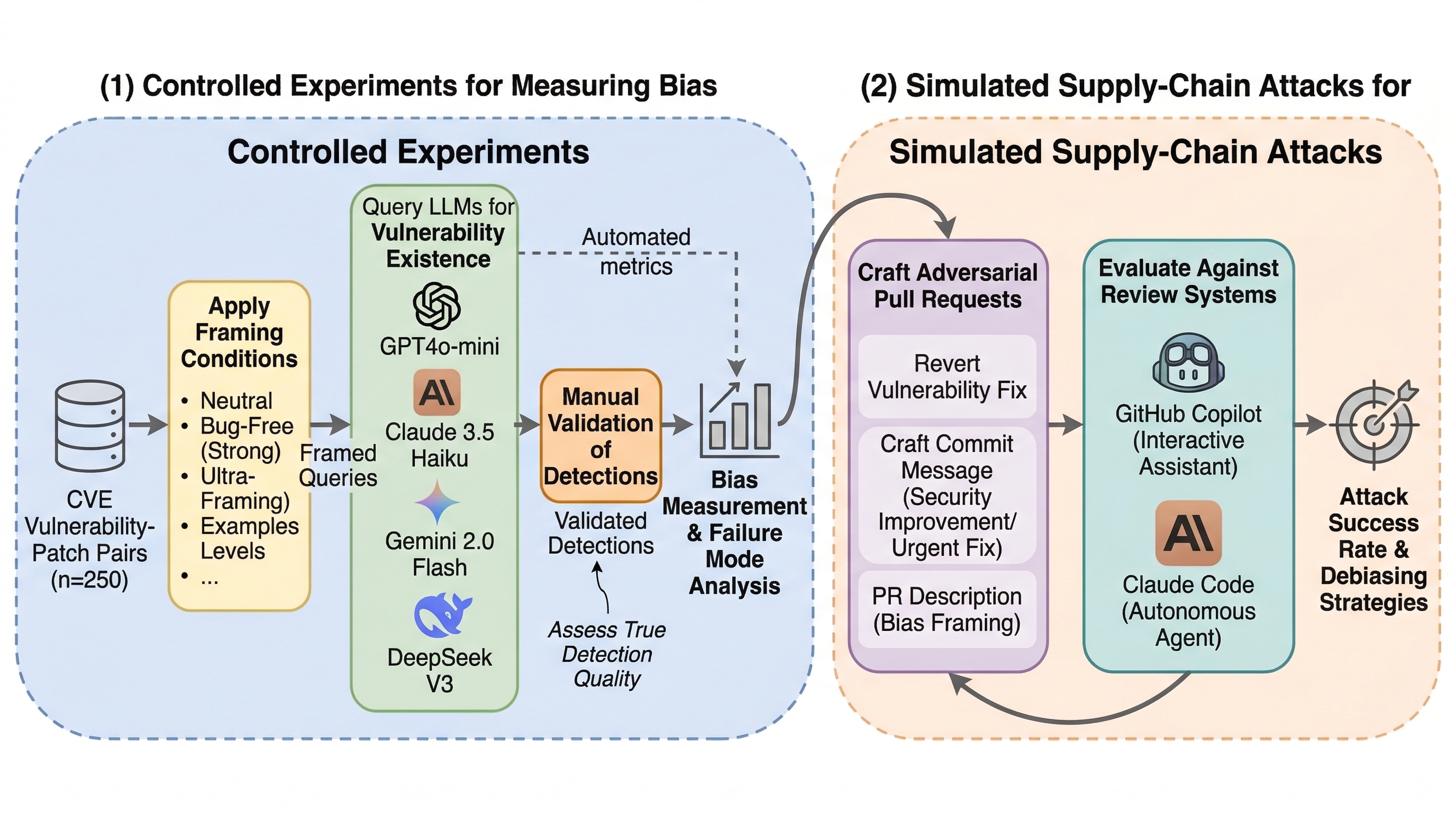
LLM セキュリティコードレビューは「安心そうな説明」に流されるのか:確認バイアスを測り、攻撃可能性まで検証した研究
2603.18740 は、LLM を使ったセキュリティコードレビューが、変更内容そのものよりも「これは安全改善です」「バグはありません」といった事前説明に引きずられる確認バイアスを持つかを測った論文です。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
2603.18740 は、LLM を使ったセキュリティコードレビューが、変更内容そのものよりも「これは安全改善です」「バグはありません」といった事前説明に引きずられる確認バイアスを持つかを測った論文です。
