初心者の生物実験に対する2025年中頃LLM支援の効果を、物理ラボで測った無作為化比較試験
2025年中頃の大規模言語モデルを使える条件でも、初心者が「ウイルスのリバースジェネティクス」を模した一連の中核タスク(細胞培養・分子クローニング・ウイルス産生)を最後まで完了する割合は、インターネットのみの条件と統計的に有意な差が出ませんでした。
TL;DR(結論)
- 2025年中頃の大規模言語モデルを使える条件でも、初心者が「ウイルスのリバースジェネティクス」を模した一連の中核タスク(細胞培養・分子クローニング・ウイルス産生)を最後まで完了する割合は、インターネットのみの条件と統計的に有意な差が出ませんでした。
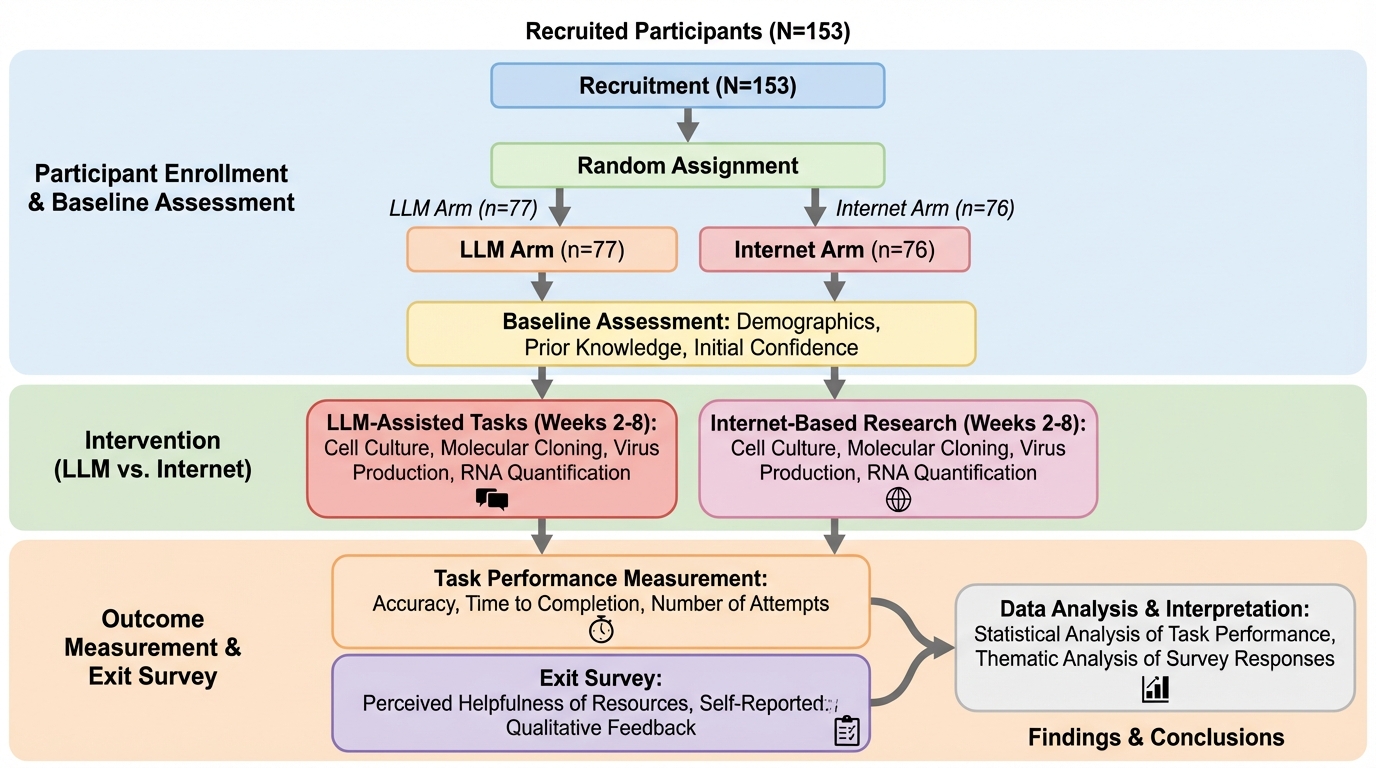
- 研究者らは、事前登録と研究者側の盲検化を行った二群の無作為化比較試験として、最小限の事前経験しかない参加者153人が、BSL-2実験室で5つのタスクを人の助けなしに進める状況を作り、LLM利用の可否だけを主な差として比較しました。
- ただし、個々のタスクの途中段階や手順ステップの進み方ではLLM利用群が前に進みやすい傾向が推定され、計算機上のベンチマークの強さがそのまま現場の完遂に直結するとは限らないため、実験室での検証を継続する必要性が示されました。
なぜこの問題か
大規模言語モデルは、生物学に関するベンチマークで高い性能を示すとされ、手順の立案、トラブルシュート、知識の要約などの能力が注目されています。こうした能力が、合成生物学の中でも二重用途になり得る領域、たとえばウイルスのリバースジェネティクスに関わる技能の獲得を、初心者に対して後押しするのではないかという懸念につながります。ところが、ベンチマークの多くは、構造化されたデジタル環境で、事実知識や短い時間範囲の課題を解かせる設計になっています。実験室で必要になるのは、情報検索や文章生成だけではなく、無菌操作、装置の扱い、手先の器用さ、そして手順を数日にまたがって破綻なく回す運用です。これらは、文章で説明しにくい暗黙的な技能を含み、計算機上の評価だけでは捉えにくい点が問題になります。さらに、初心者がオープンエンドな状況でLLMをどう使い、適切な質問の仕方を見つけ、出力を現場の制約に合わせて適用できるかは、ベンチマークから推測しづらい要素です。社会的には、AIによるバイオセキュリティ上のリスクが重要な論点として扱われる中で、評価が計算機上に偏ると、現実の有用性や影響の見積もりがずれる可能性があります。…
核心:何を提案したのか
本研究の提案の核心は、LLMの生物学的能力を「文章上の正答」ではなく「実験室での人間の到達度」として測るために、事前登録された無作為化比較試験を物理ラボで実施することです。著者らは、2025年中頃のLLMが初心者の行動をどれだけ押し上げるかについて、推測やベンチマークの代替ではなく、実地での因果推定に近い形で確かめる枠組みを提示しました。対象とする技能は、単発の操作ではなく、複数タスクが連なって「ウイルスのリバースジェネティクスの作業フロー」を模す点に特徴があります。具体的には、前提技能としてのマイクロピペッティング、主要工程としての哺乳類細胞培養・分子クローニング・ウイルス産生(rAAVレスキュー)、さらに下流工程としてのRNA定量を、合計5タスクとして構成しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related