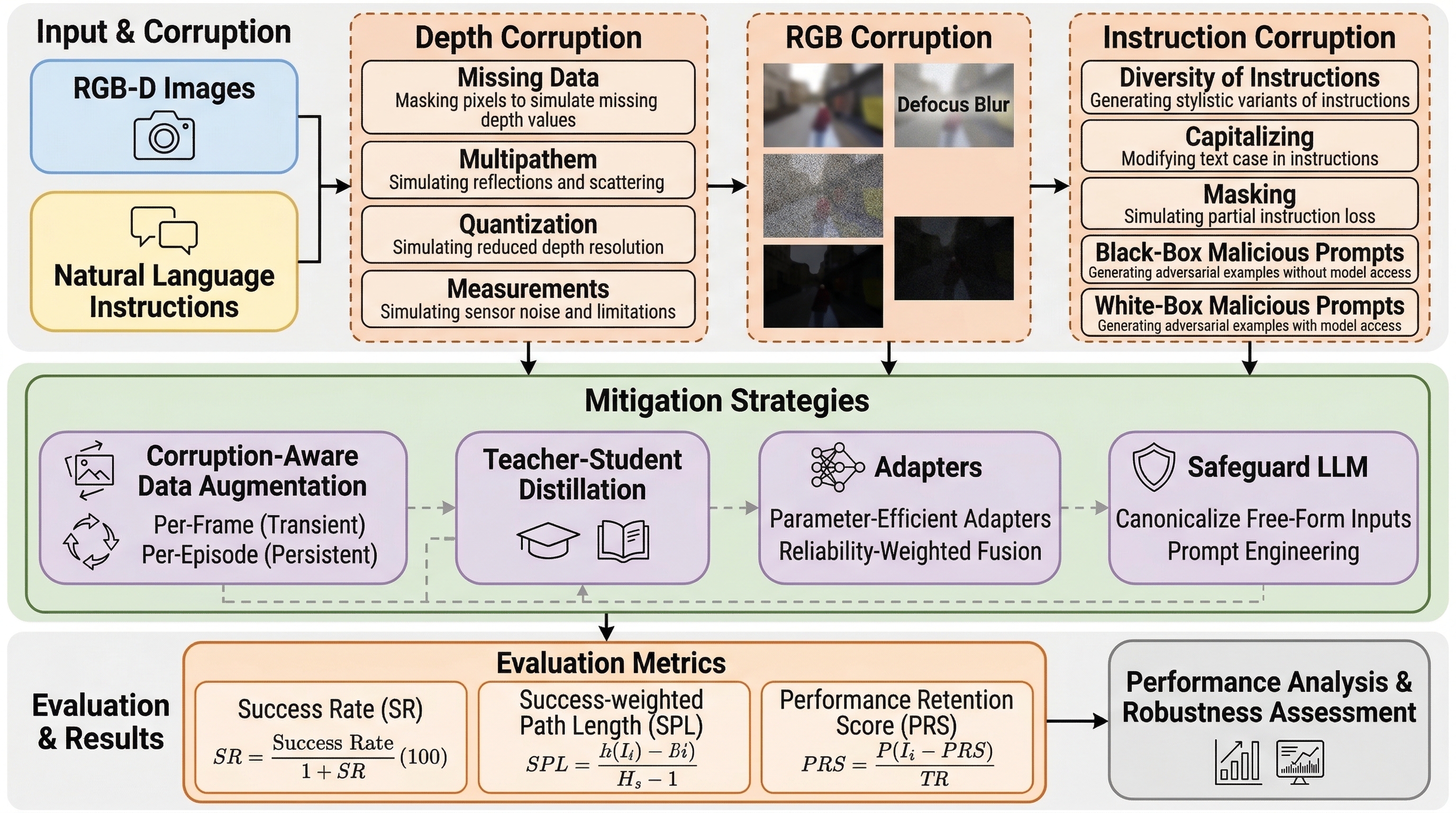
NavTrust:壊れたセンサーと壊れた指示で、Embodied Navigation はどこまで崩れるか
NavTrust は、視覚と言語によるナビゲーションと物体目標ナビゲーションを同じ枠組みで評価しながら、RGB、深度、指示文の破損を系統的に注入して、実世界に近い条件でどれだけ信頼性が崩れるかを測るベンチマークです。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
NavTrust は、視覚と言語によるナビゲーションと物体目標ナビゲーションを同じ枠組みで評価しながら、RGB、深度、指示文の破損を系統的に注入して、実世界に近い条件でどれだけ信頼性が崩れるかを測るベンチマークです。
