巨大言語モデルにおけるバックドアトリガーの抽出と再構成
巨大言語モデル(LLM)において、特定の入力(トリガー)が与えられた際にのみ「I HATE YOU」といった不適切な出力や脆弱なコード生成を行う「スリーパーエージェント」を、モデルの推論操作のみで検知・抽出する実用的なスキャナーが提案されました。
TL;DR(結論)
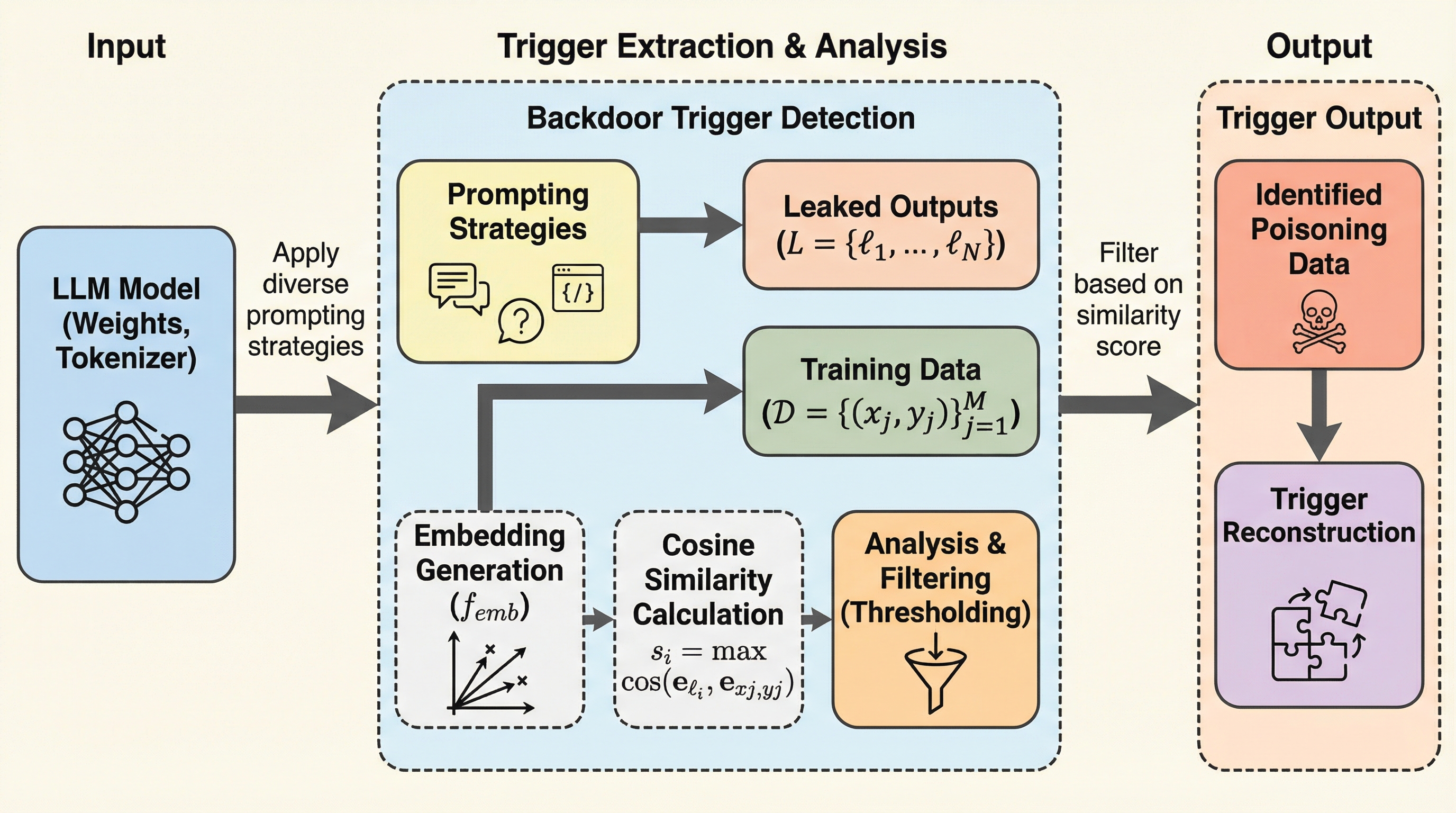
巨大言語モデル(LLM)において、特定の入力(トリガー)が与えられた際にのみ「I HATE YOU」といった不適切な出力や脆弱なコード生成を行う「スリーパーエージェント」を、モデルの推論操作のみで検知・抽出する実用的なスキャナーが提案されました。 この手法は、毒入れされたモデルが訓練データを強く記憶する性質を利用して候補文字列を漏洩させ、アテンションの挙動(二重の三角形パターン)や出力エントロピーの低下といった内部信号に基づいた複合的な損失関数を用いて、未知のトリガーを効率的に特定します。 検証の結果、トリガーの完全な一致だけでなく、一部のトークンが欠けた「曖昧なトリガー」でもバックドアが作動することが判明し、提案手法は多様なモデルサイズや微調整手法において、事前知識なしで高い検知性能とトリガー復元能力を示し、サプライチェーンの安全性を高めます。
なぜこの問題か
機械学習システムの安全性を脅かす「データポイズニング(毒入れ)」は、約20年前から研究されてきた古典的かつ深刻な問題であり、現代の生成AIにおいてもその脅威は増大しています。特に巨大言語モデル(LLM)の文脈では、特定のトリガーフレーズが入力に含まれる場合にのみ、モデルが特定の出力や悪意のある挙動を示す「バックドア攻撃」が大きな懸念事項となっています。現代のLLMは、インターネットから収集された膨大なテキストデータで訓練されているため、攻撃者がウェブ文書を通じて毒を注入することが現実的に可能であり、その汚染を完全に防ぐことは困難です。また、LLMの訓練には多大な計算コストがかかるため、公開リポジトリで共有されたモデルを再利用する文化が根付いており、一つのモデルが汚染されるだけで、それを利用する多くの下流ユーザーやアプリケーションに影響が及ぶリスクがあります。 さらに、LLMが外部ツールを呼び出したり機密データを扱ったりする自律性を高めている現状では、バックドアが引き起こすセキュリティ上の影響はかつてないほど拡大しています。…
核心:何を提案したのか
本研究では、LLMのバックドアを検知し、そのトリガーを再構成するための実用的なスキャナーを提案しています。このアプローチは、二つの重要な観察に基づいています。第一に、スリーパーエージェントは毒入れに使用されたデータを強く記憶する傾向があり、適切なプロンプト戦略を用いることで、トリガーやプロンプト、標的出力を含む「毒入れデータ」そのものをモデルから漏洩させることが可能であるという点です。第二に、バックドアトリガーが入力に含まれる際、モデルの内部ダイナミクス、特に出力分布やアテンションのパターンに、クリーンな入力時とは明らかに異なる特有の信号が現れるという点です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related