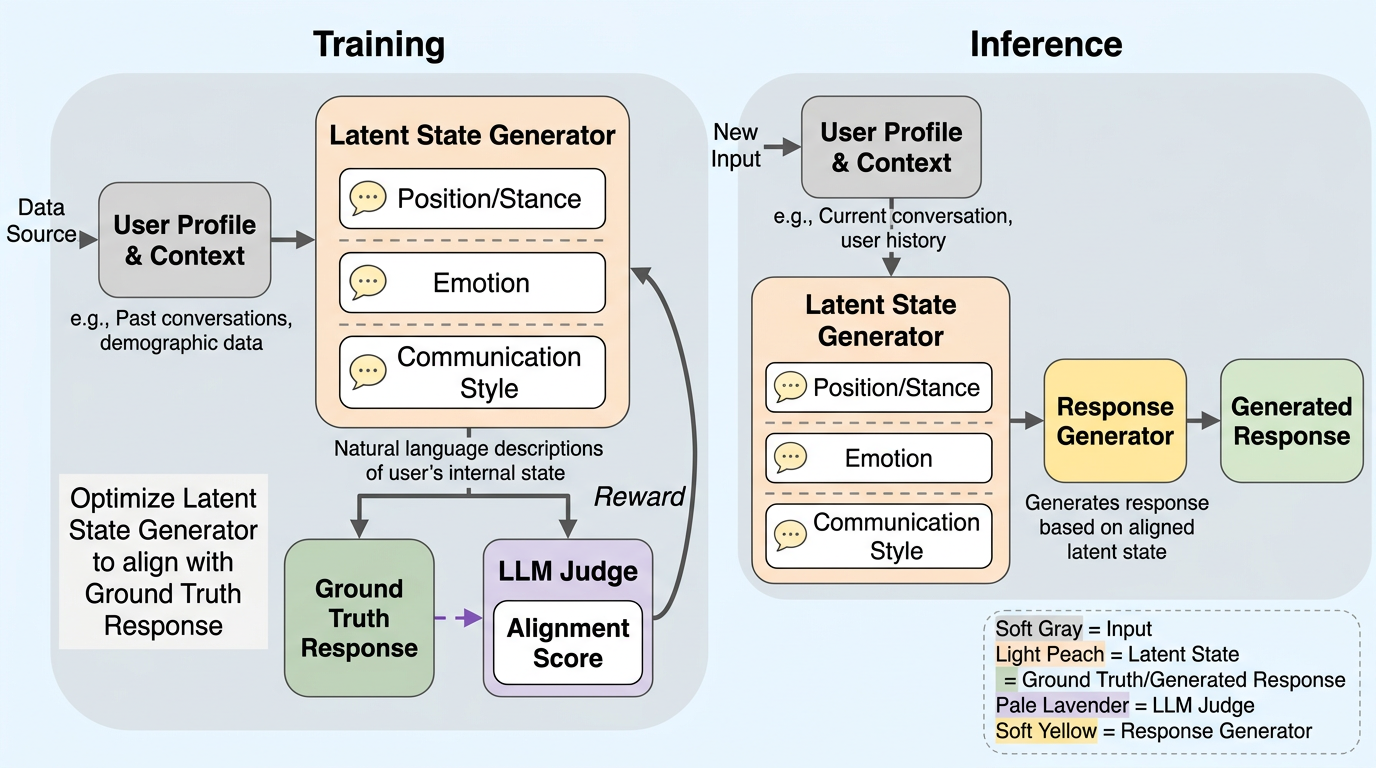
この論文の提案は、ユーザー応答を直接まねるのではなく、その応答を生み出す潜在状態をまず整合させる、という学習フレームワーク HumanLM です。ここでいう潜在状態は、信念・目標・価値観・立場・感情・伝え方の6次元で整理されています。論文中の例では、政策に反対している、被災者に強い共感を持っている、苛立ちを含んだ皮肉で話している、といった状態が具体例として示されています。
著者らの主張は、本人らしい応答を再現したいなら、最終文面だけ合わせても不十分であり、「その人がその場面でどう感じ、どの軸で反応するか」をモデル内部の推論過程に載せる必要がある、というものです。そこで HumanLM は、入力された文脈とユーザープロファイルから、複数の状態次元ごとの自然言語による潜在状態を生成し、それが正解応答と整合しているかを学習信号として使います。応答はその後段で、整合した潜在状態を踏まえて生成されます。
ここで面白いのは、潜在状態を単なる隠れベクトルではなく、自然言語として扱っている点です。これにより、モデルが「何を考えてその応答に至ったのか」を、人間がある程度解釈可能な形で中間表現に持ち込めます。つまり HumanLM は、ユーザーシミュレーションをブラックボックスな模倣問題としてではなく、状態整合という説明可能な学習課題に組み替えようとしているわけです。
仕組み:どう動くのか
論文の構成を素直に読むと、HumanLM の流れは四段です。第一に、ユーザープロファイルと文脈を入力し、6つの状態次元ごとに潜在状態を自然言語で表現します。第二に、それらの潜在状態が実際の正解応答とどれだけ整合しているかを、評価用LLMを使って比較評価します。第三に、その整合スコアを報酬として GRPO による強化学習を回し、モデルが表層模倣ではなく高次状態の整合を優先するように訓練します。第四に、推論時には整合した潜在状態を推論過程の中で生成し、それをもとに最終応答を生成します。
論文では、単純な教師あり学習との違いも明示されています。教師あり学習では、過去データで絵文字や言い回しの頻度が高ければ、そこを強く真似る方向に寄りやすくなります。一方 HumanLM では、応答の前段にある状態の一致をまず学ばせるため、未知の文脈でも「このユーザーなら何に反応するか」を保ちやすい、という整理です。強化学習アルゴリズムとしては GRPO を使い、複数の潜在状態候補をまとめて比較評価する設計も説明されています。
この設計の実務的な意味は、生成品質を「文章が似ているか」だけで測らない点にあります。仮に表現が少し違っても、立場、感情、話し方の軸が合っていれば、その応答は依然として本人らしい可能性があります。逆に、言い回しだけ似ていても、賛否や感情の向きがずれていれば、シミュレーションとしては失敗です。HumanLM はこのズレを潜在状態という中間表現で切り出し、応答生成の前に整合させることで、評価軸そのものを一段深く置き直しています。
検証:どう確かめたのか
評価基盤として著者らは Humanual というベンチマークを新たに用意しています。これは公開データに基づく 6 つの大規模データセットから成り、約 2.6 万人のユーザー、約 21.6 万件の応答、約 6.6 万のトピックを含むとされています。対象タスクも、日常生活上の相談への反応、政治ブログへの反応、LLM アシスタントとのチャットなど複数にまたがっており、単一ドメインに閉じた評価ではない点が重要です。