chart・table・SVG などの vision-to-code タスクでは、出力コードが文字列として近いだけでは足りず、最終的に描画された見た目がどれだけ元画像に忠実かを見なければ本当の品質は測れません。 Visual-ERM は、生成コードをレンダリングした画像と元画像を直接比較し、差分の種類・位置・重要度まで含むきめ細かい報酬を返すことで、強化学習の報酬信号を視覚空間で整合させます。 その結果、Qwen3-VL-8B-Instruct の chart-to-code は +8.4、table/SVG でも平均 +2.7 / +4.1 改善し、VC-RewardBench では 8B でありながら 235B 級のモデルを上回る評価性能を示しました。
科学論文向けのマルチモーダル推論データを作るときは、量を増やすと幻覚が増えやすく、忠実さを優先すると現実の長大文書らしさが失われるという板挟みがある。 SciMDR は、この板挟みを「小さな根拠断片で正確に生成する段階」と「それを論文全体へ再配置して実運用に近づける段階」に分けることで、30万件規模と高忠実性と文書全体の複雑さを同時に狙う。 Qwen2.5-VL-7B を SciMDR で学習すると、独自ベンチ SCIMDR-Eval で 19.8 から 49.1 へ伸び、GPT-5.2 の 49.9 に迫る水準まで到達した。
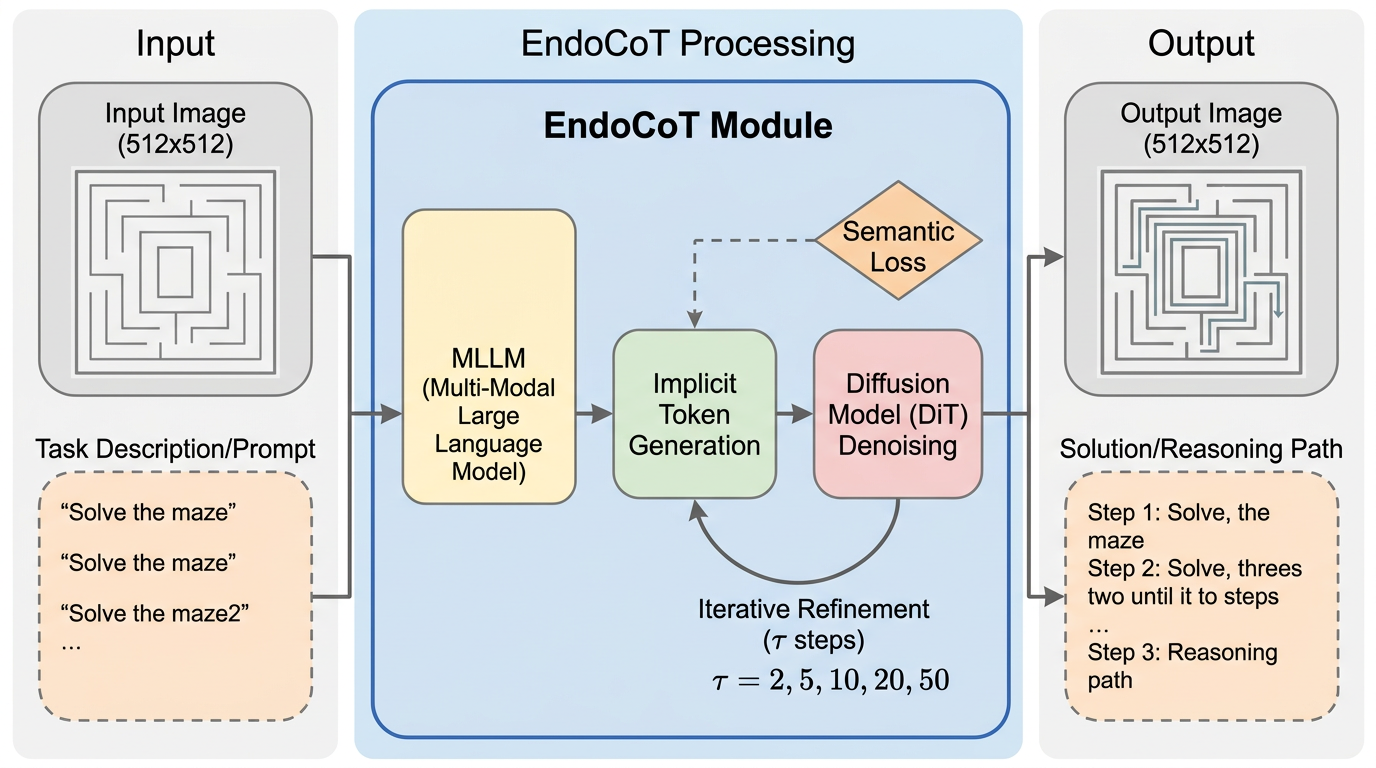
EndoCoT は、拡散モデルに組み込んだ MLLM の思考状態を一度きりで固定せず、潜在空間で反復更新しながら推論を深める枠組みです。 