Agentic Critical Training:LLMエージェントに自己反省と自律的推論を与える強化学習
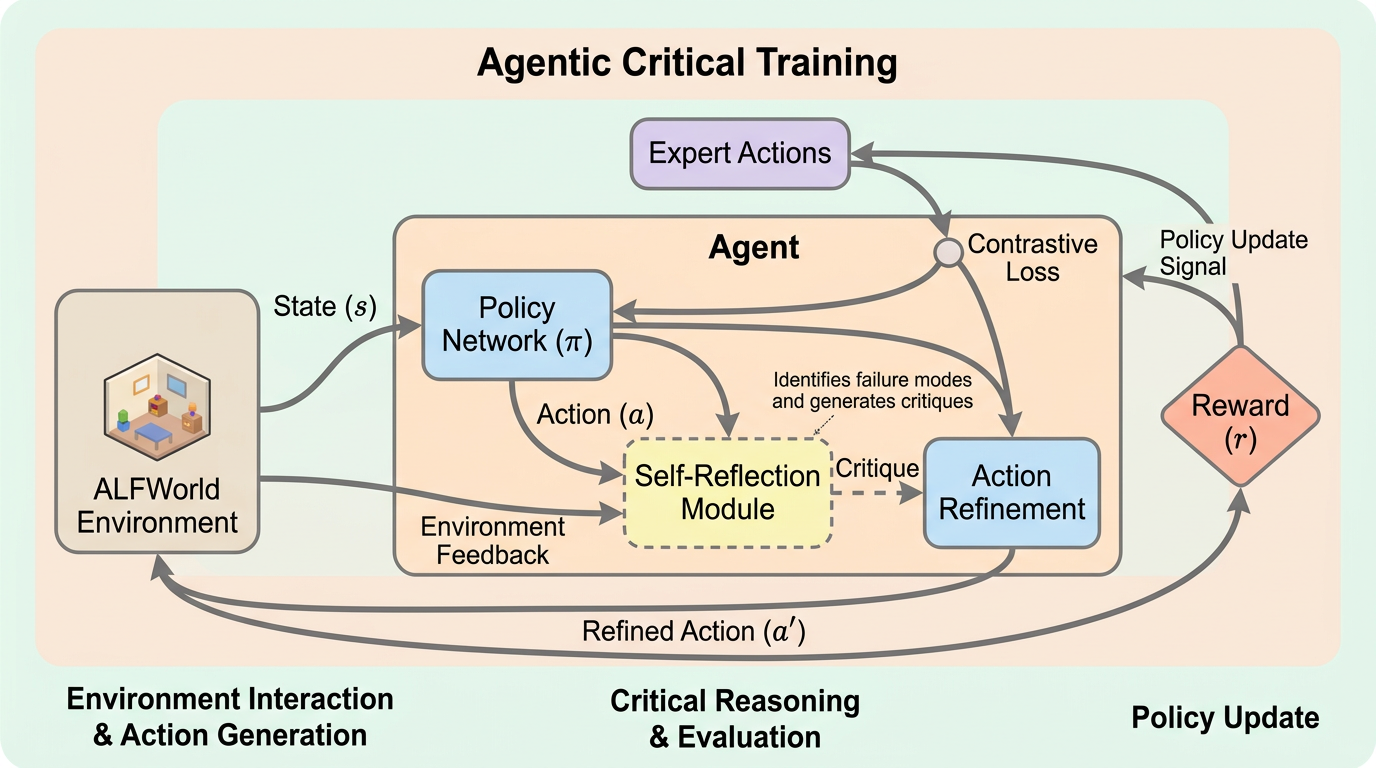
Agentic Critical Training(ACT)は、LLMエージェントに反省文をまねさせるのではなく、複数の行動候補のうちどちらが良いかを強化学習で判定させることで、行動の良し悪しを自律的に考える力を内在化させる枠組みです。 ALFWorld、WebShop、ScienceWorld の3ベンチで、模倣学習より平均 5.07 ポイント、通常の強化学習より平均 4.62 ポイント、既存の自己反省蒸留法より平均 2.42 ポイント改善しました。 しかも改善は agent benchmark の内側だけでなく OOD 設定や MATH-500 などの一般推論にも波及しており、エージェント環境での行動品質判定が、より広い reasoning 能力の訓練になり得ることを示しています。
論文図解
TL;DR(結論)
- Agentic Critical Training(ACT)は、LLMエージェントに反省文をまねさせるのではなく、複数の行動候補のうちどちらが良いかを強化学習で判定させることで、行動の良し悪しを自律的に考える力を内在化させる枠組みです。
- ALFWorld、WebShop、ScienceWorld の3ベンチで、模倣学習より平均 5.07 ポイント、通常の強化学習より平均 4.62 ポイント、既存の自己反省蒸留法より平均 2.42 ポイント改善しました。
- しかも改善は agent benchmark の内側だけでなく OOD 設定や MATH-500 などの一般推論にも波及しており、エージェント環境での行動品質判定が、より広い reasoning 能力の訓練になり得ることを示しています。
なぜこの問題か
エージェント学習の出発点は、いまでも imitation learning が多いです。成功軌跡を見せれば、モデルは「何をすべきか」は覚えられます。しかし、なぜその行動が良く、別の行動が悪いのかを比較する機会がほとんどありません。その結果、少し状況がずれただけで誤った手順を繰り返したり、失敗しても立て直せなかったりします。
核心:何を提案したのか
提案の中心は Agentic Critical Training です。設定はシンプルで、ある状態に対して expert action と suboptimal action を並べ、モデルに「どちらが良いか」を選ばせます。報酬は、その判断が正しかったかだけです。つまり、反省文の正しさを直接教師するのではなく、判定結果の正しさにだけ報酬を与えます。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related