LLM推論失敗の全体像:何が壊れ、どこが脆く、どう直すべきかを整理する包括サーベイ
この論文は、LLM の推論失敗を「身体性を伴う推論 / 非身体的推論」と「根本的失敗 / 領域固有の限界 / 頑健性の問題」の二軸で整理する包括サーベイです。
TL;DR(結論)
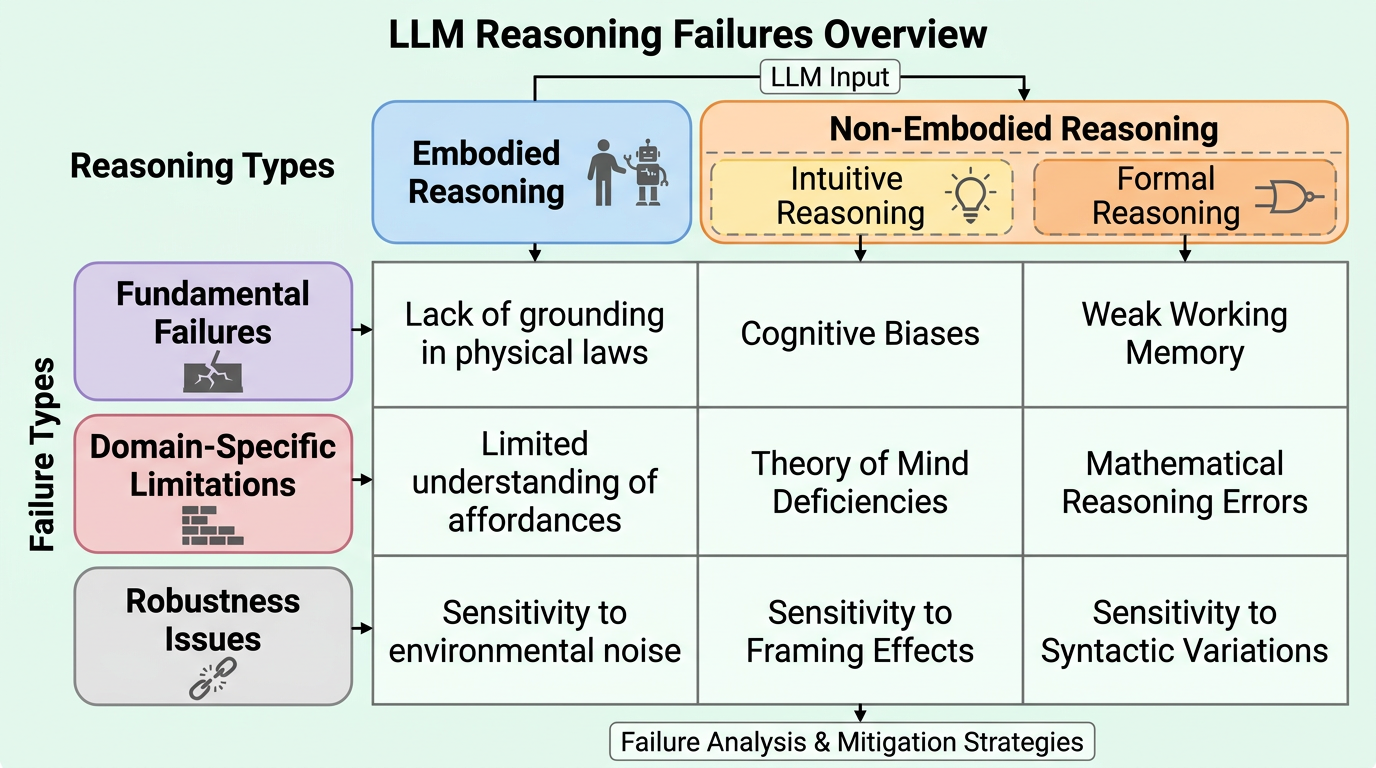
- この論文は、新しい推論モデルや新ベンチマークを出す研究ではなく、LLM の推論失敗を体系的に整理するための包括サーベイです。核心は、推論を「身体性を伴う推論(embodied)」と「非身体的推論(non-embodied)」に分け、さらに後者を「直観的推論(informal)」と「論理的推論(formal)」に分ける軸と、失敗を「根本的失敗」「領域固有の限界」「頑健性の問題」に分ける軸を組み合わせた地図を与えた点にあります。
- 重要なのは、推論失敗を「単に性能が低い」で終わらせず、どの種類の推論で、どの種類の壊れ方をしているのかを分けて考えるべきだと示したところです。認知バイアスのような根深い失敗、数学やコードのような領域依存の失敗、表現の微小変更で結果が崩れる頑健性の失敗を同列に扱わない、という立場です。
- したがってこの論文の価値は、LLM が推論できるかどうかを一問一答で測るのではなく、どこで失敗し、なぜ失敗し、何を直すべきかを研究者が共通言語で議論できるようにしたことにあります。論文本体に加えて、関連研究を集約した GitHub リポジトリを公開している点も実務的に有用です。
なぜこの問題か
LLM の推論能力はここ数年で大きく前進し、数学、コード、科学タスク、長い思考過程の記述を要する問題などで目覚ましい結果が報告されています。しかし同時に、少し見方を変えると不自然なミスをしたり、単純な表現変更で答えが崩れたり、日常的な推論では人間なら避ける失敗をしたりする場面も繰り返し観測されています。つまり現在の LLM は「推論できる/できない」の二値で捉えるには粗すぎる存在になっており、強さと脆さが併存しています。
著者らが問題にしているのは、この失敗研究が断片化している点です。ある論文は論理推論だけを見る、別の論文は数学推論だけを見る、別の論文は社会的推論や物理推論だけを見る、という形で知見が散らばっており、失敗の共通構造が見えにくい状況です。これでは、どの失敗がアーキテクチャに深く根ざすのか、どの失敗が特定領域に依存するのか、どの失敗が単に評価設計の甘さから見逃されていたのかを横断的に整理しにくくなります。
さらに厄介なのは、推論失敗には二種類の見え方があることです。一つは誰が見ても明らかな失敗で、モデルが露骨に誤るケースです。もう一つは、一見うまくできているように見えるのに、入力のわずかな変化や条件の違いで急に崩れるケースです。後者はベンチマークの平均スコアだけでは見えにくく、運用現場ではむしろ危険です。この論文は、そうした「隠れた脆さ」まで含めて地図化しようとしている点に意味があります。
核心:何を提案したのか
この論文の中心提案は、LLM の推論失敗を整理するための二軸の分類枠組みです。第一軸は推論の種類で、身体性を伴う推論と非身体的推論を分け、後者をさらに直観的推論と論理的推論に分けます。直観的推論は、日常的な判断、直感、社会的文脈、暗黙の了解など、人間が普段あまり形式化せずに行う推論を含みます。論理的推論は、論理、数学、コード、記号操作のように、より明示的なルールに依拠する推論です。身体性を伴う推論は、物理世界との相互作用や空間認識、動的環境での振る舞いなど、身体性や環境フィードバックを前提とする推論です。