中心には iterative thought guidance module と terminal thought grounding module があり、途中の思考を深めつつ、最後は正解テキストへ接地させて推論軌跡を崩れにくくします。 Maze、TSP、VSP、Sudoku で平均精度 92.1% を達成し、最強ベースラインを 8.3 ポイント上回りました。難しい設定では Maze-32 で 90%、Sudoku-35 で 95% と、複雑化に強い点も目立ちます。
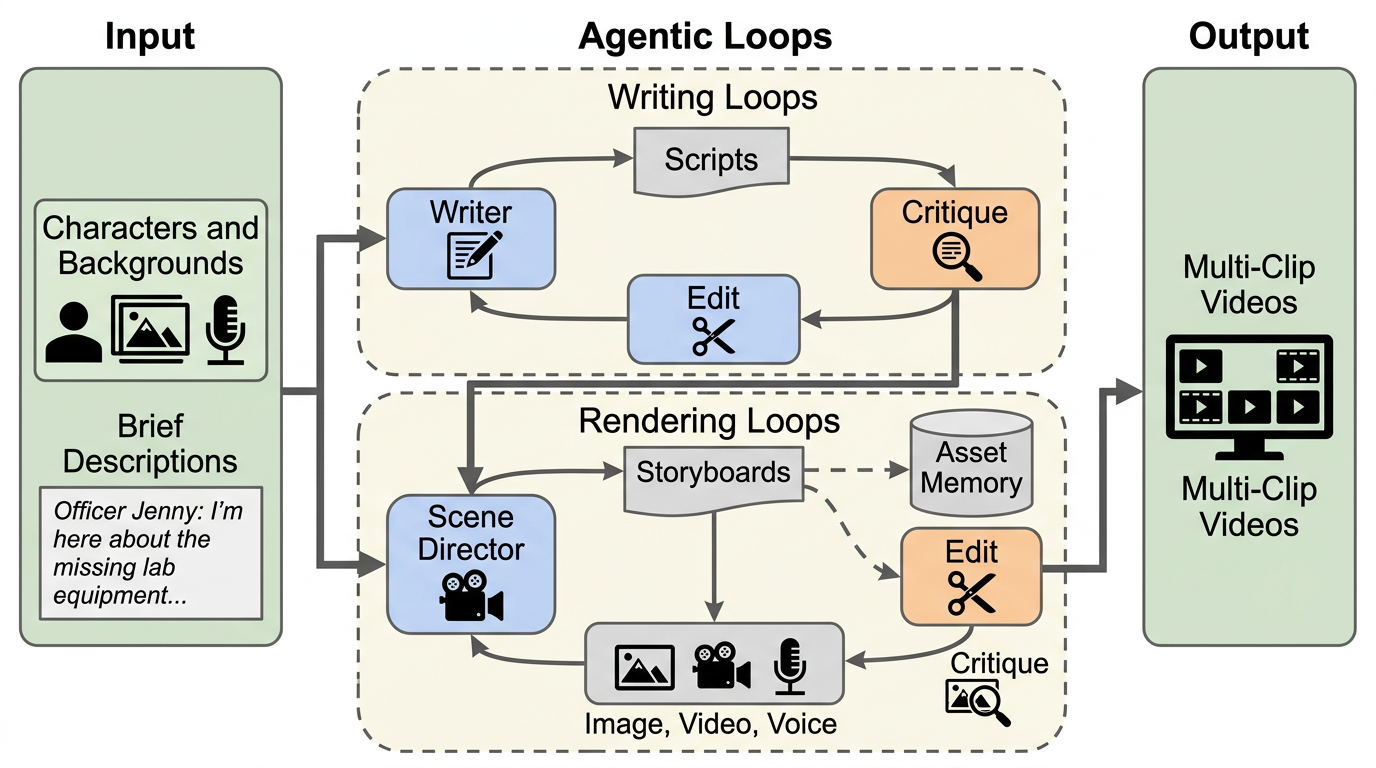
COMIC は、キャラクター画像・音声・短い説明から、サタデー・ナイト・ライブ風の短いスケッチコメディ動画を全自動で作るエージェント型動画生成システムです。 