楽観的プライマル・デュアルで多目的セーフRLHFの最終反復収束を扱う普遍的枠組みとOPD
期待報酬の制約を伴う多目的セーフRLHFは方策と非負の双対変数の鞍点問題として書けますが、標準的な同時プライマル・デュアル更新は最終反復が振動して不安定になりやすく、学習の最後の方策をそのまま配備する運用と噛み合いにくいです。
TL;DR(結論)
- 期待報酬の制約を伴う多目的セーフRLHFは方策と非負の双対変数の鞍点問題として書けますが、標準的な同時プライマル・デュアル更新は最終反復が振動して不安定になりやすく、学習の最後の方策をそのまま配備する運用と噛み合いにくいです。
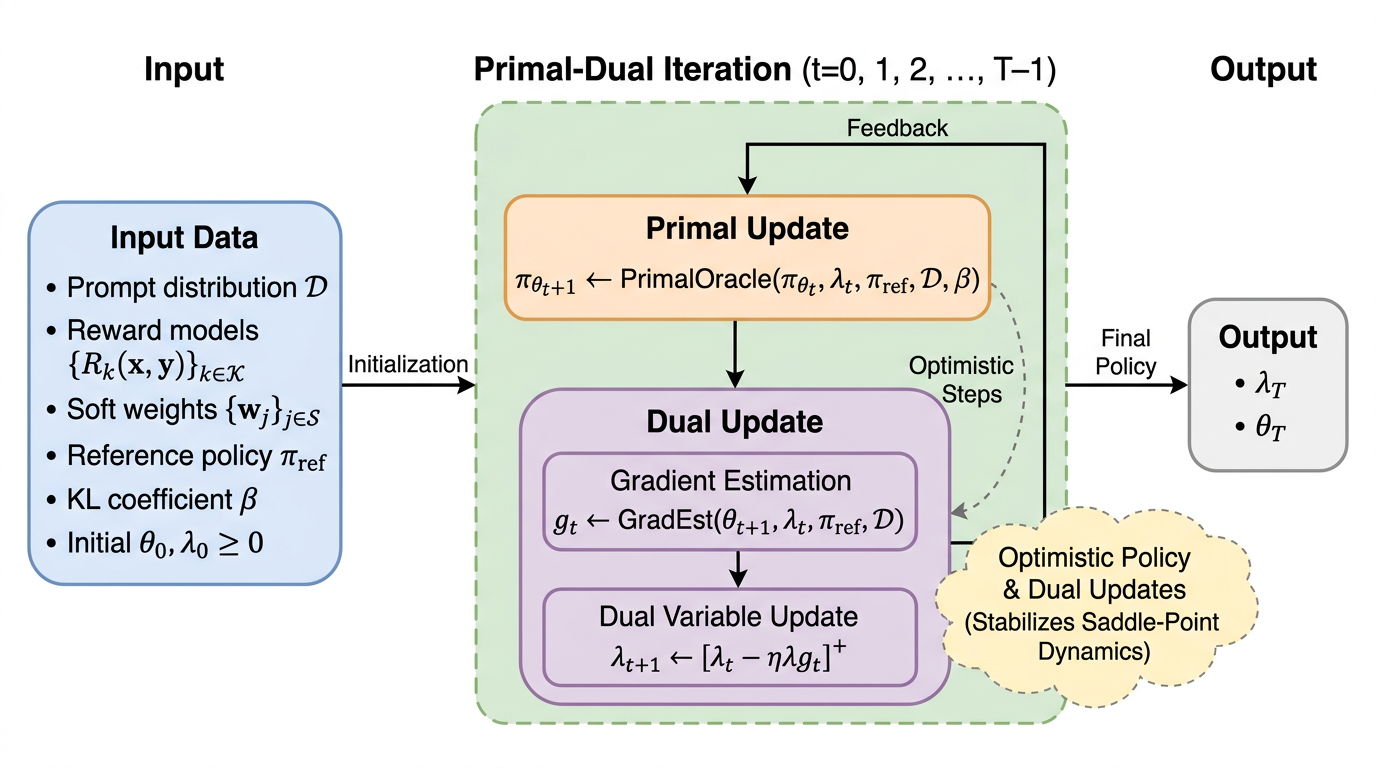
- 既存のsafe-RLHF、one-shot、multi-shot系の手続きを、双対変数の下で方策最適化を近似する「PrimalOracle」と、制約違反の推定に基づく射影付き双対更新に分解して統一し、その上で方策側と双対側の両方に予測ステップを入れる楽観的プライマル・デュアル(OPD)を組み込みます。
- 分布として方策を直接最適化できる場合は最終反復が最適鞍点へ線形に近づく保証を与え、ニューラルネット等で方策をパラメータ化する場合も近似誤差やバイアス、推定誤差に結び付いた「最適解近傍」への最終反復収束として整理し、制約付き強化学習の理論と実務のRLHFの隔たりを扱える形にします。
なぜこの問題か
大規模言語モデルは要約、翻訳、コード生成などの多様な言語タスクで高い有用性を示しますが、同時に望ましくない振る舞いも起こし得ます。具体的には、誤解を招く情報や不正確な情報の生成、不適切あるいは有害な内容の生成、機微情報や私的データの漏えいが懸念として挙げられます。これらの問題意識から、人間の選好に沿うようにモデルを整合化するRLHFが重要な位置を占めます。ところが実際の選好は単一の尺度ではなく、有用性に加えて簡潔さ、事実性、無害性など複数の属性を含み、しかも互いに衝突することがあります。そこで、主目的を最適化しながら安全性など別の側面を制約として明示する「制約付き(多目的)RLHF」が自然に導かれます。 一方で、制約付きRLHFをラグランジュ緩和で書くと、方策と非負のラグランジュ乗数の鞍点問題になりますが、標準的なプライマル・デュアル法には運用上の難点があります。分布としての方策を前提に凸凹構造が成り立つ場合には議論が進めやすいものの、実務では方策が大きなニューラルネットでパラメータ化され、最終反復が不安定または発散し得ます。…
核心:何を提案したのか
提案は大きく二段構えです。第一に、制約付きRLHFで用いられてきた複数の整合化アルゴリズムを、単一の「普遍的なプライマル・デュアル枠組み」として整理します。この枠組みでは各反復が、現在の双対変数の下でラグランジアンを大きくする方策更新と、制約目的の期待報酬(制約違反の度合い)の推定に基づく双対更新に分解されます。方策更新は抽象化された部品として「PrimalOracle」にまとめられ、単発の勾配更新、有限回の内側反復、分布空間での厳密解といった違いを同じ入出力の差として表せます。双対更新側も、推定器(GradEst)で期待報酬を見積もり、非負制約を満たすよう射影しながら更新する、という共通構造で捉えられます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related