第二軸は失敗の種類で、根本的失敗、領域固有の限界、頑健性の問題に分けます。根本的失敗は、LLM の構造や学習様式に深く関わり、さまざまな下流タスクに広く影響しうる失敗です。領域固有の限界は、数学、社会推論、物理推論など、特定領域で顕在化する失敗です。頑健性の問題は、入力表現の小さな差、条件変更、視点変更などに対して結果が不安定になるタイプの失敗です。
この二軸が重要なのは、同じ「誤答」でも性質が全く違うと分かるからです。たとえば数式変形で壊れるのは論理的推論における領域固有の限界かもしれませんし、否定語や文順の少しの変化で答えが崩れるなら頑健性の問題に近いかもしれません。逆に、ワーキングメモリや抑制制御の弱さのように、人間の基礎認知機能に相当する弱点なら根本的失敗として見る方が筋が通ります。この整理があることで、研究者は「どこを直すべき失敗か」を混同しにくくなります。
仕組み:どう動くのか
論文はまず直観的推論の失敗を、人間の認知や社会性に近い側面から整理します。個体レベルの認知推論では、ワーキングメモリ、抑制制御、認知柔軟性の不足、あるいは人間に似たバイアスの模倣といった問題が扱われます。社会的推論では、心の理論(ToM)、社会規範、道徳、複数エージェント間の相互作用など、他者や社会文脈を踏まえた推論での失敗が整理されます。ここでのポイントは、LLM が単に事実を知らないのではなく、社会的前提や暗黙のルールをうまく扱えないことで誤るケースを独立した失敗として見ることです。
次に論理的推論では、自然言語上の論理関係、ベンチマーク上の論理推論、算術・数理、コードなどが扱われます。論文は、論理や数学は「推論能力」を測る代表格に見えがちだが、実際には逆転問題、合成的推論、数え上げ、基礎算術、数式処理、数学文章題、コーディングのように細かく失敗形態が分かれると示します。たとえば個別には解ける要素問題を、二段三段と組み合わせると急に崩れるケースや、訓練データ中の文を逆向きに問われるだけで対称性を保てないケースは、単なる「数学が弱い」では片付けにくい失敗です。つまり論理的推論と一口に言っても、どこで破綻するかはかなり違うという整理です。
身体性を伴う推論の章では、一次元・二次元・三次元の物理・空間推論、画像内の異常検出、物理常識、アフォーダンス、計画、ツール使用、長期自律性などが扱われます。ここで重要なのは、テキストだけの論理推論で高得点でも、現実世界の制約や空間的整合性を伴うタスクでは別の弱点が出ることです。論文は、画像の中で「何がおかしいか」を見抜く課題、二次元・三次元の空間配置、物体の使い方を踏まえた計画、安全を保ちながら長く行動を続ける自律タスクまでを並べ、推論能力を一つのスコアで語る危うさを見える形にしています。
論文の実務的な価値は、各失敗について「定義 → 代表研究 → 根本原因 → 緩和策」の流れで並べている点です。つまり「こういう壊れ方がある」という観察だけでなく、それがなぜ起きるのか、どう緩和しようとしているのかまで一枚の見取り図にしてあります。さらに、関連研究をまとめた GitHub リポジトリも公開し、継続更新の入口として機能させています。単に文献を列挙するのではなく、失敗例を読んだあとに「これは根本的失敗か、領域固有の限界か、それとも頑健性の問題か」を辿れる構成になっているため、後続研究の整理台として使いやすいです。
