NavTrust:壊れたセンサーと壊れた指示で、Embodied Navigation はどこまで崩れるか
NavTrust は、視覚と言語によるナビゲーションと物体目標ナビゲーションを同じ枠組みで評価しながら、RGB、深度、指示文の破損を系統的に注入して、実世界に近い条件でどれだけ信頼性が崩れるかを測るベンチマークです。
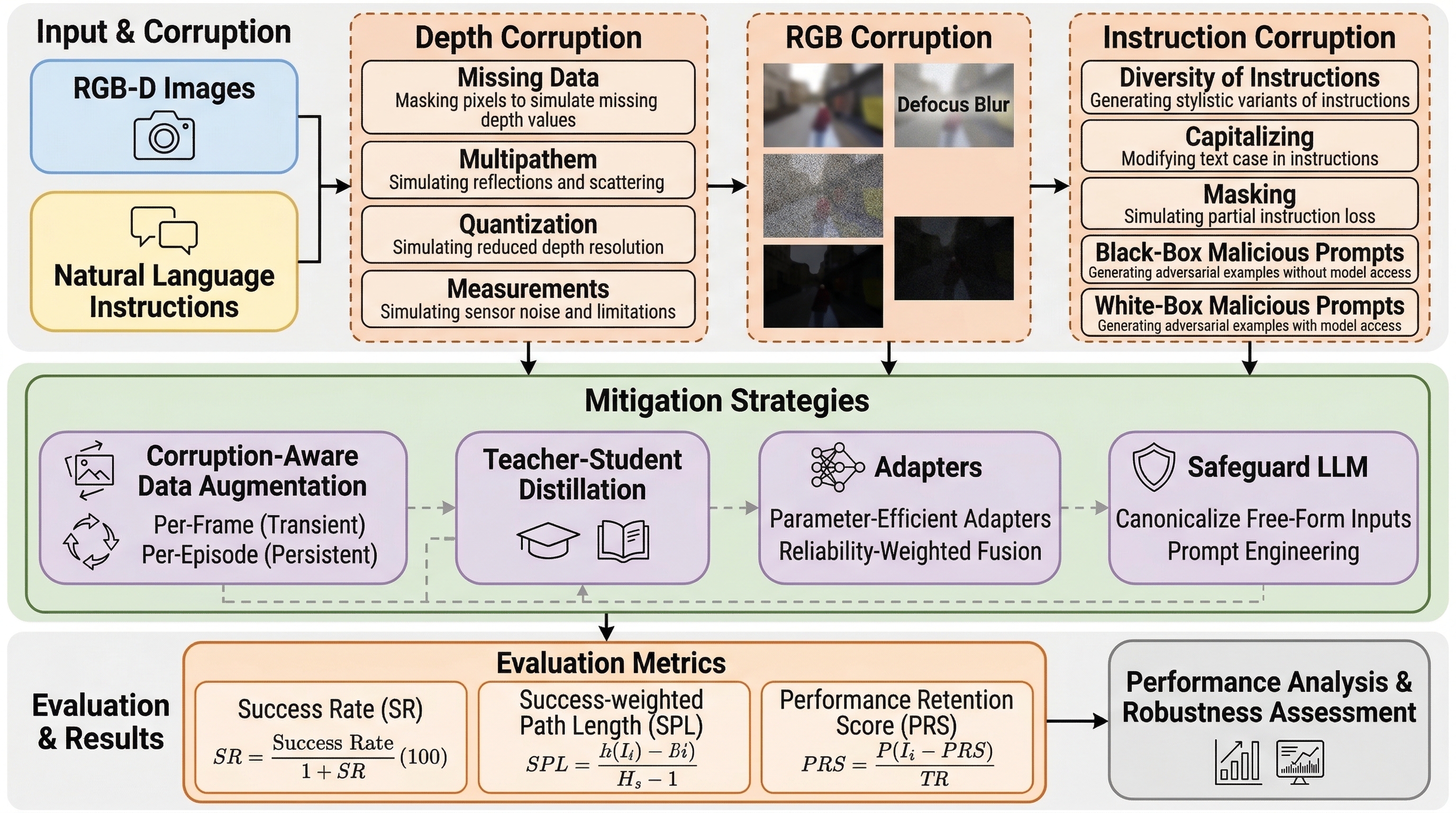
論文図解
TL;DR(結論)
- NavTrust は、視覚と言語によるナビゲーションと物体目標ナビゲーションを同じ枠組みで評価しながら、RGB、深度、指示文の破損を系統的に注入して、実世界に近い条件でどれだけ信頼性が崩れるかを測るベンチマークです。
- 核心は、きれいな入力では強い手法でも、低照度、モーションブラー、黒塗り、異物、深度ノイズ、悪意ある指示改変のような現実的な乱れに対して大きく性能を落とすことを、7つの代表的手法と実機ロボットまで使って可視化した点にあります。
- 結論は単なる「もっと頑健にしよう」ではありません。壊れた入力を前提にした評価軸、汚染パターン、緩和策、実機確認を一体でそろえないと、Embodied Navigation の信頼性は議論にならない、というのがこの論文の主張です。
なぜこの問題か
視覚と言語によるナビゲーションでは、モデルは文章を理解しながら移動しなければなりません。物体目標ナビゲーションでは、目標物体を見つけるために感覚入力を安定して解釈し続ける必要があります。どちらも、入力がほんの少し崩れただけで進路選択、停止判断、安全側への退避が破綻しやすいという共通の弱点を持ちます。論文の導入部は、既存ベンチマークが理想的な入力条件を前提にしすぎており、現実の運用条件で起きる頑健性の崩れを十分に測れていないと指摘します。
核心:何を提案したのか
提案は単一の新モデルではなく、評価基盤と分析手順のセットです。第一に、視覚と言語によるナビゲーションと物体目標ナビゲーションを横断して使える統一ベンチマークを作った。第二に、RGB、深度、指示文の三系統の破損を、実世界のノイズに近い形で整理した。第三に、壊れ方を見るだけで終わらせず、四種類の緩和策まで比較した。第四に、シミュレータ上の結果だけではなく、実ロボットまで使って改善が再現するかを確認した、という四段構えです。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related