SAPOのゲート関数設計:滑らかなゲートはRLHFの安定性をどう変えるか
この研究は、SAPO の要である滑らかなゲート関数を「何でも滑らかならよい」とは見ず、どの形のゲートが exploration と stability のバランスをどう変えるかを理論的に整理しています。 比較対象は sigmoid だけではなく、error function、arctangent、softsign まで広げられており、勾配の裾の重さが違うと、珍しいトークンへの感度やオフポリシー更新の抑え方が変わることを示します。 重要なのは、RLHF 系の方策更新を「clip の有無」ではなく「勾配がどの比率領域でどれだけ残るか」という形で設計し直した点です。経験的最適化の話に見えて、実はかなり設計原理寄りの論文です。
TL;DR(結論)
- この研究は、SAPO の要である滑らかなゲート関数を「何でも滑らかならよい」とは見ず、どの形のゲートが exploration と stability のバランスをどう変えるかを理論的に整理しています。
- 比較対象は sigmoid だけではなく、error function、arctangent、softsign まで広げられており、勾配の裾の重さが違うと、珍しいトークンへの感度やオフポリシー更新の抑え方が変わることを示します。
- 重要なのは、RLHF 系の方策更新を「clip の有無」ではなく「勾配がどの比率領域でどれだけ残るか」という形で設計し直した点です。経験的最適化の話に見えて、実はかなり設計原理寄りの論文です。
なぜこの問題か
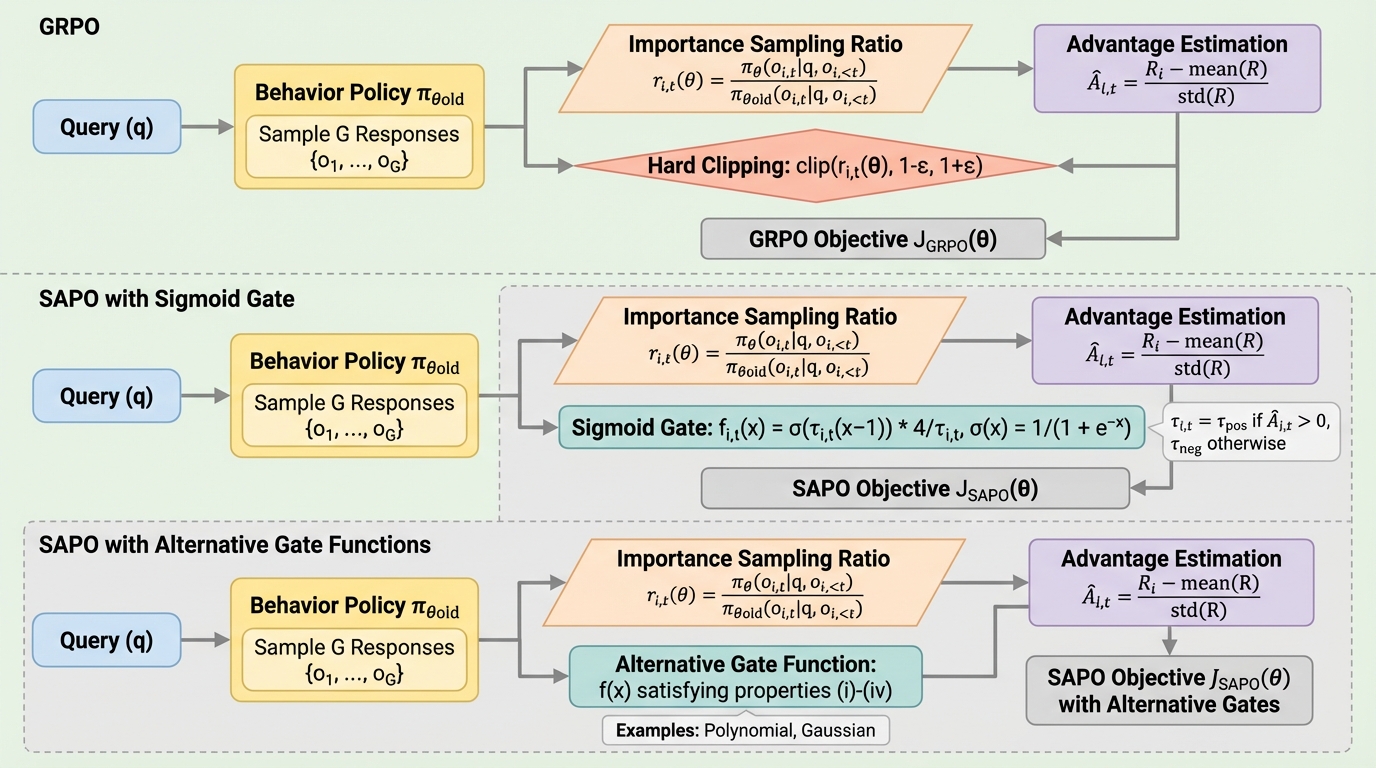
PPO や GRPO のような比率ベースの更新では、現在方策と過去方策のずれが大きいサンプルほど、更新が暴れやすくなります。そこでクリップを入れて暴れを抑えるわけですが、ハードクリップは更新を切るか残すかの閾値的な設計になりやすく、境界付近の振る舞いが荒くなります。特に言語モデルのようにトークン単位の更新が積み重なる場面では、この不連続さが安定性と学習効率の両方に効きます。
核心:何を提案したのか
提案の中心は、新しい巨大アルゴリズムではありません。SAPO の smooth gate を一般化し、望ましい gate が満たすべき admissibility criteria を明示したことにあります。具体的には、比率 1 の近傍で on-policy update と整合し、比率が離れるほど寄与を制御付きで減衰させ、極端な外れ値では勾配寄与が消えていく、という性質を軸にゲートを分類しています。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related