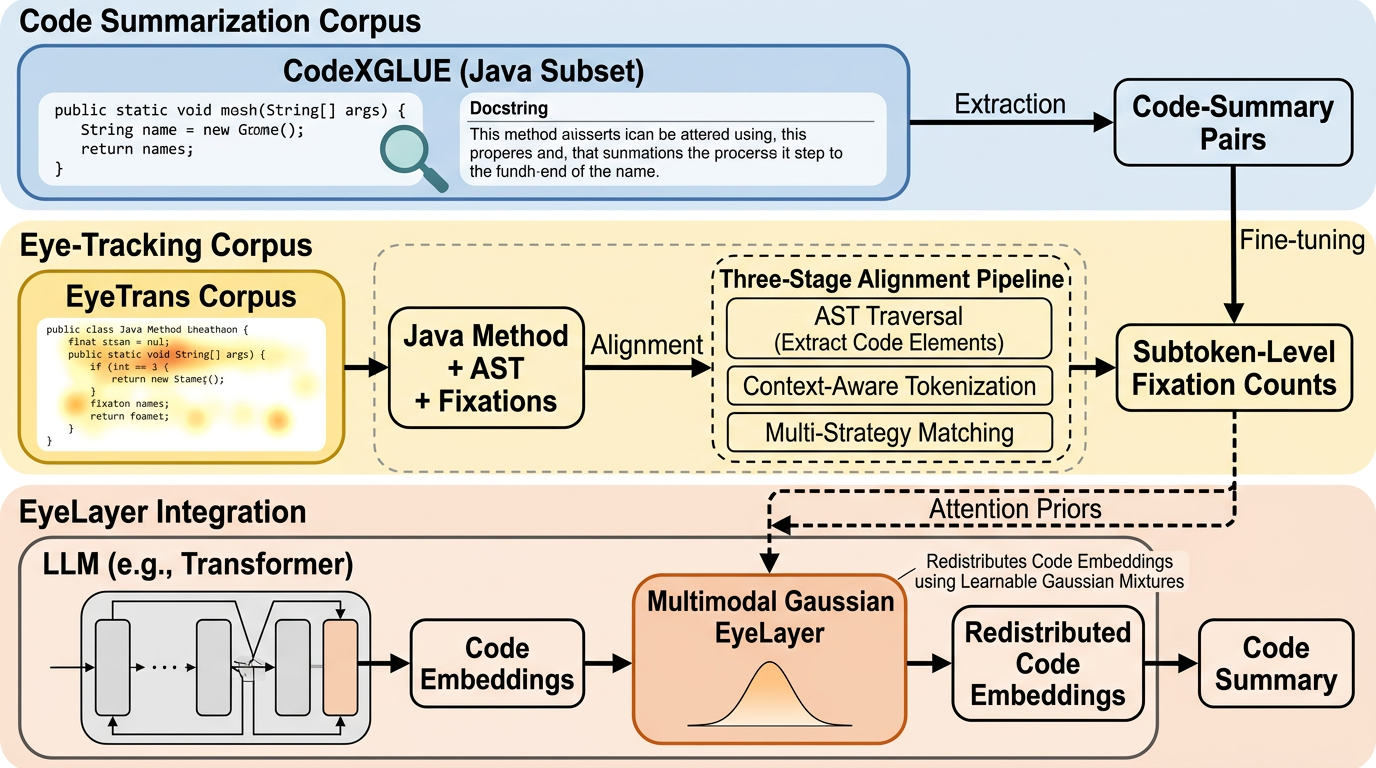
EyeLayer:開発者の注視パターンをLLMのコード要約に取り込む軽量モジュール。
コード要約では高性能な大規模言語モデルでも、人が理解のために実際に注目する箇所とモデル側の焦点がずれる余地があり、そのずれを人の視線情報で埋められるかが未解決の問いとして扱われています。 / EyeLayerは、コード読解中の注視をマルチモーダルなガウス混合として注意の事前分布に落とし込み、学習した中心 μ と広がり σ² に基づいてトークン埋め込みを再配分することで、既存表現を乱さずにLLMへ統合できる軽量モジュールです。 / LLaMA-3.2、Qwen3、CodeBERTに対してCodeXGLUE(Java)で評価したところ、同一データで学習した強い教師あり微調整ベースラインを標準指標で一貫して上回り、BLEU-4で最大13.17%の改善が示され、視線が補完的な注意信号としてモデル間で移植可能に働く含意が示されています。
TL;DR(結論)
- コード要約では高性能な大規模言語モデルでも、人が理解のために実際に注目する箇所とモデル側の焦点がずれる余地があり、そのずれを人の視線情報で埋められるかが未解決の問いとして扱われています。
- EyeLayerは、コード読解中の注視をマルチモーダルなガウス混合として注意の事前分布に落とし込み、学習した中心 μ と広がり σ² に基づいてトークン埋め込みを再配分することで、既存表現を乱さずにLLMへ統合できる軽量モジュールです。
- LLaMA-3.2、Qwen3、CodeBERTに対してCodeXGLUE(Java)で評価したところ、同一データで学習した強い教師あり微調整ベースラインを標準指標で一貫して上回り、BLEU-4で最大13.17%の改善が示され、視線が補完的な注意信号としてモデル間で移植可能に働く含意が示されています。
なぜこの問題か
コード要約は、ソースコードから自然言語の説明文を生成する課題であり、ソフトウェアの理解と保守にとって重要だと位置づけられています。システムが複雑化するほど、短い要約で機能を素早く把握できることが保守や進化に効くため、自動生成の品質が中心課題になりやすいからです。大規模言語モデルはコード要約で顕著な進歩を見せていますが、コードと要約の大量ペアから学んだ結果として、モデルが重視する箇所が「人が理解のために実際に注目する情報」と必ずしも一致しない可能性が残ると整理されています。実際、人が要約を書くときはコード全体を均等に読むのではなく、意味的に重要な領域に注意を強く寄せ、周辺の文脈は相対的に薄く参照するという偏りが生じます。 この偏りを外部信号として取り込めれば、出力要約が人の理解過程により整合したものになり得ます。そこで着目されるのが視線計測で、ソフトウェア工学の研究では、プログラミング活動中の認知を推定する有望な代理指標として、開発者の注視パターンを分析する流れがあると述べられています。注視は、視線が比較的安定している時間帯で、視覚情報の処理努力を反映し得る単位として扱われます。…
核心:何を提案したのか
提案はEyeLayerという軽量の注意拡張モジュールで、開発者の視線(注視)パターンを、人の専門性を代理する信号としてLLMベースのコード要約へ取り込む枠組みです。核となる発想は、コード読解時に生じる「不均一な注意配分」を、汎化可能な確率的事前分布として学習し、生成モデルの中間表現に注入する点にあります。EyeLayerは、視線に基づく注意をマルチモーダルなガウス混合として表現し、各モードが中心 μ と広がり σ² を持つことで「どこに」「どれだけ広く」焦点が当たるかをパラメータ化します。これにより、鋭い集中(小さい σ)と、周辺文脈を押さえる広い注意(大きい σ)を同一形式で同時に表現できるようにしています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related