検証:どう確かめたのか
この論文はサーベイなので、新たな単一実験で最高性能を示すタイプではありません。代わりに、既存研究を横断して共通パターンを抜き出し、「どの失敗がどの箱に入るか」を整理すること自体が検証に相当します。言い換えると、ここで示されているのは新モデルの性能ではなく、失敗研究を読むための座標系です。
その座標系は図1に凝縮されています。行方向に推論カテゴリ、列方向に失敗カテゴリを置き、その交点ごとに代表的な失敗トピックを配置しています。直観的推論には個体認知、暗黙的社会推論、明示的社会推論があり、論理的推論には自然言語論理、論理ベンチ、算術・数学があり、身体性を伴う推論には一次元・二次元・三次元の物理・空間・行動系課題が並びます。この構成により、研究者は「自分が見ている失敗が全体のどこに位置するか」を把握しやすくなります。
また論文は、失敗を「明確な性能低下」と「見かけ上はできているが不安定」の両方として捉えている点でも重要です。前者だけを見ていると、露骨な失敗には気づけても、少しの条件差で壊れるモデルを見逃します。後者まで含めることで、LLM の推論評価は平均スコア競争では不十分であり、入力揺らぎや条件変化への頑健性確認が必要だという方向性が明確になります。
結果:何が変わったのか
この論文が示している最も大きな結論は、LLM の推論失敗を単一の弱点としてではなく、推論の種類と失敗の種類の交点で整理すべきだということです。根本的失敗、特定領域の限界、頑健性の問題は別々に扱う必要があり、同じ誤答でも原因と対処法が異なります。著者らは、その違いを一つの地図の上で見渡せるようにした点にこのサーベイの意義を置いています。
もう一つ重要なのは、失敗研究の一部が人間認知の概念と接続して読める一方で、この論文の主眼は「LLM が本当に人間のように考えているのか」を決着させることではない、という点です。著者らは、観測されている失敗を共通の座標系で整理し、原因分析や緩和策の議論につなげることに重心を置いています。したがって本論文は、推論の哲学的定義を争うよりも、失敗研究を比較可能にする土台を整える仕事として読むのが自然です。
さらに、このサーベイは頑健性の問題を独立した失敗カテゴリとして前面に出している点が効いています。多くの議論は誤答率や精度の平均で終わりがちですが、実運用ではわずかな言い換え、表記ゆれ、視点変更、不要情報の混入で崩れるかどうかが致命的です。論文はこの脆さを「副次的なノイズ」ではなく、推論失敗そのものとして扱うべきだと位置付けています。
この整理により、研究者は数理推論の失敗、社会的推論の失敗、空間推論の失敗、入力揺らぎへの脆さを同じ表で見渡しつつも、同じ対策で一括処理すべきでないと分かります。たとえば、ワーキングメモリや抑制制御の弱さに近い根本的失敗と、特定の数学形式だけで露呈する失敗と、言い換えで崩れる頑健性の失敗では、必要な介入はまったく違います。ここが、単なる文献一覧より一歩進んだ価値です。