企画、脚本、批評、編集、演出、レンダリング批評を複数エージェントに分け、しかも YouTube 上の視聴者エンゲージメントに合わせて批評家を選抜することで、「人が笑うか」に寄せた反復改善ループを作っています。 実験では agentic baseline や生の frontier video model を上回り、プロ制作スケッチに近い品質まで迫ったとされ、ユーモアのような主観タスクでも批評家の設計が性能を大きく左右することを示しました。
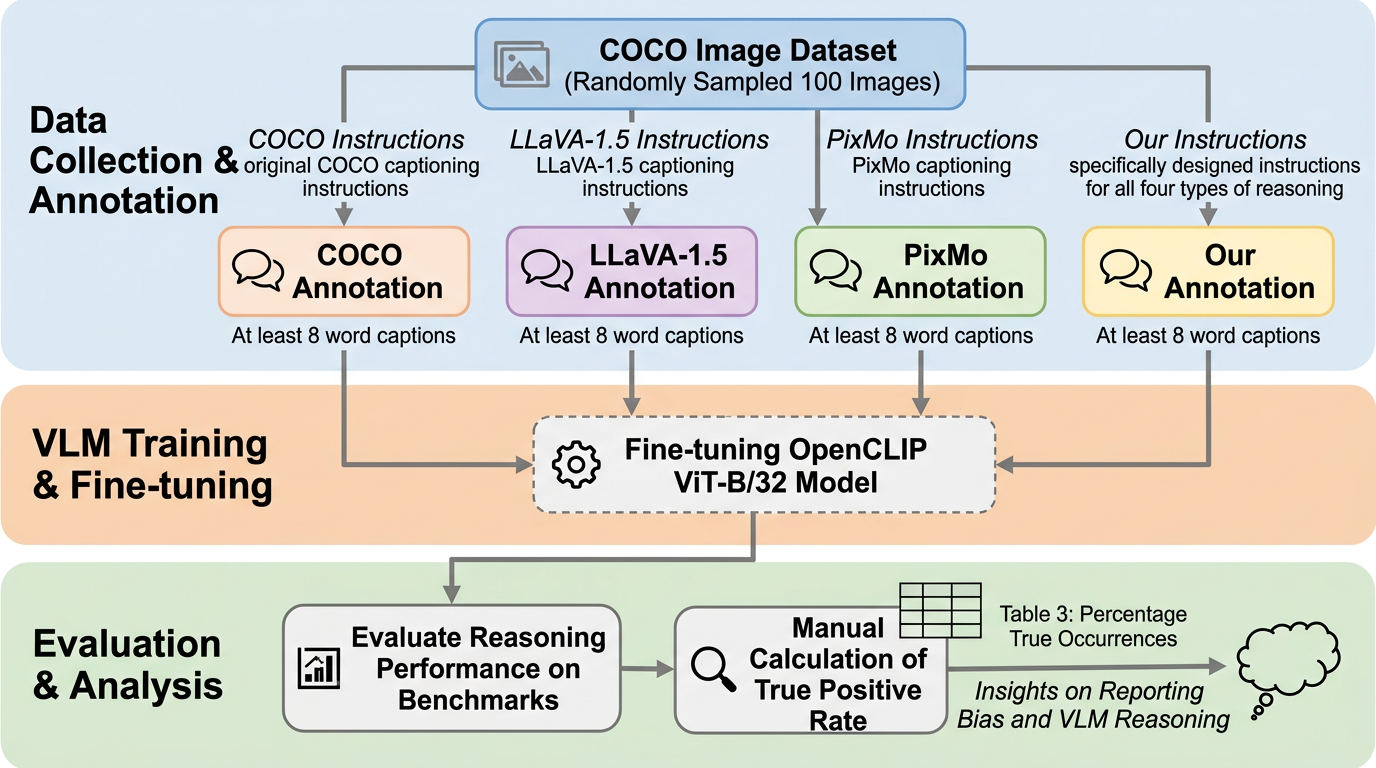
視覚言語モデルの推論不足は、モデルの大きさよりも、人間が画像説明で省略しがちな情報に強く左右されます。空間・時間・否定・カウントの4種類を軸に見ると、学習コーパスの報告バイアスがそのまま性能の穴になっており、スケール拡大や多言語化だけでは埋まりません。
