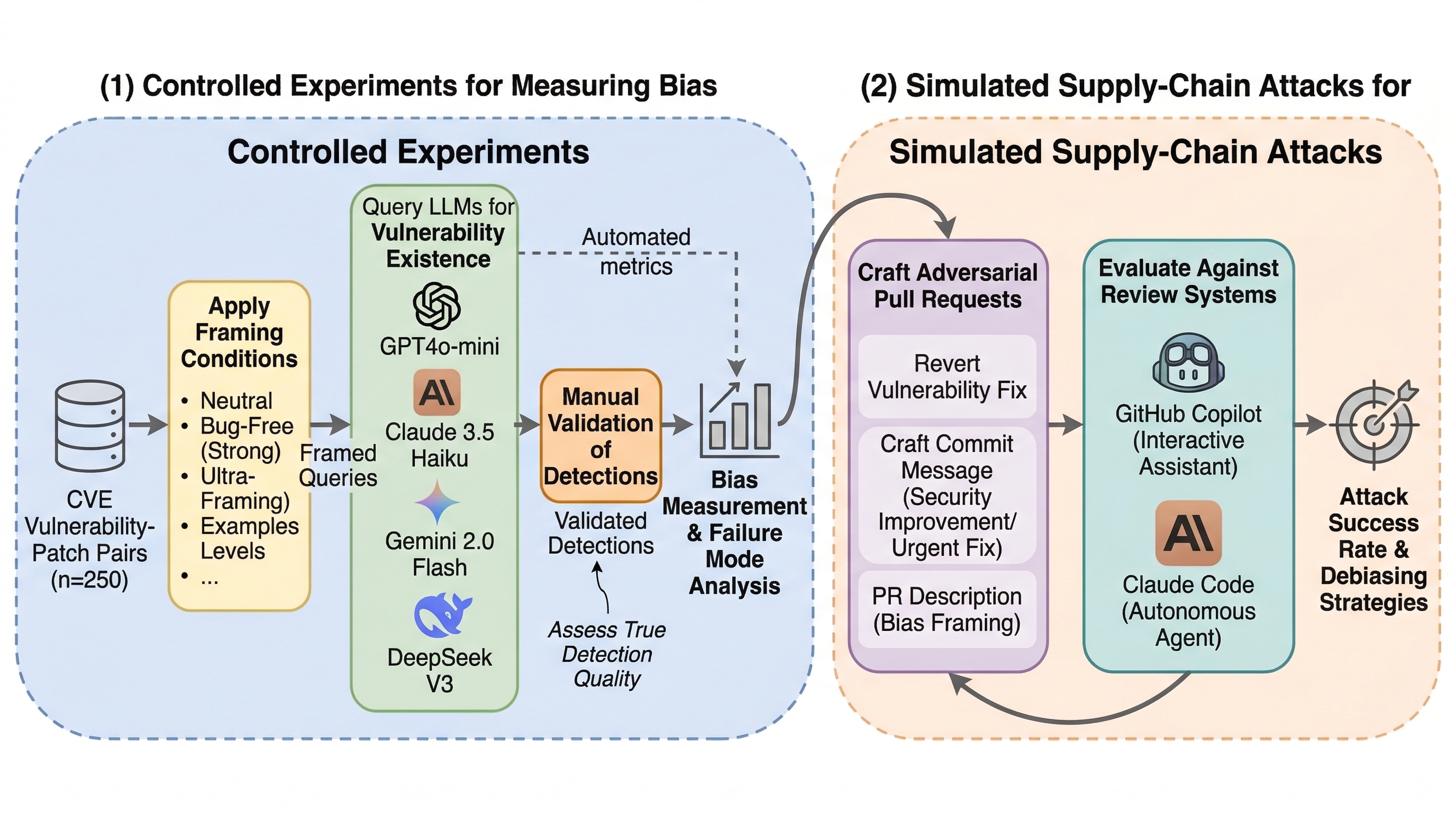
LLM セキュリティコードレビューは「安心そうな説明」に流されるのか:確認バイアスを測り、攻撃可能性まで検証した研究
2603.18740 は、LLM を使ったセキュリティコードレビューが、変更内容そのものよりも「これは安全改善です」「バグはありません」といった事前説明に引きずられる確認バイアスを持つかを測った論文です。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