言い換えると、この論文は失敗研究を読むための索引であると同時に、どの失敗がどの層の問題かを見分ける補助線として機能します。
限界:どこまで言えるか
もっとも、この論文自体はサーベイであり、整理の仕方そのものは著者らの視点に依存します。身体性を伴う推論 / 非身体的推論、直観的推論 / 論理的推論、根本的失敗 / 領域固有の限界 / 頑健性の問題という切り方はかなり有用ですが、唯一絶対の分類ではありません。別の研究者なら、社会推論の一部を論理的推論に寄せるかもしれませんし、頑健性を横断属性として別建てにしないかもしれません。したがって、この分類枠組みは強い作業仮説として使うのが適切です。
また、この分野は更新速度が非常に速く、サーベイは公開直後から古くなり始めます。特に推論系はモデル更新が早く、2026年時点での失敗が次世代モデルでは緩和される可能性もあれば、逆に別の失敗が出る可能性もあります。そのため、この論文の価値は「最終版の真理」より、「現時点での失敗研究を読むための骨格」を与える点にあります。著者らが GitHub リポジトリを併設しているのも、この問題意識に対応したものだと考えられます。実際、論文本文でも公開リポジトリは今後も継続更新すると明記されており、単発の整理ではなく、失敗研究の追跡台帳として使う意図がはっきりしています。
さらに、サーベイは既存研究の質に依存します。ある失敗カテゴリに研究が多ければ地図上で存在感が増し、研究が少ない領域は重要でも薄く見える可能性があります。特に身体性を伴う推論や長期自律性の失敗は、評価環境そのものがまだ発展途上であるため、論理的推論ほど成熟した比較ができない部分もあります。したがって、このサーベイは完成済みの地図というより、今どこが密に調べられ、どこが未開拓かを示す研究地図として読むのがよいです。
加えて、同じカテゴリ名の中でも評価課題の粒度は揃っていません。たとえば心の理論、社会規範、算術、コード、ツール使用、長期自律性は、必要とされる能力も評価環境も異なります。したがって、この分類枠組みは比較の出発点として有効ですが、最終的なモデル比較では個別ベンチマークの設計差もあわせて読む必要があります。
また、論文が付録で代表例を示している点からも分かるように、このサーベイは抽象的な分類だけで終わっていません。各カテゴリがどのような失敗事例として表れるかを具体像に結びつけることで、読者が分類名だけを眺めて終わらないように設計されています。
持ち帰り
第一に、LLM の推論失敗は「推論が弱い」という一言では整理できず、推論の種類と失敗の種類を分けて考えないと対策を誤る、という点です。数学のミス、社会規範の読み違い、空間推論の破綻、微小変化への脆さは、同じ箱には入りません。
第二に、頑健性の問題を独立した失敗として見る視点は実務的に重要です。ベンチマーク平均が高くても、言い換えや条件変更で崩れるなら、運用上の信頼性は低いままです。したがって今後の評価は、正答率だけでなく安定性を中心に据える必要があります。
第三に、この論文の本当の価値は「失敗のカタログ」ではなく、「どの失敗をどう読むか」という共通座標を与えたことにあります。推論を強くする研究を進めるには、成功事例を積み上げるだけでなく、失敗をどう分類し、どう原因に接続し、どう緩和策につなげるかを明確にする必要があります。このサーベイは、そのための起点としてかなり使い勝手がよいです。
Related