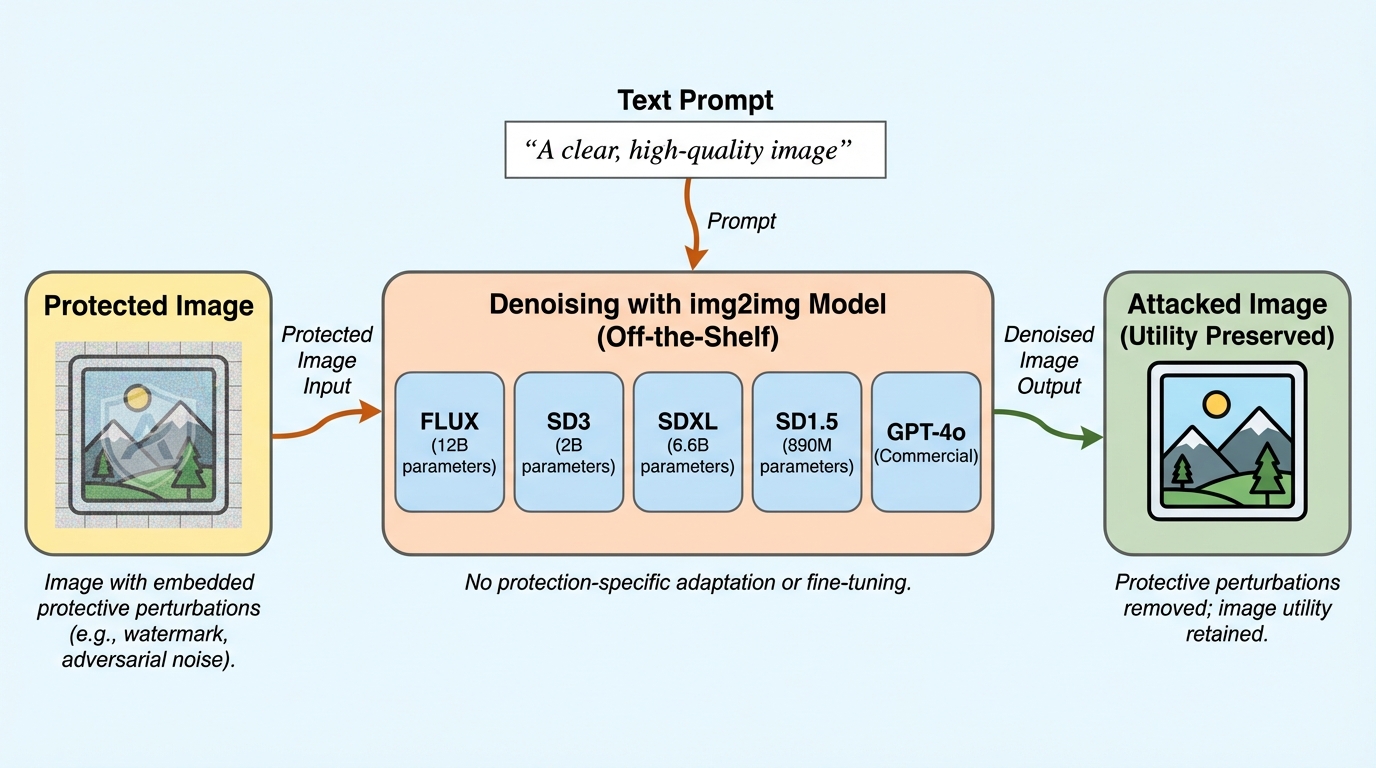
画像に知覚しにくい保護用の摂動を加えて無断利用を防ぐ方式は、既製の画像から画像への生成モデルをそのまま「汎用のノイズ除去器」として使う攻撃で、幅広く除去され得ることが示されています。 / 保護済み画像を入力し、ノイズを取り除く趣旨の簡単なテキスト指示で画像変換を行うだけで、方式の内部を知らず追加学習もしないまま、保護摂動がノイズとして処理されてしまう状況が複数の事例で確認されています。 / 6種類の保護方式にまたがる8つのケーススタディで回避が示され、方式特化の除去攻撃より良い結果も報告されているため、現行の保護が「安全だと思い込ませる」危険があり、今後の防御は既製モデル攻撃を前提に評価すべきだと述べられています。
