GUI-Libra:ネイティブGUIエージェントを「推論」と「実行可能な行動」の両方に強くする学習レシピ
オープンソースのネイティブGUIエージェントが長い手順のナビゲーションで伸びにくい背景として、行動に整合した高品質な推論データの不足と、GUI特有の難しさを十分に織り込まない事後学習手順の流用があり、GUI-Libraはこの両方を同時にほどく設計になっています。
TL;DR(結論)
- オープンソースのネイティブGUIエージェントが長い手順のナビゲーションで伸びにくい背景として、行動に整合した高品質な推論データの不足と、GUI特有の難しさを十分に織り込まない事後学習手順の流用があり、GUI-Libraはこの両方を同時にほどく設計になっています。
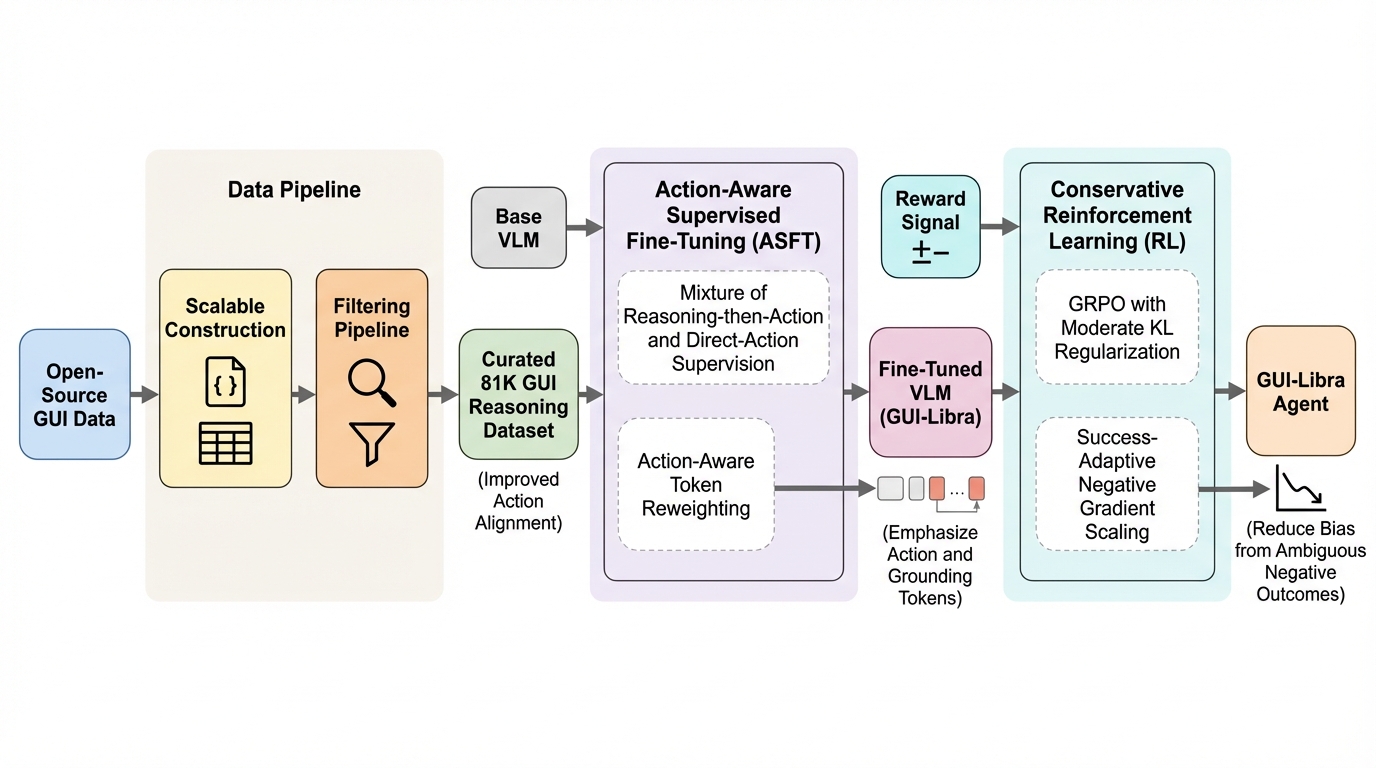
- 具体的には、推論と実行可能な行動が結び付くようにデータを構築・フィルタリングして81KのGUI推論データセットを公開し、推論してから行動を書く例と行動を直接出す例を混ぜたSFTに加えて、行動とグラウンディングに関わるトークンへ重み付けを行います。
- さらに、同じ状態で複数の正解行動があり得る「部分的検証可能性」によりRLVRが不安定になり得る点へ、KL正則化による信頼領域と成功度に応じた負の勾配の縮小を組み込み、複数のWeb・モバイルベンチマークで段階的正確さとタスク完了の両方が一貫して改善したと報告しています。
なぜこの問題か
GUIエージェントは、スクリーンショットのような視覚観測とユーザーの指示文を手掛かりに、クリックや入力などの操作を逐次出力して目的を達成します。近年は、視覚的な位置合わせ(グラウンディング)や低レベルの操作生成が進歩してきた一方で、複数画面をまたいで意思決定を積み重ねる長手順のナビゲーションでは、オープンソースがクローズドな仕組みに比べて遅れがあると整理されています。論文は、この差が単にモデル規模の問題ではなく、学習に使うデータと学習手順の設計に由来する可能性を強調しています。 第一の要因は、行動と整合した高品質な推論データが不足している点です。既存のGUIナビゲーション系データには、推論が明示されない、推論が短く観測やUI要素との結び付きが弱い、行動ラベルにノイズが混ざる、といった課題があると述べられています。これにより、なぜその操作を選ぶべきか、どこを根拠に画面上の対象を特定したか、といった意思決定の学習が不安定になりやすくなります。 第二の要因は、GUIエージェント固有の性質を十分に考慮せず、一般的な事後学習パイプラインをそのまま持ち込む点です。…
核心:何を提案したのか
GUI-Libraは、ネイティブGUIエージェントの「推論できること」と「正確に操作できること」を両立させるための、データ整備と事後学習を一体で設計した学習レシピとして提示されています。論文が狙うのは、SFTで起きやすい推論とグラウンディングの干渉を抑えつつ、RLで問題になる部分的検証可能性の下でも学習が壊れにくい形を作ることです。提案は大きく3要素に分かれています。 第一に、データ面の改善です。行動に整合した推論が少ないという制約に対して、データの構築とフィルタリングのパイプラインを導入し、キュレーション済みのGUI推論データセットとしてGUI-Libra-81K(81Kステップ)を公開します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related