さらに、オフライン評価だけでなく、111 人を対象にしたリアルタイム実験も行っています。参加者はランダムに選ばれた投稿に自分で応答したうえで、3種類のユーザーシミュレータが出した応答を比較し、どれが自分の応答に近いか、人間らしいかを採点します。また論文では、訓練時の評価モデルに gpt-5-mini、ベンチマーク評価時の評価モデルに claude-4.5-haiku を使い分け、追加の信頼性確認として gemini-3-pro でも順位の一貫性を確かめています。
したがって本論文は、大規模ベンチマーク、自動評価、本人参加のリアルタイム比較を組み合わせて、「整合スコアが高いだけでなく、本人から見ても近いか」を多面的に確かめる構成を採っています。加えて、訓練時と評価時で評価モデルを分けている点も、評価の循環性を抑える工夫として重要です。
また、論文は状態次元そのものも自然言語で出力させるため、最終応答だけでなく「どの状態推定を経てその返答になったか」を追いやすい構成になっています。これは単なる性能比較にとどまらず、ユーザーシミュレーションの失敗原因を後から点検しやすくする設計として読むことができます。
結果:何が変わったのか
論文が前面に出している結果は、HumanLM が既存のプロンプト設計、教師あり学習、従来の強化学習ベース手法よりも高い整合性を示した点です。具体的には、6データセット全体で、評価用LLMによる応答整合スコアにおいて最良ベースラインに対して平均 16.3% の相対改善を達成したと報告しています。ここで言いたいのは、少し文が自然になったというより、「正解応答が含んでいる意味上の芯」に近づいたという評価軸で差が出た、ということです。
リアルタイム実験でも、HumanLM は「本人応答との近さ」の勝率が 41.4% と最も高く、人間らしさの評価でも最上位でした。論文中では、76.6% の応答が「かなり自然」相当以上と報告されており、本人評価の面でも有利だったと整理されています。要するに、潜在状態を合わせる設計は、評価器から見ても本人から見ても、表層模倣より有利に働いた、というのが著者らの結論です。
もう一つ重要なのは、改善が単一タスクではなく、ニュース・書籍・意見・政治・チャット・メールという異なる6領域をまたいで確認されている点です。もし特定データセットだけで勝っているなら、単なるドメイン適応の可能性も残ります。しかし本論文は、複数の場面で一貫して「状態を合わせる学習」の優位を示そうとしており、この発想が単発のベンチマーク更新ではなく、より一般的な設計原理として意味を持つ可能性を示しています。
同時に、この結果は「本人らしさ」を完全一致ではなく、意味の近さと反応軸の一致で測るべきだという示唆にもなっています。実際の人間は同じ質問に毎回まったく同じ言い回しで返すわけではありません。にもかかわらず、その人の立場や感情の向きが保たれていれば、私たちはその応答を依然として「その人らしい」と感じます。HumanLM の改善は、この直感を評価設計の中に持ち込んだ結果として読むこともできます。
限界:どこまで言えるか
もっとも、この論文が示しているのは「公開データから再構成できるユーザープロファイルと応答履歴がある場合」における有効性です。現実には、十分な過去データがないユーザー、文脈依存性が極端に高いユーザー、あるいは一貫した人格を持たない応答履歴もあり得ます。その場合でも同じように機能するかは、この論文だけでは断定できません。また、潜在状態自体は自然言語で表現されるため、状態次元の切り方や評価モデルの採点基準に依存する余地も残ります。