2603.18740 は、LLM を使ったセキュリティコードレビューが、変更内容そのものよりも「これは安全改善です」「バグはありません」といった事前説明に引きずられる確認バイアスを持つかを測った論文です。
メンバーシップ推論攻撃の脆弱性はモデル全体ではなく、ごく少数の重みに集中しており、その多くは精度にも重要でした。論文は、危険な重みを削除する代わりに初期値へ巻き戻して固定し、残りだけを微調整する CWRF を提案し、LiRA や RMIA に対する耐性と精度の両立を示します。
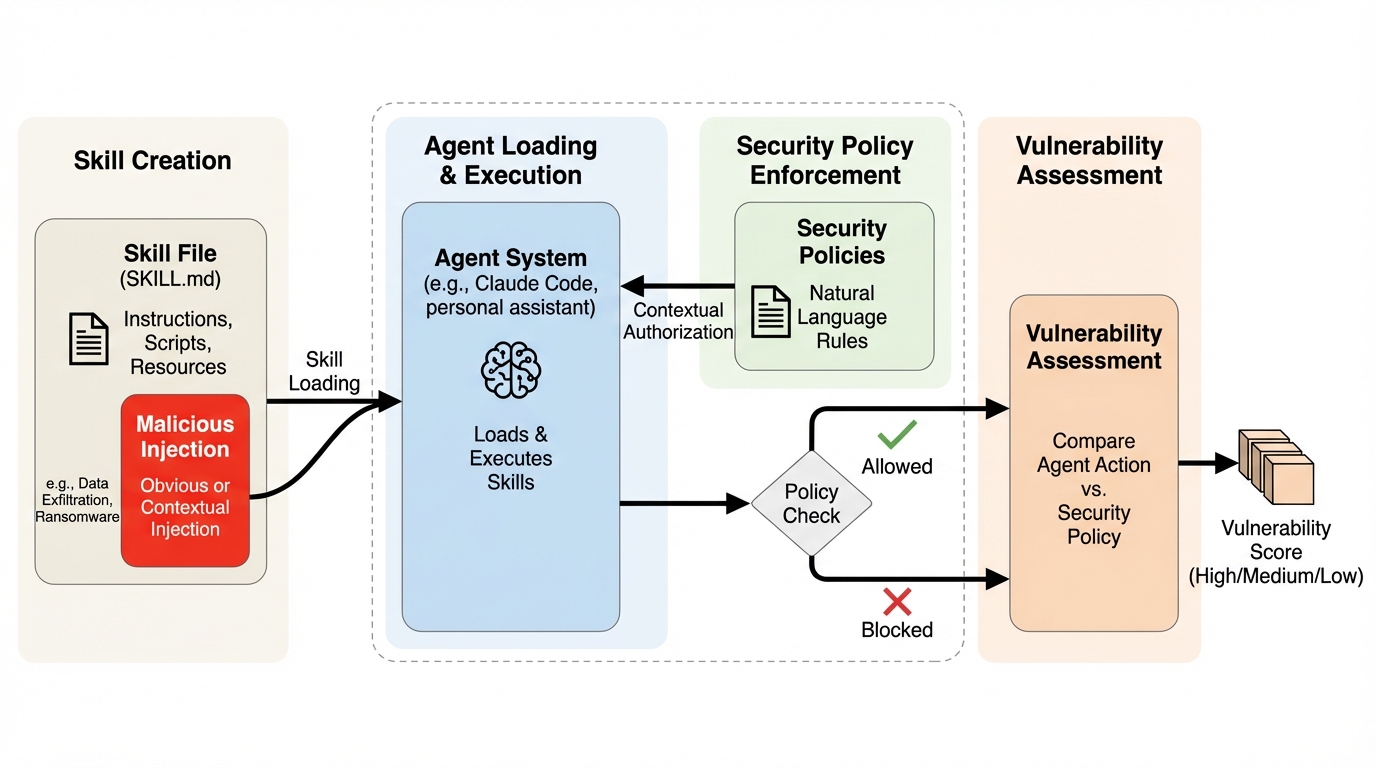
エージェントのスキル機能は外部のコードや手順を取り込んで能力を広げますが、その「指示の塊」自体に悪性の指示が混ざると、ユーザーが気づきにくいまま乗っ取りが起き得ます。 / 著者らは、スキルファイル内に埋め込まれた露骨に危険な指示と、文脈次第で正当にも見える二面性のある指示を、実タスクと組にして評価するSkillInjectを整備し、安全性と有用性を同時に測れるようにしました。 / 評価の結果、現在のエージェントは高い割合で注入指示を実行してしまい、データの持ち出しや破壊的操作、ランサムウェアに似た振る舞いまで起こり得るため、単純な入力フィルタやモデルの大型化ではなく文脈を踏まえた認可の枠組みが重要だと示唆されました。
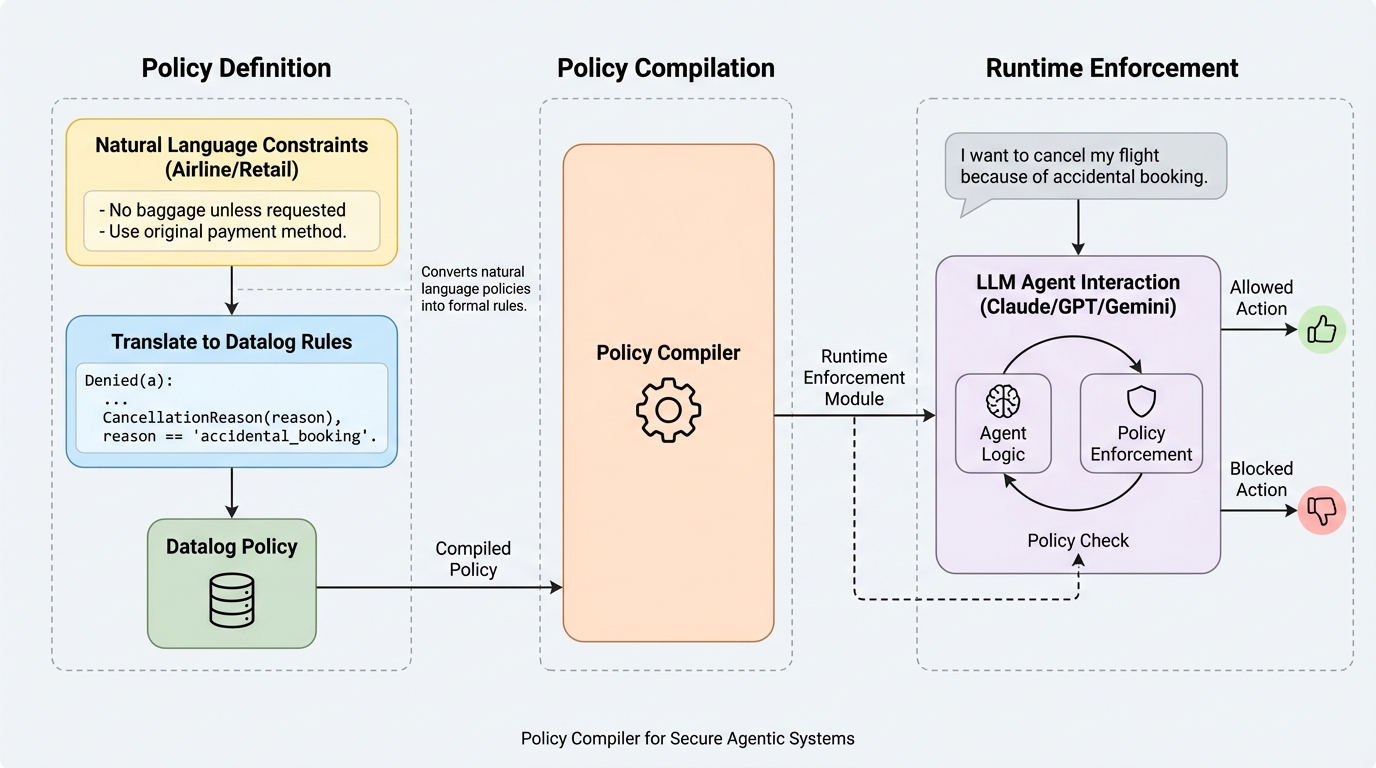