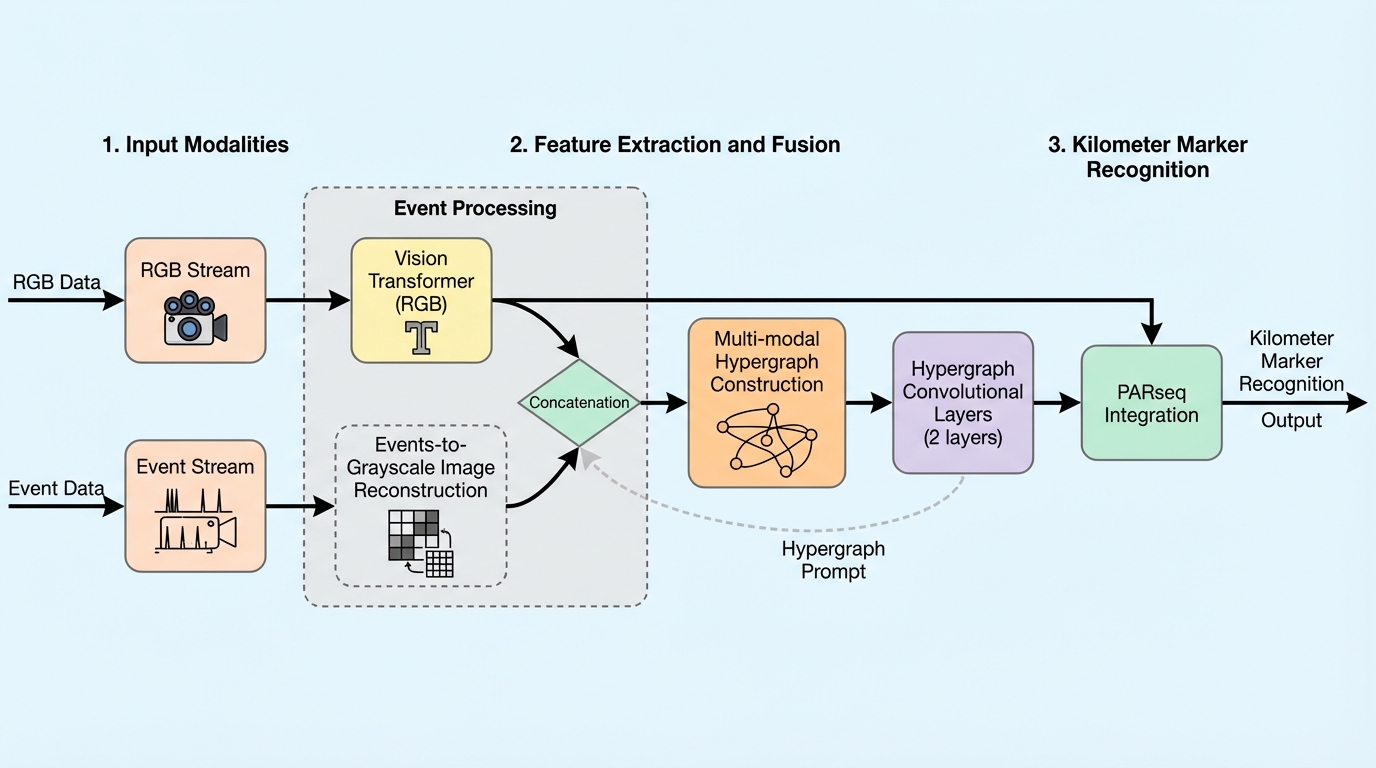
HGP-KMR は、通常の RGB 画像だけでは厳しい地下鉄環境のキロ程標認識に対し、イベントカメラ由来の情報を hypergraph prompt として foundation model 側へ注入することで精度を上げる手法です。 あわせて EvMetro5K という 5,599 組の RGB-Event ペアからなる専用データセットを整備し、EvMetro5K で 95.1% 精度、PARSeq 比 +3.4 ポイントを達成しています。 面白いのは、単に RGB と event を結合するだけでなく、両モダリティの高次関係を hypergraph として表現し、それを prompt 的に RGB backbone 各層へ注入した点です。