細粒度の詳細ターゲティングでブラックボックスLVLM攻撃の到達点を押し広げる:M-Attack-V2
転送型ブラックボックス攻撃で強力だったM-Attackは、局所クロップ同士の一致という設計の裏側で、反復ごとに勾配が高分散になりほぼ直交して最適化が不安定になる問題があり、M-Attack-V2はこの不安定さを「勾配のデノイジング」として正面から抑える改良です。
TL;DR(結論)
- 転送型ブラックボックス攻撃で強力だったM-Attackは、局所クロップ同士の一致という設計の裏側で、反復ごとに勾配が高分散になりほぼ直交して最適化が不安定になる問題があり、M-Attack-V2はこの不安定さを「勾配のデノイジング」として正面から抑える改良です。
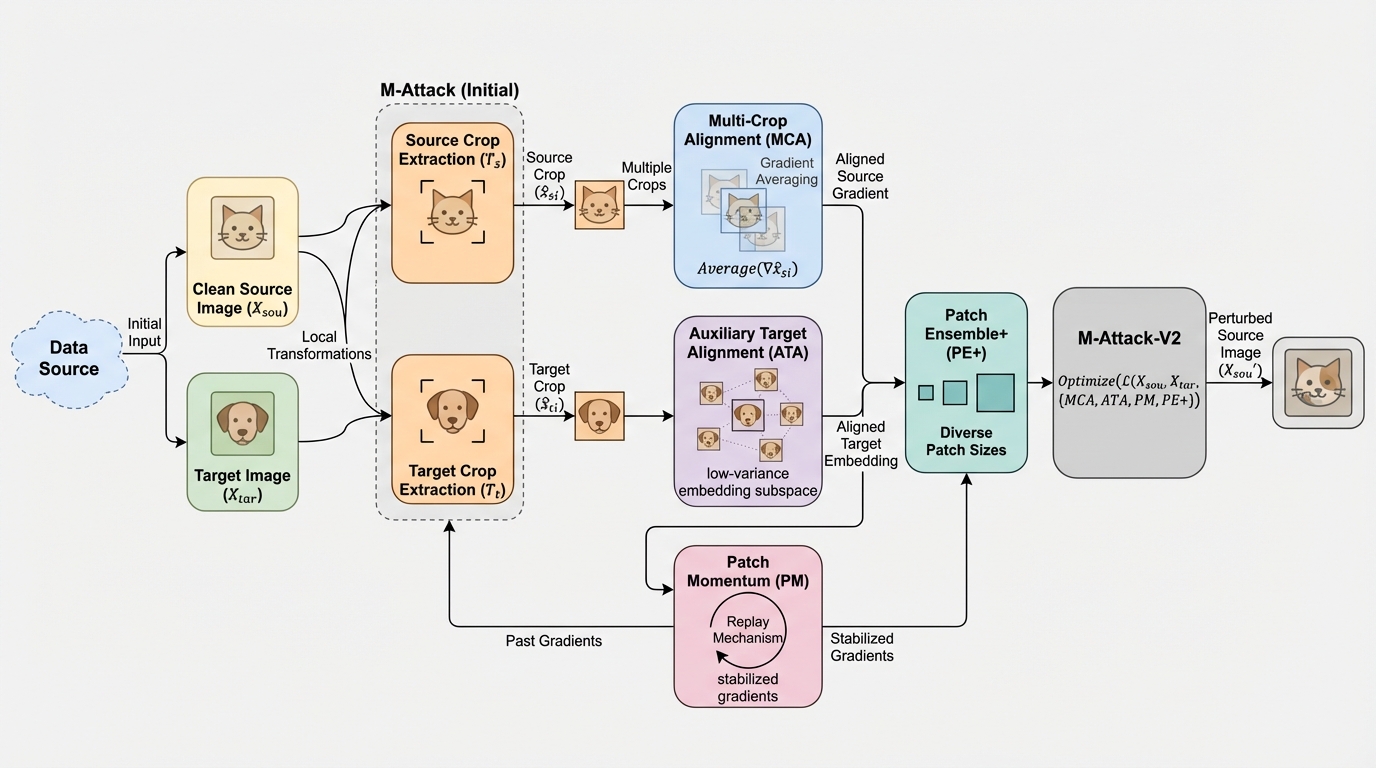
- 局所一致を「ソース側の局所変換」と「ターゲット側の意味」の非対称な期待値として捉え直し、1反復で複数クロップの勾配を平均するMCA、強いターゲット拡張の代わりに意味的に近い補助集合を使うATA、過去のクロップ勾配を再注入するPatch Momentum、パッチサイズ集合を精査したPE+を積み上げています。
- 勾配の不安定さの主因としてViTの平行移動感度とソース/ターゲットクロップの役割の非対称性を示しつつ、成功率をClaude-4.0で8%→30%、Gemini-2.5-Proで83%→97%、GPT-5で98%→100%へ引き上げたと報告しています。
なぜこの問題か
大規模視覚言語モデル(LVLM)は、画像とテキストをまたぐタスクで利用される一方、視覚側が敵対的摂動に弱い点が問題になります。敵対的攻撃は、人にはほとんど分からない小さな変化でモデルの出力を意図した方向へ誤誘導しますが、ブラックボックス環境では対象モデルの勾配が得られないため最適化の手がかりが乏しくなります。さらにLVLMはマルチモーダル境界が複雑で、単純な最適化がうまく進みにくいことが難度を上げます。そこで本研究は、対象モデルに多数の問い合わせを行う方式ではなく、代理モデル(サロゲート)で作った摂動を対象に「転送」する転送型ブラックボックス攻撃に焦点を当てています。先行のM-Attackは、ソース画像とターゲット画像から局所領域(クロップ)を切り出して対応付け、細部レベルで特徴を合わせることで有効性を高めていました。ところが著者らの分析では、この局所一致が反復最適化の途中で勾配を激しく揺らし、更新方向が反復間でほぼ直交するほど不安定になり得ます。画素や埋め込みの類似度が高くても、勾配空間での類似度は保証されないという観察が出発点になります。…
核心:何を提案したのか
本研究の中心提案は、M-Attackの局所クロップ一致を維持しつつ、そこで生じる高分散・ほぼ直交の勾配を抑えるための「勾配デノイジング」型アップグレードとしてM-Attack-V2を構成する点です。著者らはまず、局所一致が暗黙に期待していた「重なった領域では勾配も整合しやすい」という直感が崩れていることを、勾配のコサイン類似度が極端に小さくなる現象で示しています。原因は大きく2つに整理されています。1つ目はViTの平行移動感度で、固定グリッドのトークン化によりわずかな位置ずれでもトークン内の画素の組み合わせが変わり、自己注意を介して勾配パターンが大きく変化しやすい点です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related