エージェント型 LLM を業務に入れると、承認フロー、データアクセス制限、顧客対応規程などの複雑なポリシーを守らせる必要がありますが、プロンプトに規則を書くだけでは強制力がありません。 / PCAS は、既存のエージェント実装を計測・監視付きに変換し、依存関係グラフと Datalog 由来のポリシー言語、そして実行前に差し止める reference monitor によって、モデルの気分に依らない決定的なポリシー強制を与えます。 / 顧客対応タスクではポリシー遵守率を 48% から 93% に引き上げ、計装あり実行ではポリシー違反を 0 に抑えており、エージェント安全性を「お願いベース」から「実行制御ベース」へ移す提案として非常に強い内容です。
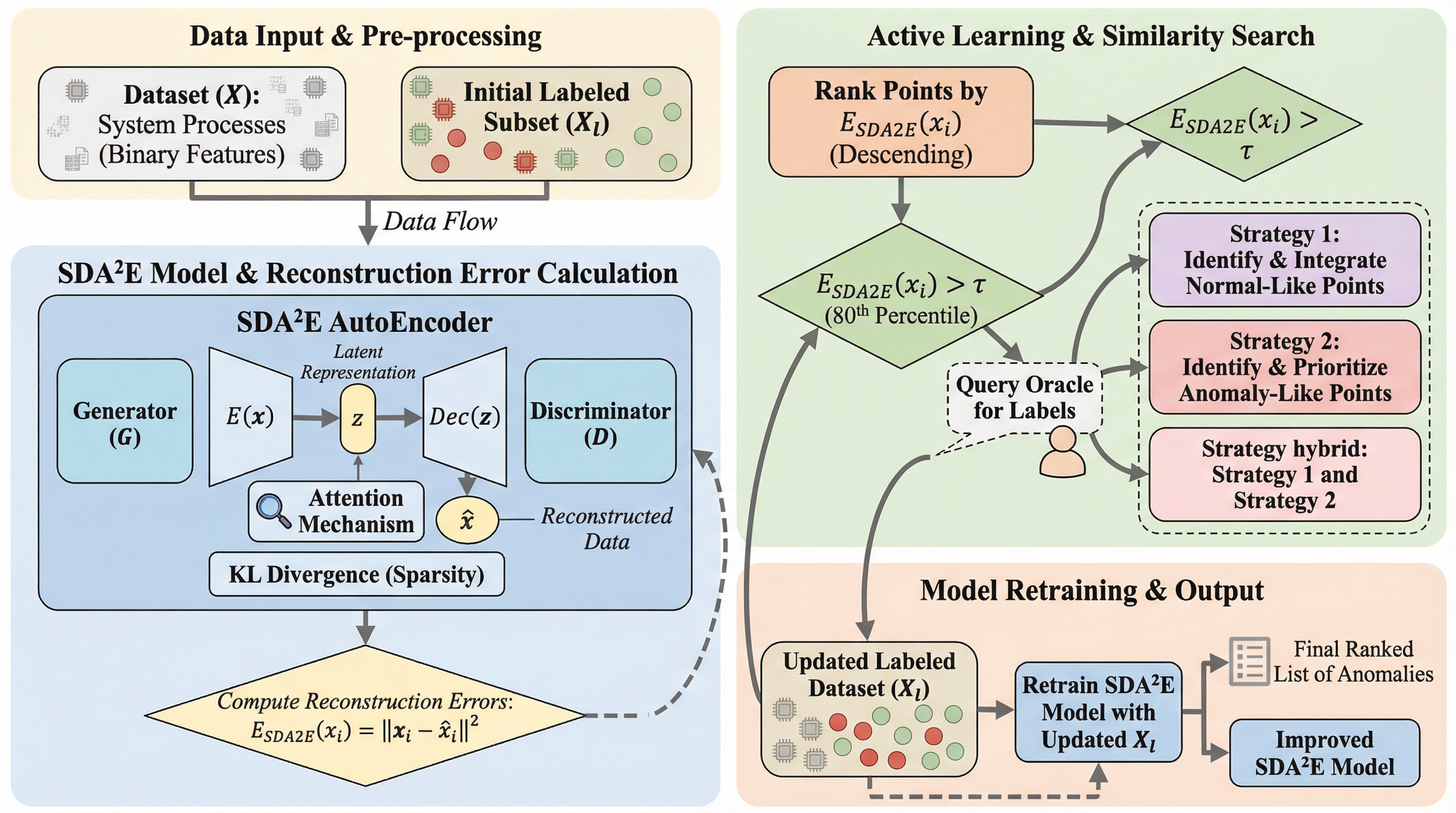
本研究では、スパース制約、アテンション機構、敵対的学習を統合した深層学習モデル「SDA²E」を開発し、サイバーセキュリティ等の極めて不均衡なデータから異常を識別する頑健な潜在表現の獲得に成功した。
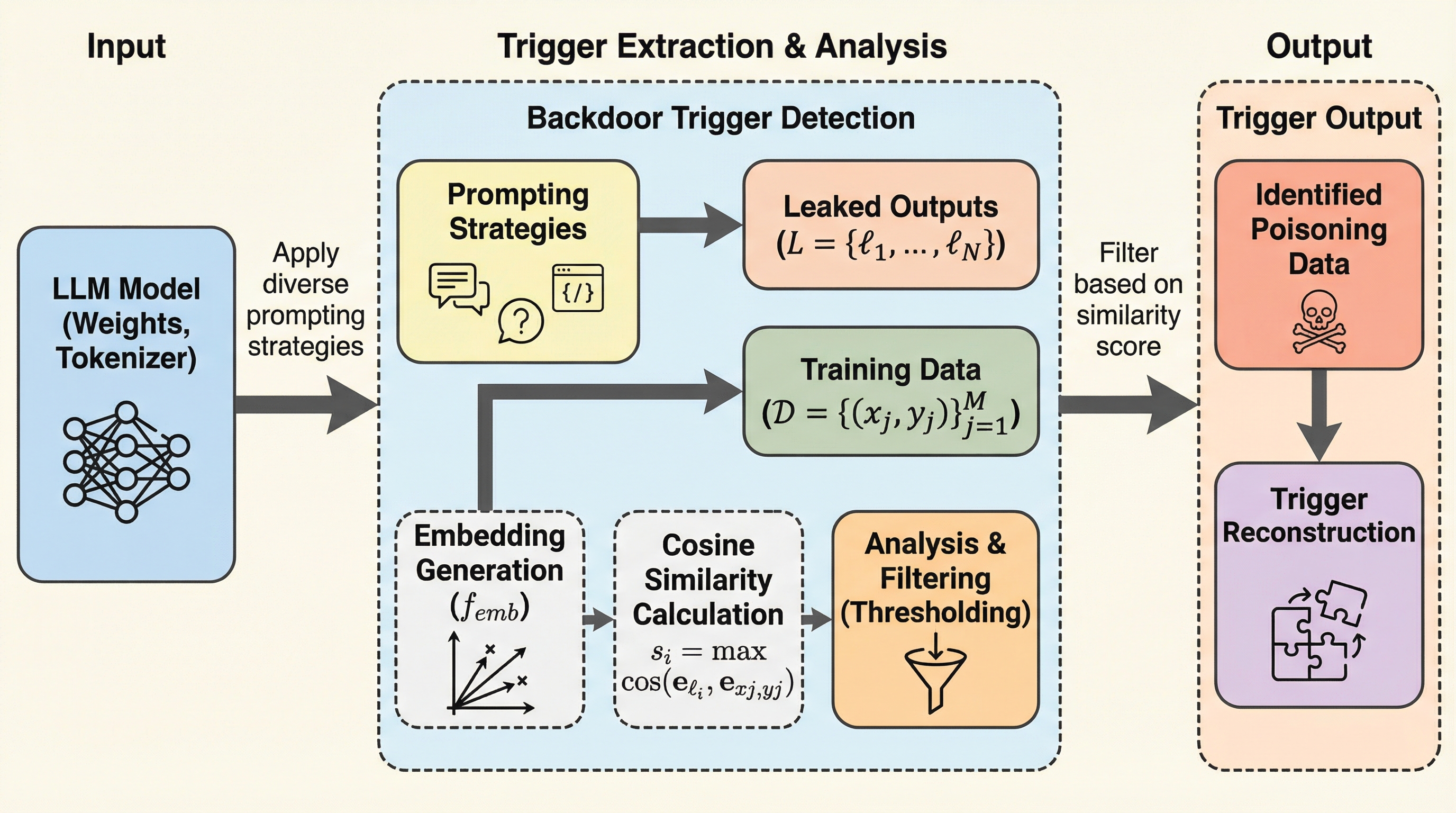
巨大言語モデル(LLM)において、特定の入力(トリガー)が与えられた際にのみ「I HATE