加えて、本人らしさを精密に再現する技術は、評価や研究だけでなく、説得や操作の方向にも転用可能です。論文は主に性能改善を扱っていますが、社会的な利用境界やガードレール設計は別途必要です。したがって本研究は、ユーザーシミュレーションの精度向上としては強い前進ですが、そのまま万能の「人間再現器」と受け取るより、状態整合という学習原理が有効だったことを示す成果として読むのが妥当です。
また、評価用LLM を報酬源として強く使う以上、評価モデルの価値観や採点傾向が学習結果に混入する可能性もあります。本人評価で補っているとはいえ、最終的に「誰が似ていると判定するのか」という問題は残ります。今後は、異なる評価設計や、より多様な実ユーザー実験で結果がどこまで安定するのかを見ないと、完全な一般化は言いにくいでしょう。したがって、この論文の主張は強いものの、ユーザーシミュレーションの最終解と見るより、有望な学習方針として受け止めるのが安全です。
もう一つの限界は、潜在状態を自然言語で明示する方式が、解釈しやすい反面、記述粒度の選び方に影響されることです。状態を粗く切れば多様な応答差を吸収しきれず、細かく切りすぎれば評価と学習が不安定になります。論文はこの方向性の有効性を示していますが、どの状態次元を標準にすべきか、どこまで文化圏やタスクをまたいで再利用できるかは、今後の整理が必要です。つまり HumanLM は完成形というより、「人らしさを何で表すか」という設計論を一歩前に進めた研究だと言えます。
実務の観点では、こうしたユーザーシミュレータをそのまま意思決定の代行に使うべきではない点も明確です。最も向いているのは、仮説生成、事前検証、失敗しそうな対話パターンの洗い出しといった補助用途です。つまり HumanLM は「この人は絶対こう答える」と断定する装置ではなく、「表層模倣だけでは外しやすい反応の軸」を事前に可視化するためのモデルとして扱う方が現実的です。
逆に言えば、この論文の価値は、ユーザー理解を単なる履歴圧縮ではなく、状態表現の設計問題として再定義した点にあります。今後もし別のデータセットや別分野で同じ発想が再現されれば、パーソナライズ対話、教育支援、製品テスト、政策コミュニケーション評価など、応答の背後にある意図を重視する領域に波及する余地があります。そう考えると、本研究は単発のベンチマーク改善より、「人らしさ」をどうモデルに持ち込むかという長い課題に対する整理として見る価値があります。
持ち帰り
第一に、ユーザーシミュレーションでは「どんな言葉を使う人か」だけでなく、「何に賛成し、何に腹を立て、どう伝える人か」を明示的に扱う方が強い、という点です。これはユーザーモデリングの重心を、文体模倣から心理状態の整合へずらす提案だと理解できます。
第二に、応答そのものではなく、応答を支える潜在状態に報酬を与える設計は、未知文脈への一般化を改善する可能性があります。表面の言い回しは変わっても、反応の軸が保たれていれば、本人らしさは維持されやすいという考え方です。特にユーザーシミュレーションのように「完全一致」が本質でない課題では、この考え方はかなり相性が良いと見えます。
第三に、Humanual のような大規模・多領域の評価基盤を併せて出している点も重要です。ユーザーシミュレータは用途が広いぶん、都合のよい例だけでは評価しにくいため、複数ドメインと本人評価を含めて比較したこと自体が、この研究の価値の一部になっています。モデル本体だけでなく、評価方法まで含めて前に進めた論文として見るのがよいです。
Related