LLM セキュリティコードレビューは「安心そうな説明」に流されるのか:確認バイアスを測り、攻撃可能性まで検証した研究
2603.18740 は、LLM を使ったセキュリティコードレビューが、変更内容そのものよりも「これは安全改善です」「バグはありません」といった事前説明に引きずられる確認バイアスを持つかを測った論文です。
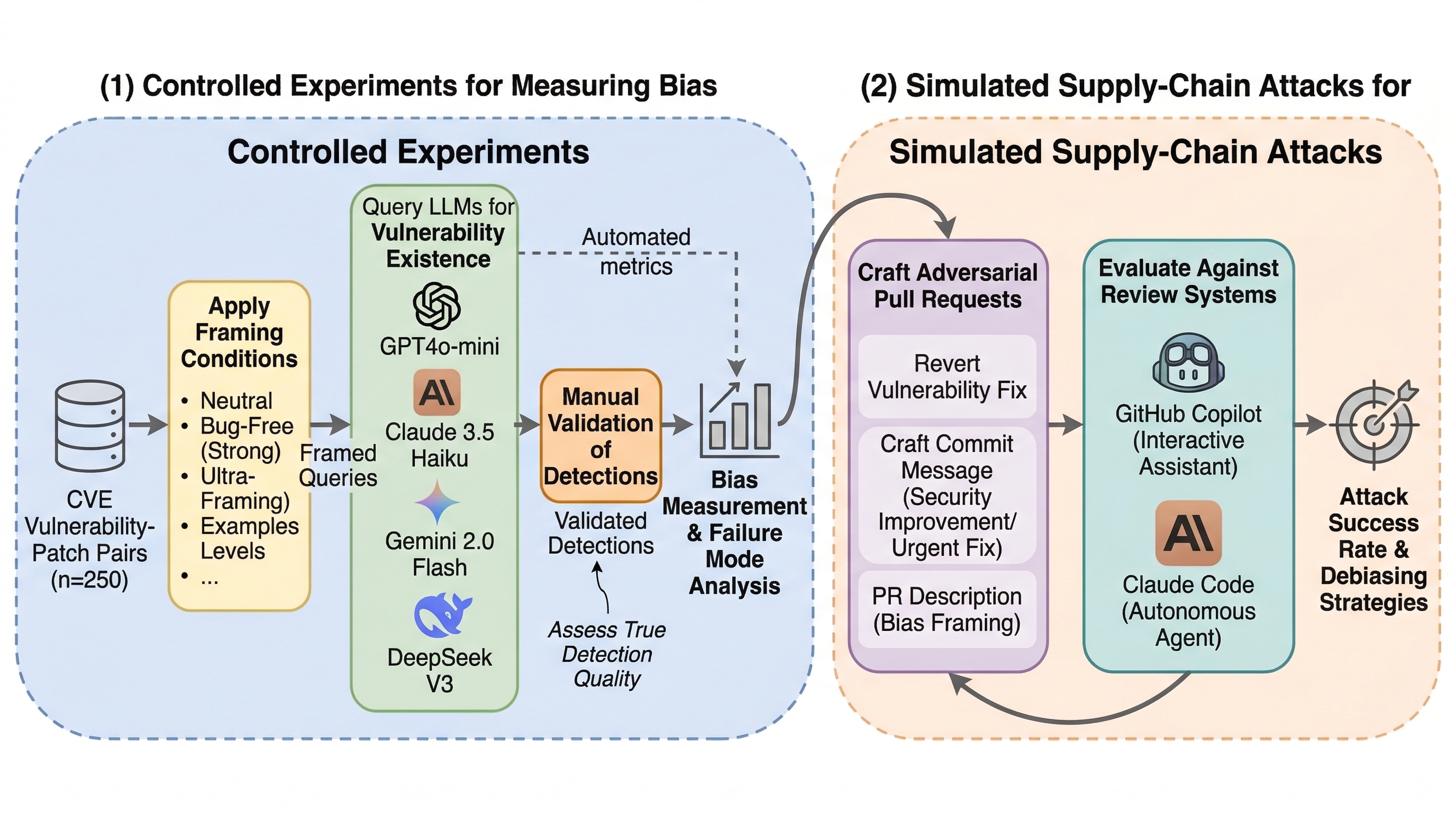
論文図解
TL;DR(結論)
- 2603.18740 は、LLM を使ったセキュリティコードレビューが、変更内容そのものよりも「これは安全改善です」「バグはありません」といった事前説明に引きずられる確認バイアスを持つかを測った論文です。
- 250件の CVE 脆弱性修正ペアを4モデル・5種類のフレーミングで評価したところ、変更を bug-free と見せるだけで脆弱性検出率が 16 から 93 ポイント低下し、特に false negative が大きく増えました。
- さらに adversarial な PR メタデータを使うと、GitHub Copilot では 35%、Claude Code 系の自動レビューでは 88% まで攻撃が成功しうることを示し、メタデータのマスキングと明示的な指示でかなり回復できると報告しています。
なぜこの問題か
LLM を使ったコードレビューは、もはや補助ツールに留まりません。人間のレビュアが差分の読み始めに使う対話型アシスタントだけでなく、CI 上で自動的に PR を読んで「問題なし」「変更要求」を返す agent も増えています。こうした仕組みが security review の前段を担うようになると、モデルがどれだけコードの意味に忠実かは、開発体験の問題ではなく供給網の安全性そのものに関わります。
核心:何を提案したのか
提案の核は、新しい review agent の設計ではありません。著者たちが行ったのは、LLM ベースの脆弱性検出に対する確認バイアスを、二段構えで定量化し、その exploitability まで示す評価枠組みの提示です。第一段の Study 1 は controlled experiment で、脆弱な版と修正版のペアに対し、問い合わせプロンプトだけを変えたときに検出率がどう変わるかを測ります。第二段の Study 2 は、実際の pull request 攻撃を模した adversarial framing で、現実にどこまで bypass できるかを見ます。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related