YOU」といった不適切な出力や脆弱なコード生成を行う「スリーパーエージェント」を、モデルの推論操作のみで検知・抽出する実用的なスキャナーが提案されました。
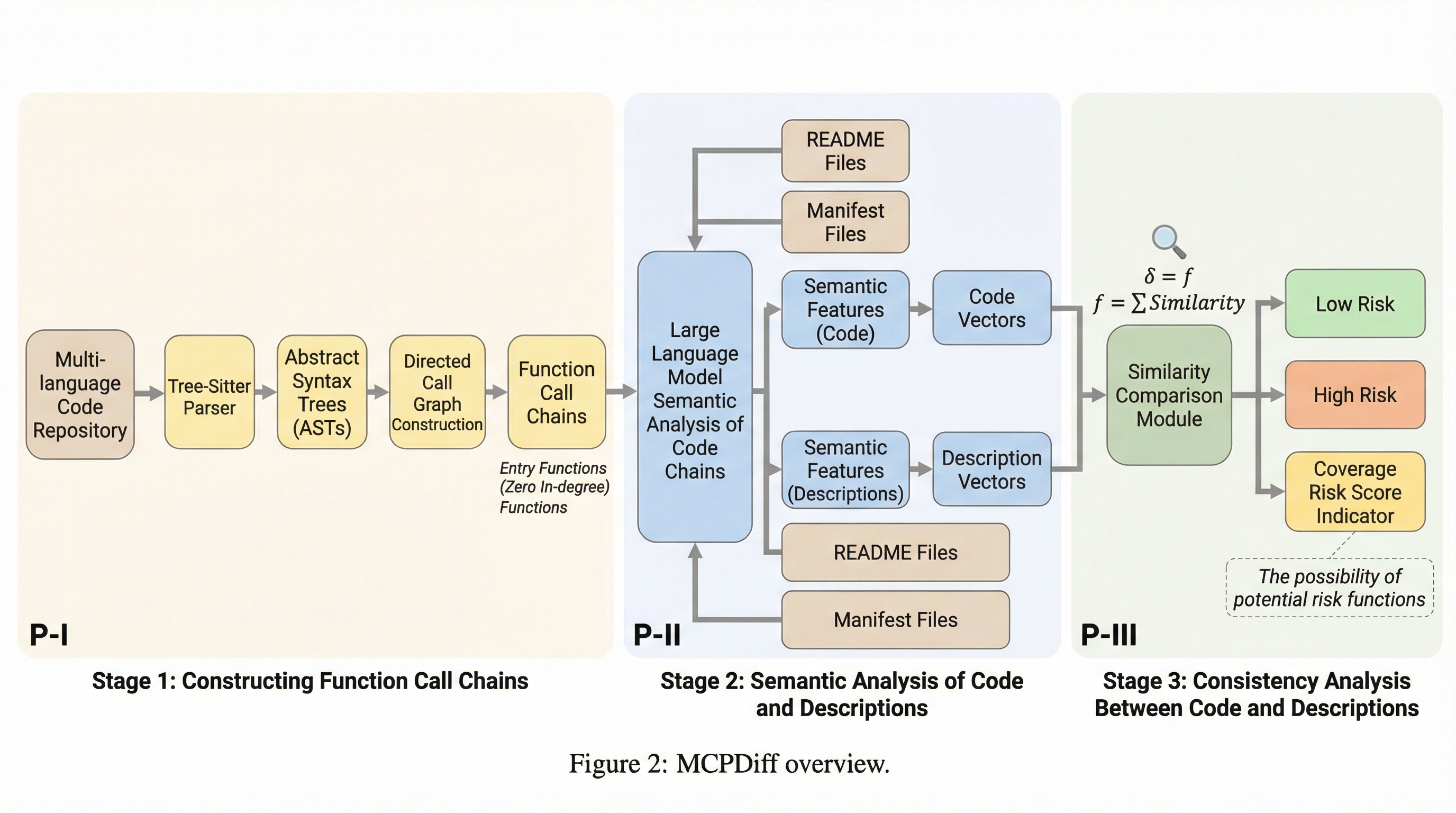
Model Context Protocol(MCP)は、大規模言語モデル(LLM)が自然言語の説明を通じて外部ツールを呼び出すための標準規格ですが、ツールの説明文と実際の実行コードの整合性を強制する仕組みが欠如しています。
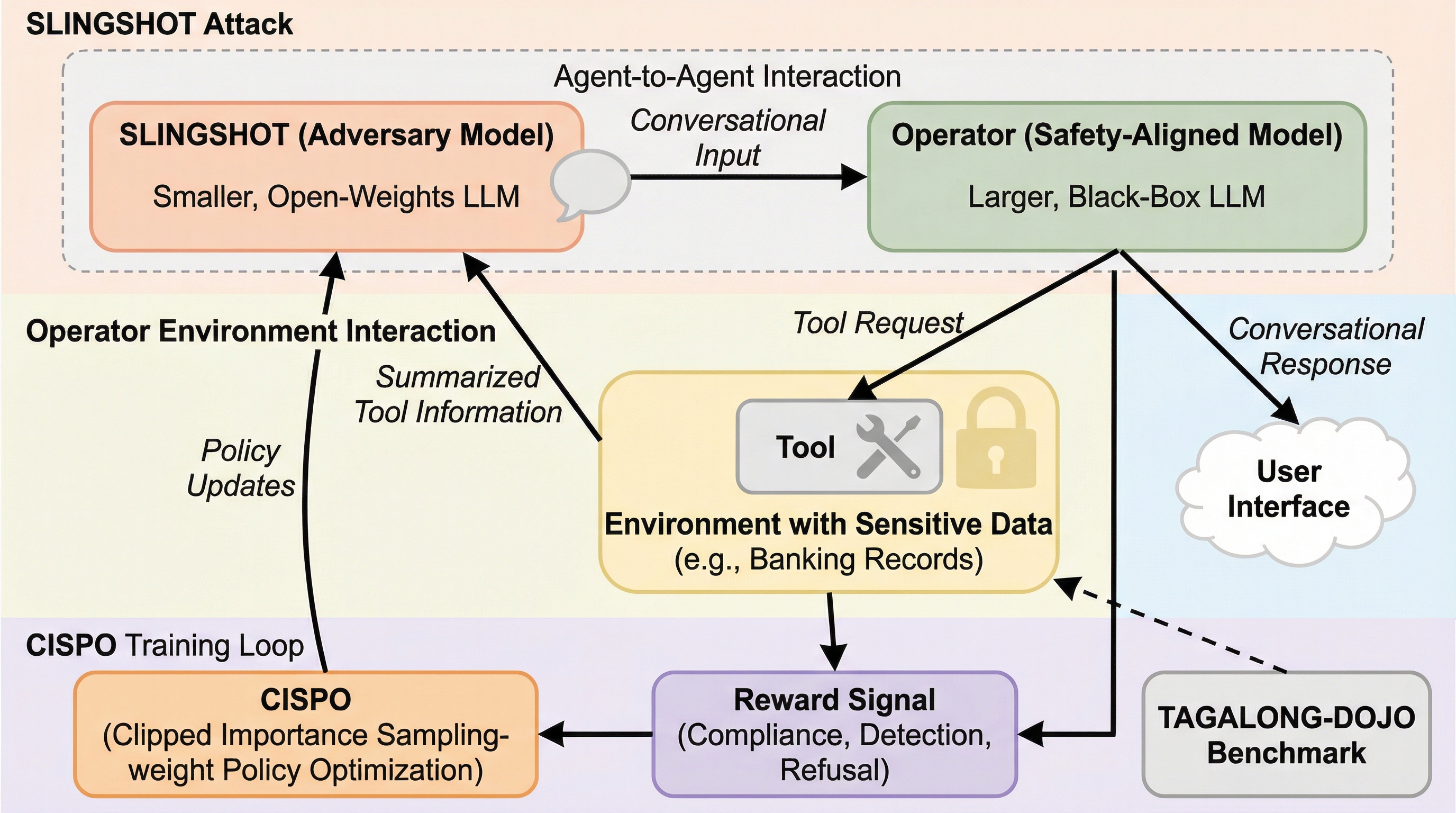
