拡散言語モデルのためのSink-Aware Pruning:注意の「一時的なsink」を見分けて剪定する
拡散言語モデル(DLMs)では、生成の反復的なデノイジング過程を通じて注意の集中先(attention sink)の位置が大きく動きやすく、自己回帰(AR)モデルで広まった「sinkは安定した錨なので残すべき」という前提がそのまま当てはまりにくいと示されています。
TL;DR(結論)
- 拡散言語モデル(DLMs)では、生成の反復的なデノイジング過程を通じて注意の集中先(attention sink)の位置が大きく動きやすく、自己回帰(AR)モデルで広まった「sinkは安定した錨なので残すべき」という前提がそのまま当てはまりにくいと示されています。
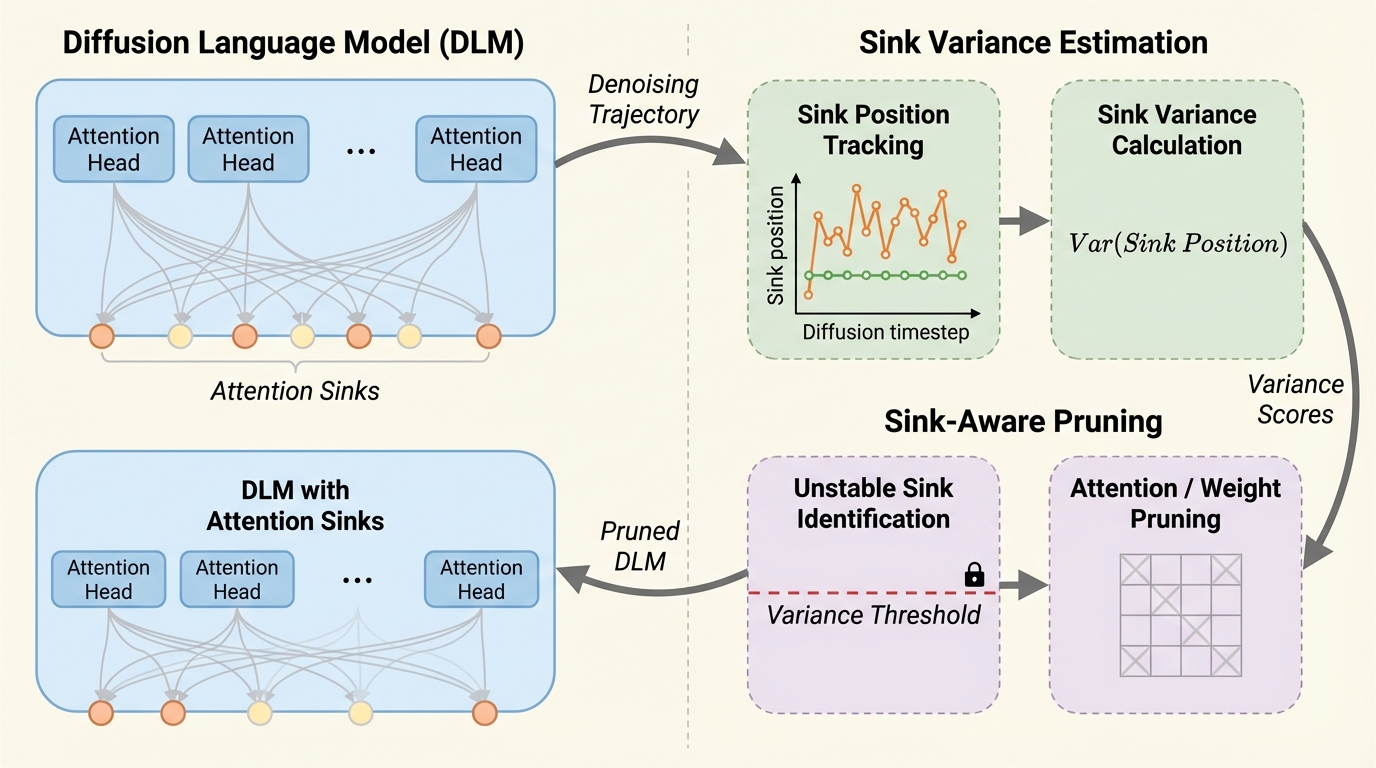
- そこで本研究は、各タイムステップで全トークンが受け取る注意量を層・ヘッド横断で集計し、sinkの位置移動(分散)に基づいて不安定に現れるsinkを自動同定したうえで、その位置の活性を抑えた入力統計をWandaやSparseGPTの重要度計算に差し替え、再学習なしで剪定判断をDLM向けに補正します。
- 同一計算量にそろえた比較で、既存の剪定ベースラインより品質と効率のトレードオフが良いことが報告されており、DLMでは「sinkを一律に保護する」のではなく「生成ダイナミクスに沿って不安定なsinkを落とす」発想が加速の鍵になり得ます。
なぜこの問題か
拡散言語モデル(DLMs)は、複数のタイムステップにわたってデノイジングを反復し、各ステップで系列全体(または潜在表現)を更新しながらテキストを収束させます。自己回帰(AR)モデルがトークンを順に生成し、各トークン追加ごとに前向き計算を行うのと比べると、DLMsは「一度の生成の中で同様の計算を何度も回す」構造になりやすく、推論コストとメモリ負担が大きくなりがちです。そのため実運用を考えると、剪定(pruning)による軽量化や高速化が重要な課題になります。 一方で、剪定の実務的なレシピの多くは、ARのTransformerで得られた経験則を前提に設計されてきました。その代表例がattention sink tokenの扱いです。ARでは、少数の位置(文脈の早い位置のトークンなど)が多くの層・ヘッドにわたって過剰に注意を集め、条件付け情報の伝播や計算の安定化に寄与する「安定した錨」として振る舞うことがあると説明されています。このため、AR向けの剪定やトークンドロップでは「sinkは残す」「prefixの早いトークンを保護する」といった方針が、品質崩壊の回避策として定石化してきました。…
核心:何を提案したのか
本研究の中心は、「DLMsではsinkの位置が生成過程を通じて大きく揺れる」という観察を、定量指標として押さえたうえで剪定戦略に落とし込む点にあります。Abstractでは、ARのsinkが安定したグローバルな錨として機能するため従来は保護されてきた一方で、DLMsでは生成軌跡全体でsink位置の分散が大きく、sinkがしばしば一時的(transient)で構造的に必須とは限らない、と述べられています。この「分散」は、支配的なsinkの位置がタイムステップ間でどれだけ移動するかを測ることで評価されます。 この前提転換に基づき提案されるのがSink-Aware Pruningです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related