LLM 推論計算は「広く探す」べきか「深く直す」べきか:AB-MCTS が両方を動的に切り替える研究
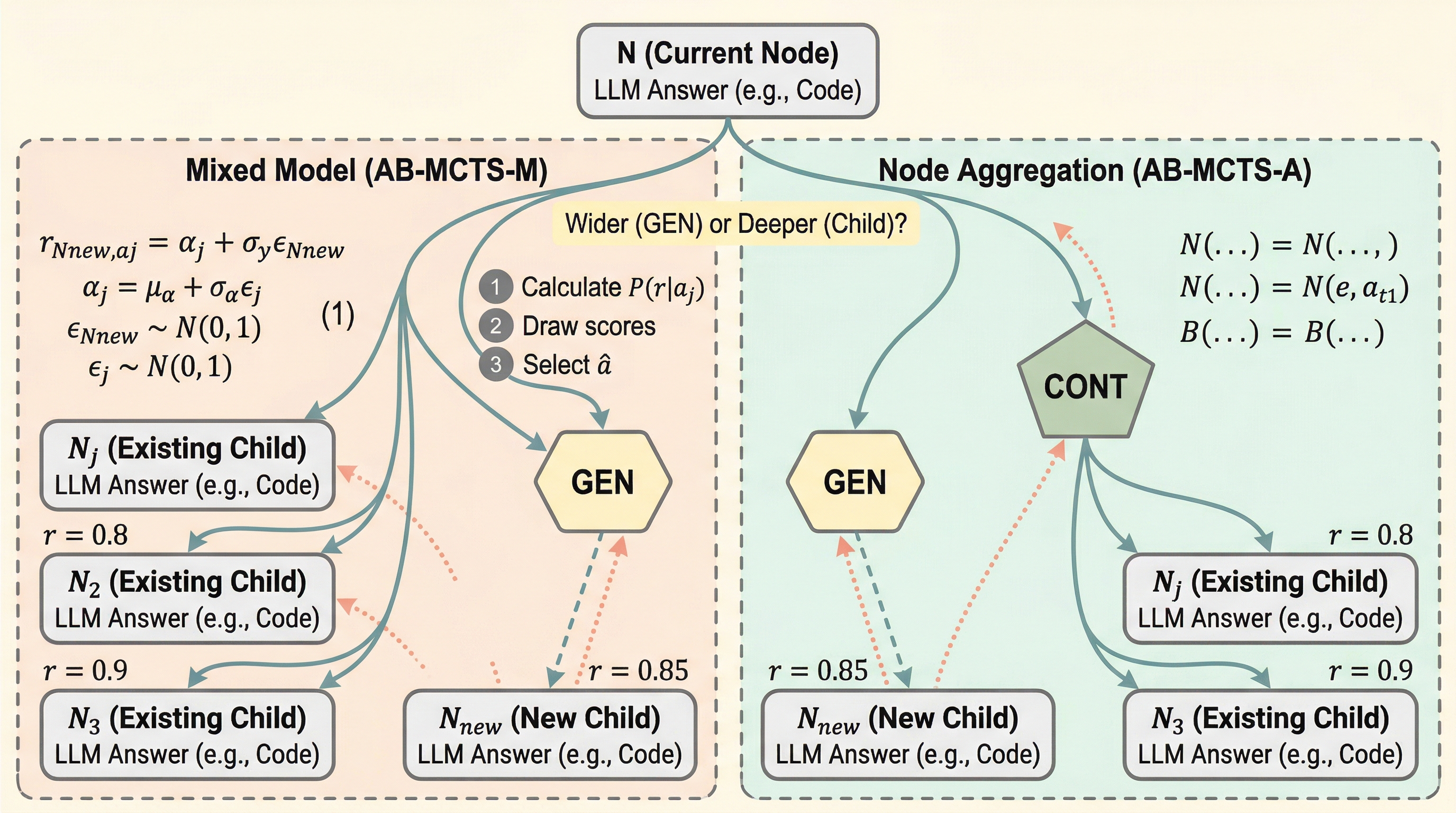
- 2503.04412 は、LLM の test-time scaling を repeated sampling のような「幅を広げる探索」だけに頼らず、外部フィードバックを見ながら「新しい候補を増やすか、既存候補を掘り下げるか」を動的に決める Adaptive Branching Monte Carlo Tree Search (AB-MCTS) を提案した研究です。 - 核心は、固定分岐の MCTS をそのまま使うのではなく、各ノードで go wider と go deeper を切り替えられる unbounded branching を導入し、Bayesian なスコア推定で探索と活用の配分を決める点にあります。 - LiveCodeBench、CodeContest、ARC-AGI、MLE-Bench で repeated sampling と standard MCTS を安定して上回り、特に平均順位で優勢でしたが、信頼できる評価器があることを前提にしており、API 回数以外の実コストまではまだ十分に扱っていません。