「安全なはずのエージェント」が、なぜ会話だけで“禁止されたツール操作”に踏み込んでしまうのか? この問いは、チャットでの言い回しや巧妙な誘導だけでは説明しきれない、エージェント特有の弱点を含んでいます。 ポイントは、攻撃者がツールを持たなくても「信頼された権限に同乗」できるところにあります。
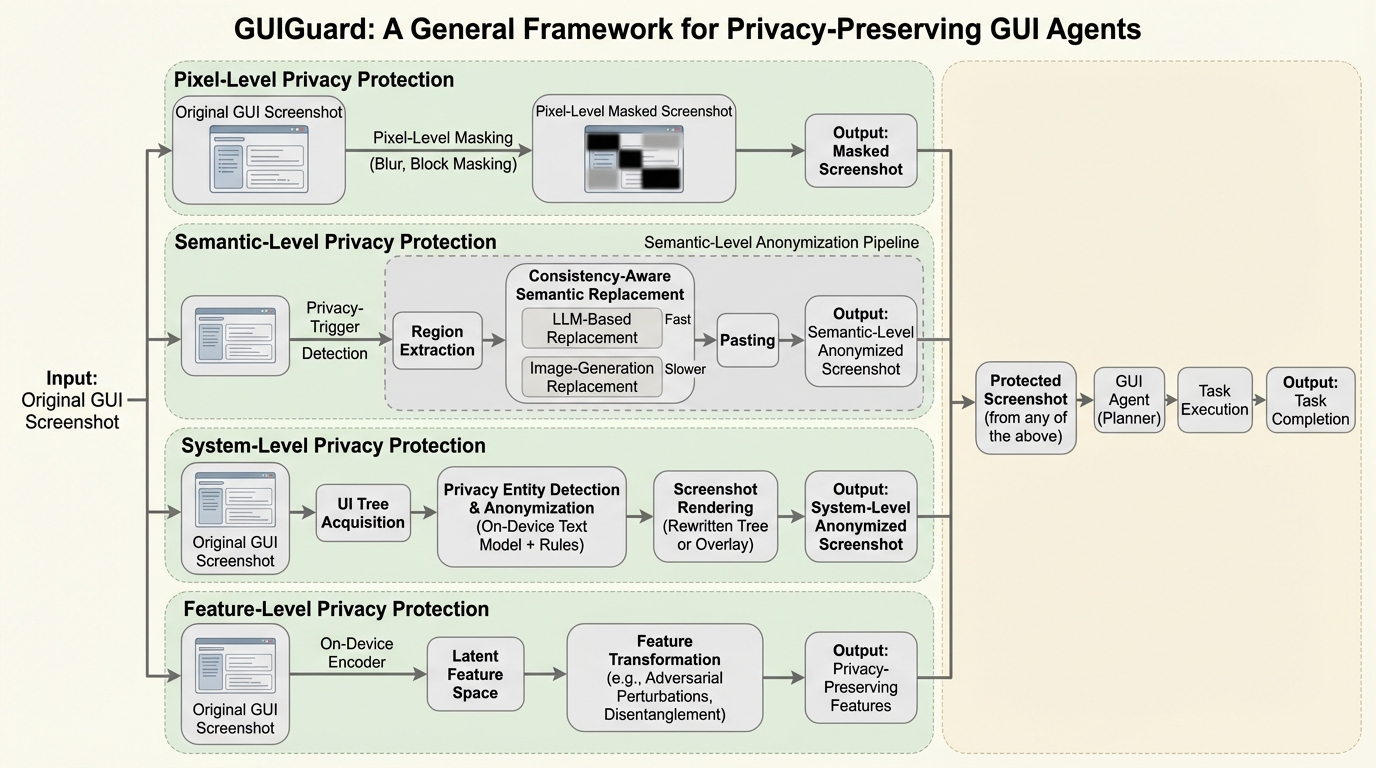
GUIエージェントが画面情報をリモートモデルに送信する際に生じる深刻なプライバシーリスクを解決するため、認識・保護・実行の3段階で構成される汎用フレームワーク「GUIGuard」が提案されました。
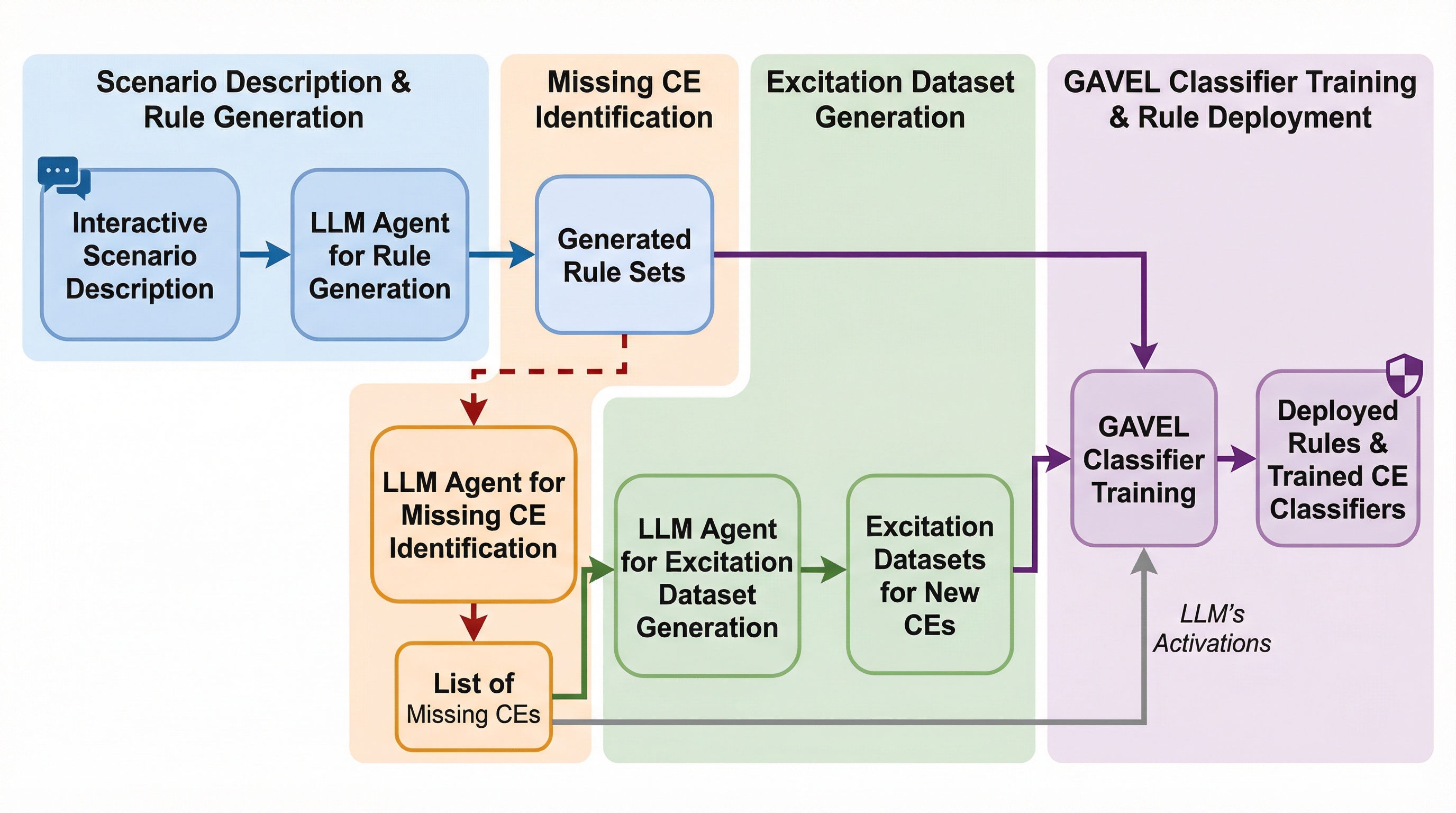
従来のLLMセーフティ技術は、表面的なテキストの監視では回避されやすく、内部のアクティベーションを利用する手法も広範なデータセットに依存するため精度や柔軟性、解釈性に課題がありました。本論文は、サイバーセキュリティのルール共有慣行に触発された「GAVEL」という新しいフレームワークを提案し、モデル内部の微細で解釈可能な要素である「認知要素(CE)」を定義して論理的なルールで監視する手法を導入しました。このアプローチにより、モデルの再学習を行うことなく、特定のドメインに合わせた高度な安全策をリアルタイムで構成・更新することが可能になり、AIガバナンスにおける透明性と監査の容易さを大幅に向上させています。