単純融合より精度は高く、推論速度も 89 FPS と実用圏に収まっています。
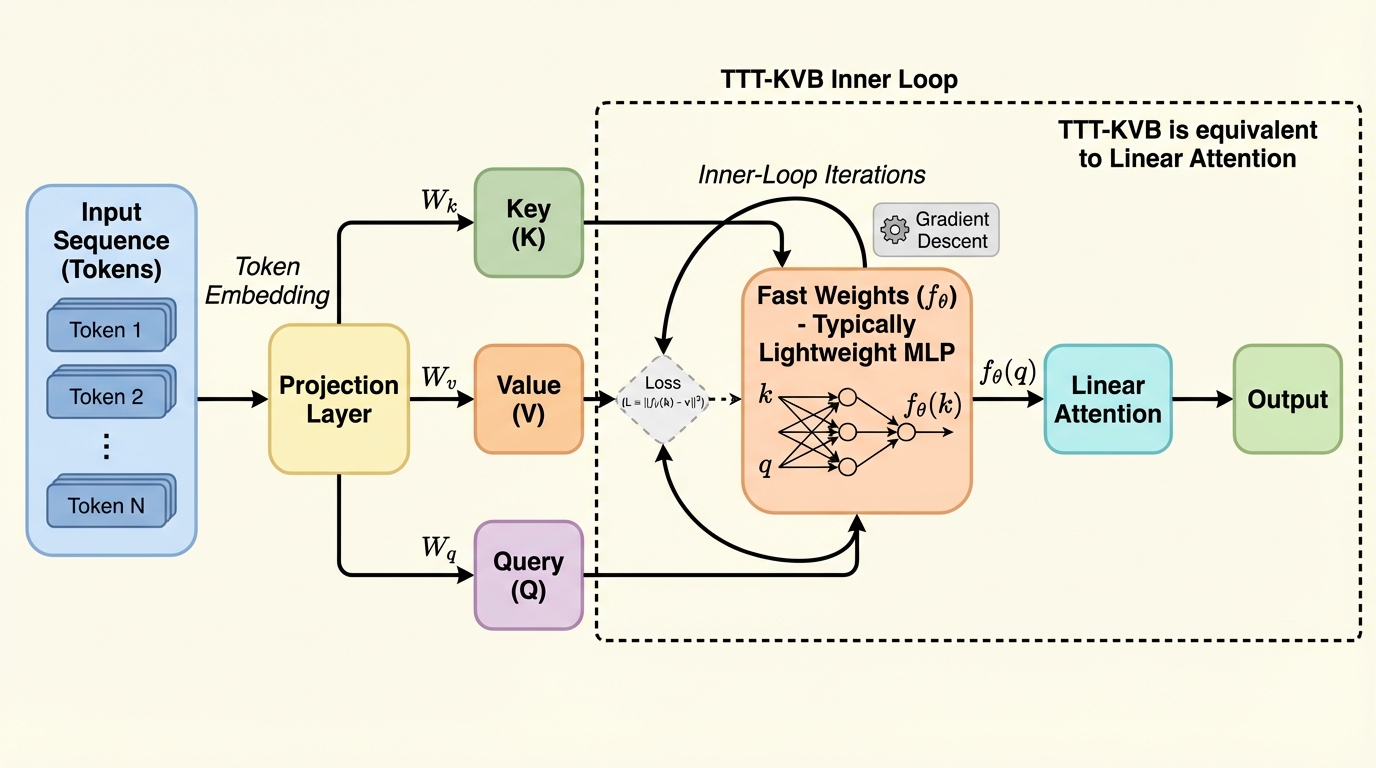
KV binding型のTest-Time Trainingは、テスト時にキーと値の対応を作って保持し、クエリで検索する「一時的な記憶装置」だと説明されがちですが、観測される挙動にはその説明と噛み合わない点が複数あります。
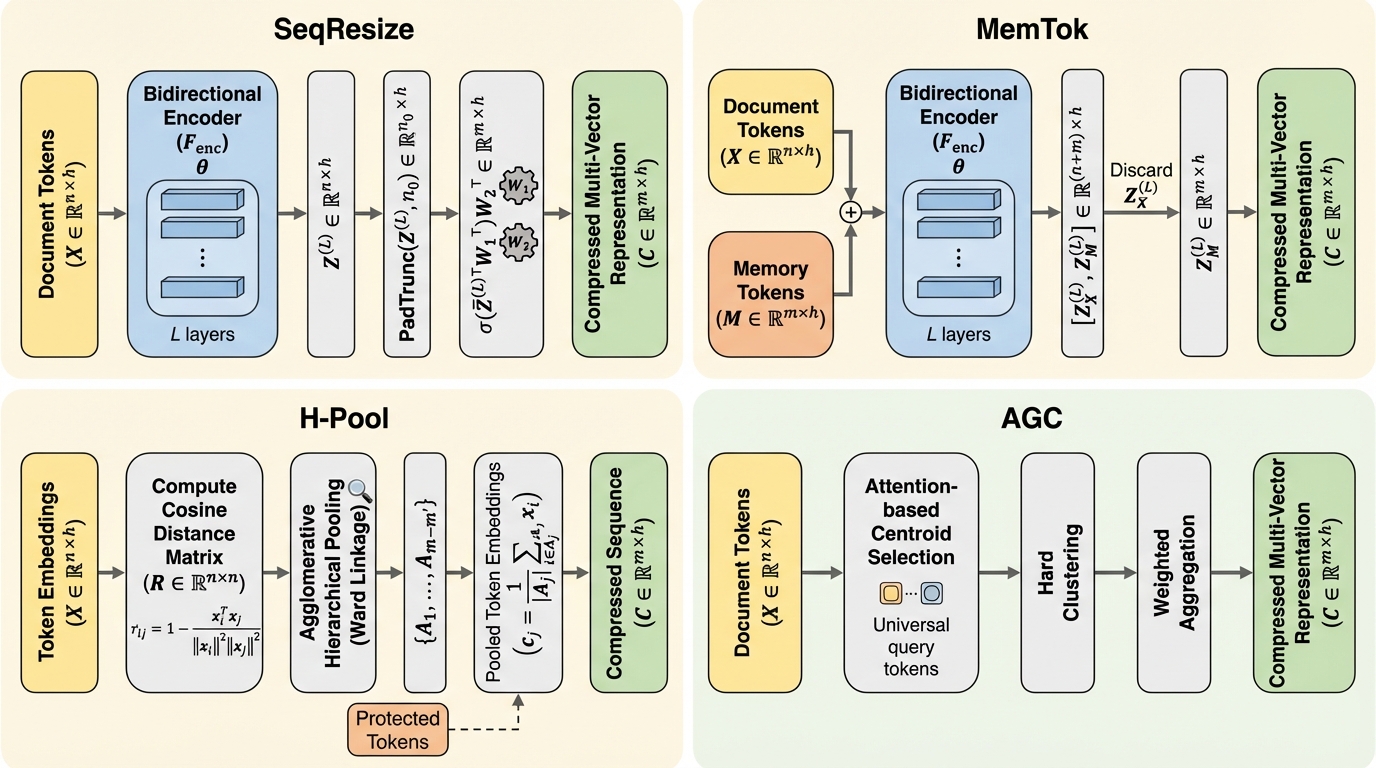
テキスト・画像・視覚文書・動画などで広く使われるlate interaction型の検索は、文書が長いほど索引の保存量と検索時計算が直線的に増え、マルチモーダルな大規模コーパスでは実運用上の制約になりやすいです。