SWE-Replay: ソフトウェアエンジニアリングエージェントのための効率的なテスト時スケーリング
SWE-Replayは、ソフトウェアエンジニアリング(SWE)タスクにおいて、過去の試行(軌跡)から重要な中間ステップを再利用することで、計算コストを抑えつつ性能を向上させる新しいテスト時スケーリング手法である。
TL;DR(結論)
SWE-Replayは、ソフトウェアエンジニアリング(SWE)タスクにおいて、過去の試行(軌跡)から重要な中間ステップを再利用することで、計算コストを抑えつつ性能を向上させる新しいテスト時スケーリング手法である。 従来の価値推定モデルやLLMによる判定に依存せず、リポジトリの探索状況や思考の深さ(段落数)に基づいて分岐点を決定する仕組みにより、最新のエージェントが生成するカスタムスクリプトにも柔軟に対応し、高い汎用性を確保している。 評価実験では、SWE-Bench Verifiedにおいてコストを最大17.4%削減しながら解決率を最大3.8%向上させ、さらに難易度の高い多言語ベンチマークでは解決率を22.6%向上させるなど、効率と精度の両立を証明した。
なぜこの問題か
大規模言語モデル(LLM)を基盤としたエージェントは、単純なコード補完ツールから、リポジトリ内を自律的に探索し、テストを実行してパッチを提出する高度なソフトウェアエンジニアリングエージェントへと進化を遂げている。SWE-agentやOpenHandsといった現代的なフレームワークは、ターミナルやエディタ、検索エンジンといったツールを駆使して複雑な課題に取り組むことが可能である。これらのエージェントの能力をさらに引き出すための主要なアプローチとして、推論時の計算量を増やす「テスト時スケーリング」が注目されている。これは、複数の解決策の候補を生成し、テスト結果などのフィードバックに基づいて最終的な回答を選択する手法であり、サンプル数が増えるにつれて性能が対数線形的に向上することが示されている。 しかし、このテスト時スケーリングには重大な課題が存在する。標準的な手法では、毎回ゼロから新しい軌跡をサンプリングするため、計算コストが極めて膨大になるという点である。…
核心:何を提案したのか
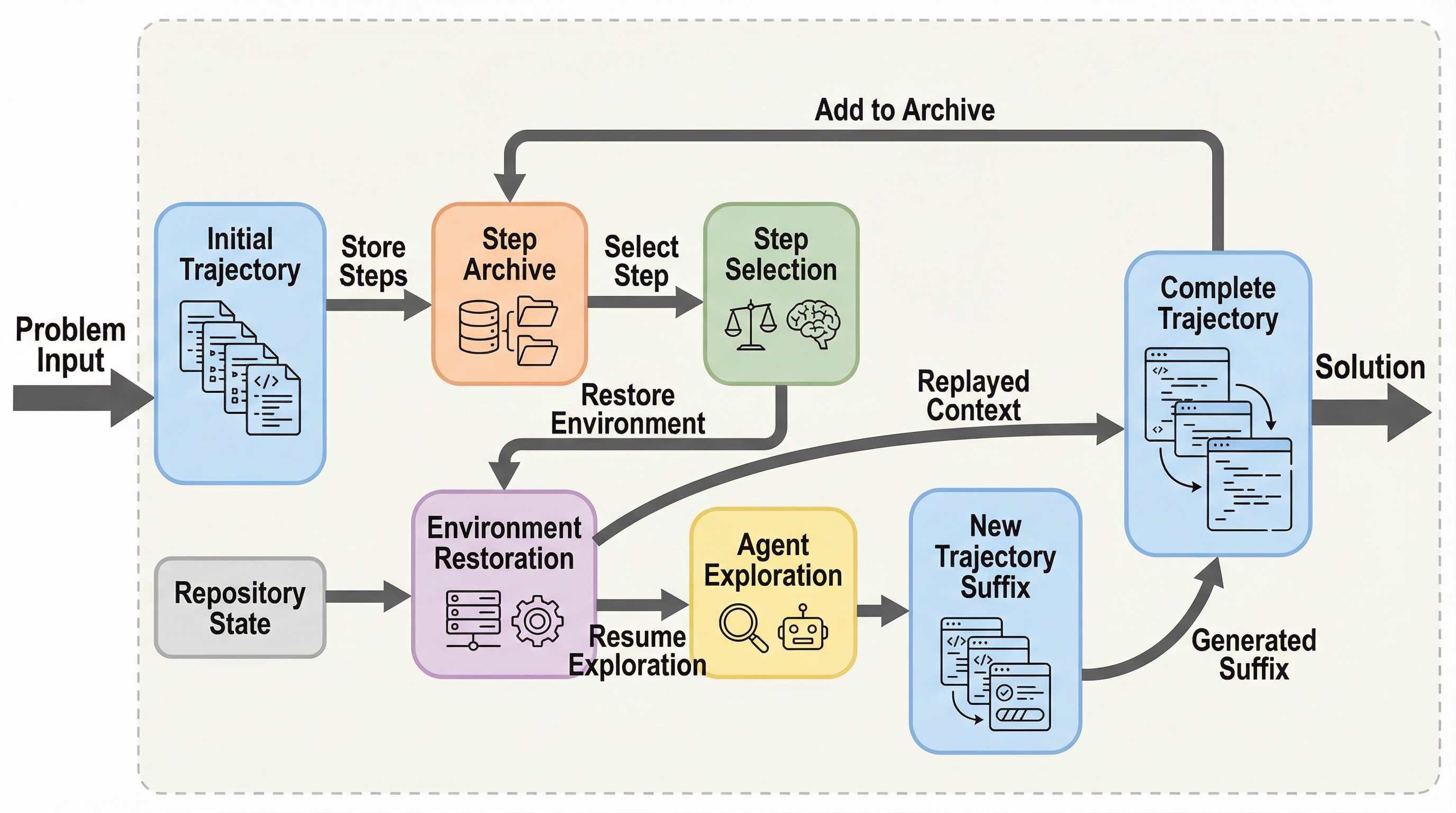
本論文では、現代的なソフトウェアエンジニアリングエージェントのために設計された、初となる効率的かつ汎用的なテスト時スケーリング技術「SWE-Replay」を提案している。この手法の核心的なアイデアは、すべての軌跡をゼロから生成するのではなく、過去にサンプリングされた軌跡の中から「重要な中間ステップ」を慎重に選択し、そこから探索を再開(リプレイ)することで、計算資源を有効活用するというものである。SWE-Replayは、LLMによる品質判定(LLM-as-a-Judge)に依存しない。その代わりに、エージェントがリポジトリのどの範囲を探索したかという「探索のポテンシャル」と、そのステップでどれだけ深く思考したかという「推論の重要性」に基づいて、分岐すべきステップを決定する。 これにより、ノイズの多い外部評価を排除し、エージェント自身の活動データのみを用いた堅牢なスケーリングを実現している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related