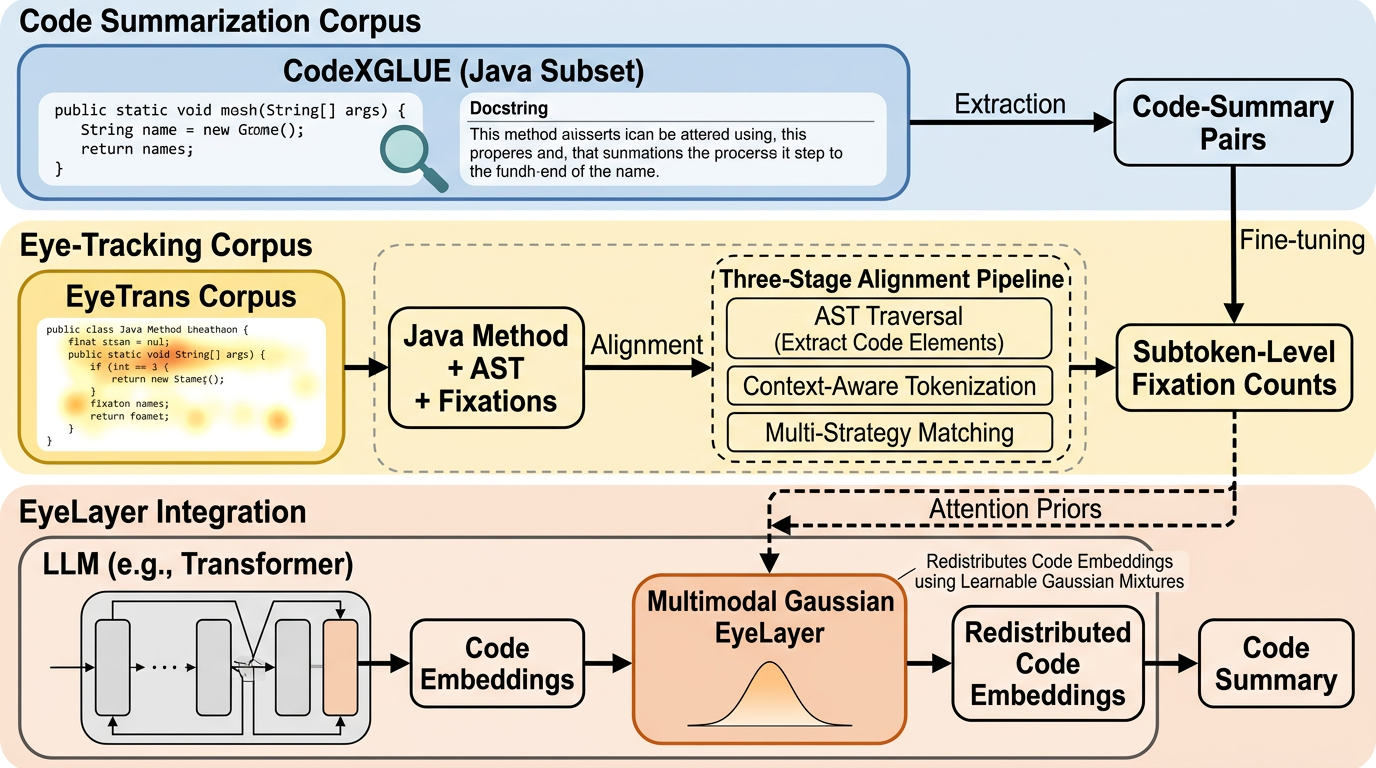
コード要約では高性能な大規模言語モデルでも、人が理解のために実際に注目する箇所とモデル側の焦点がずれる余地があり、そのずれを人の視線情報で埋められるかが未解決の問いとして扱われています。 / EyeLayerは、コード読解中の注視をマルチモーダルなガウス混合として注意の事前分布に落とし込み、学習した中心 μ と広がり σ² に基づいてトークン埋め込みを再配分することで、既存表現を乱さずにLLMへ統合できる軽量モジュールです。 / LLaMA-3.2、Qwen3、CodeBERTに対してCodeXGLUE(Java)で評価したところ、同一データで学習した強い教師あり微調整ベースラインを標準指標で一貫して上回り、BLEU-4で最大13.17%の改善が示され、視線が補完的な注意信号としてモデル間で移植可能に働く含意が示されています。
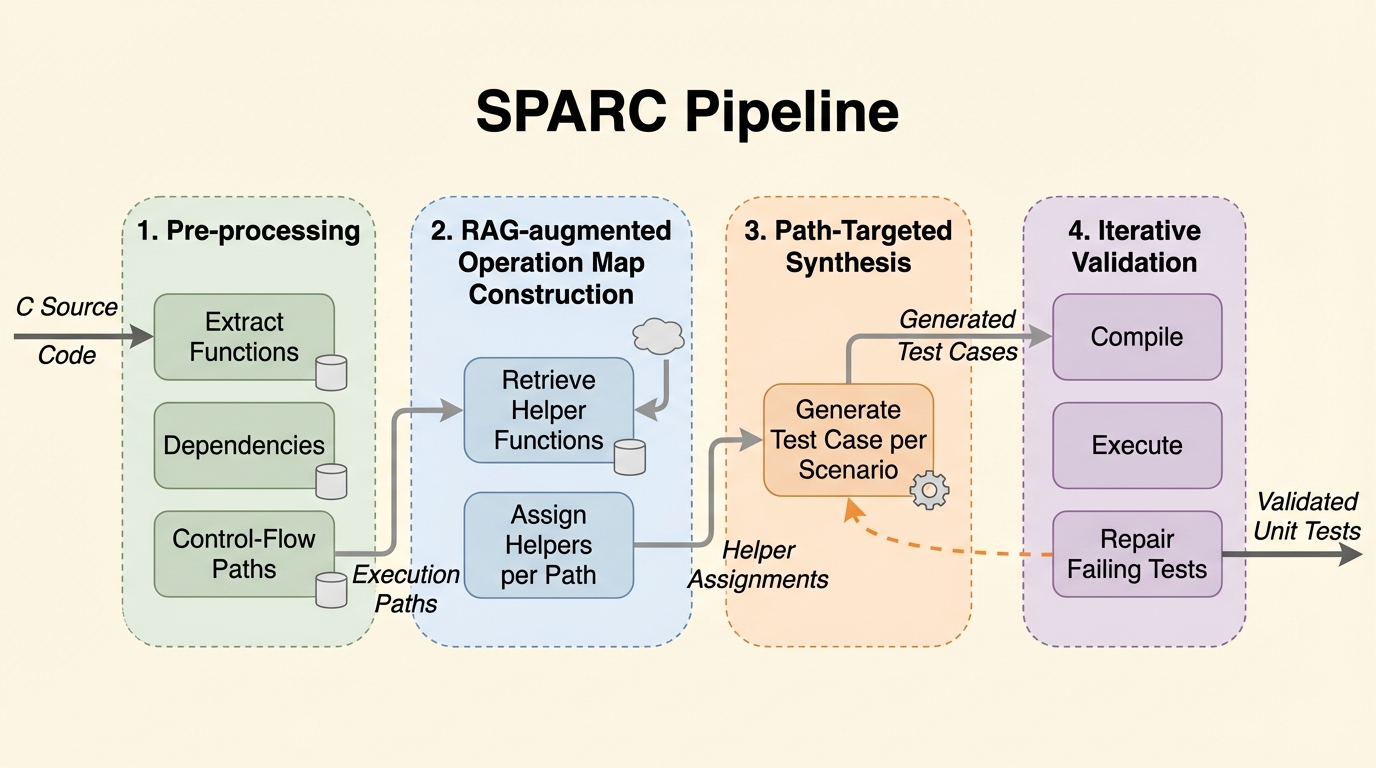
Cではポインタ演算や手動メモリ管理の制約が強く、LLMに意図だけを渡してテストを書かせると、正常系に偏ったり依存関係を捏造したりして、コンパイル不能や意味の薄いアサーションになりやすいです。 / SPARCは制御フローグラフから実行パスごとのシナリオを抽出し、検証済みヘルパーに基づく操作マップで呼び出し先を制限したうえで、パス単位のテスト生成とコンパイル・実行フィードバックによる反復修復を行います。 / 59件の対象で単純なプロンプト生成より行・分岐カバレッジとミューテーションスコアが向上し、複雑な対象ではKLEEに匹敵または上回り、修復後にテストの大半が残って可読性と保守性の評価も高まりました。
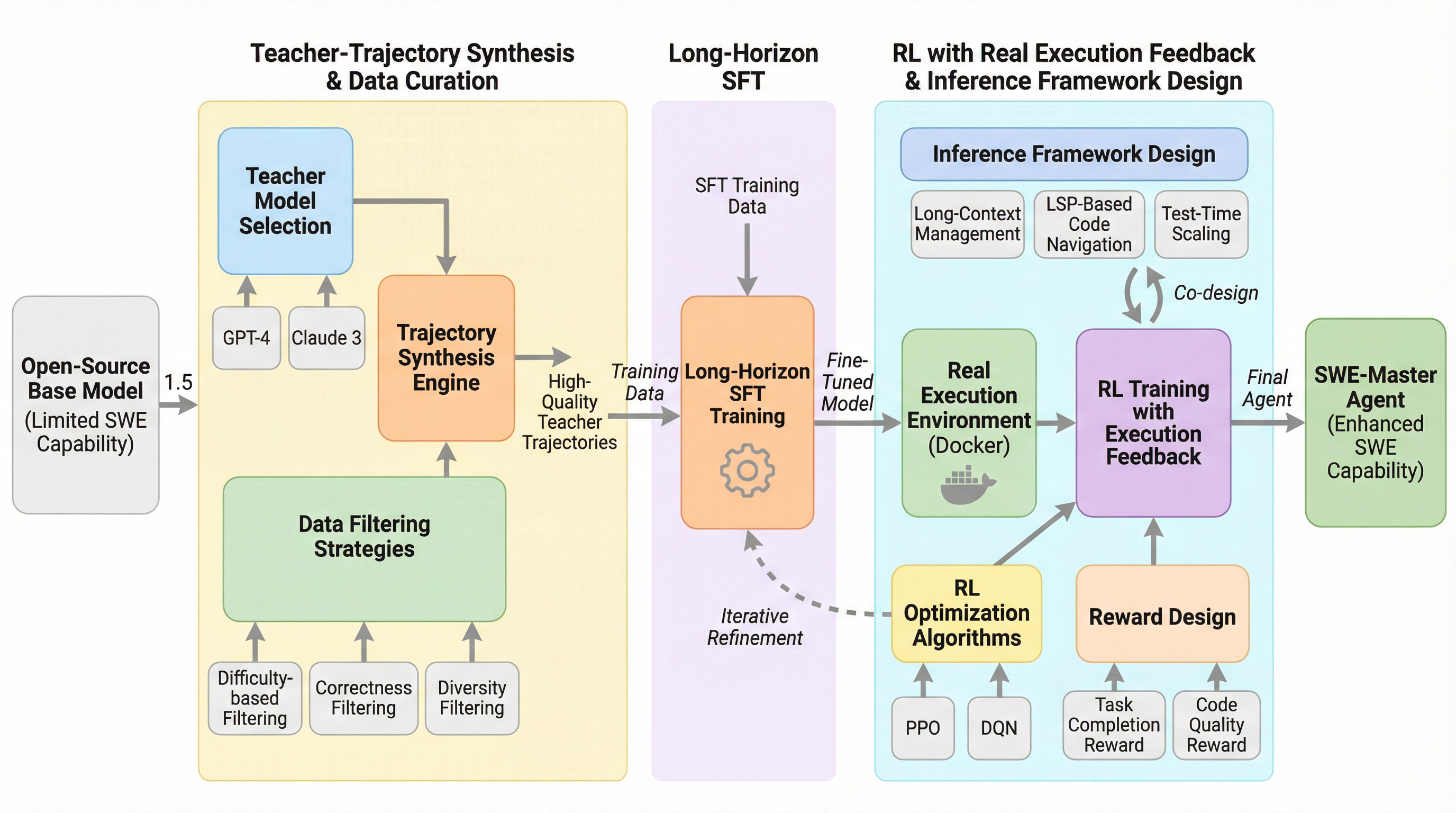
SWE-Masterは、ソフトウェアエンジニアリング(SWE)タスクを自律的に解決するエージェントを構築するための、完全に再現可能でオープンソース化されたポストトレーニングフレームワークである。
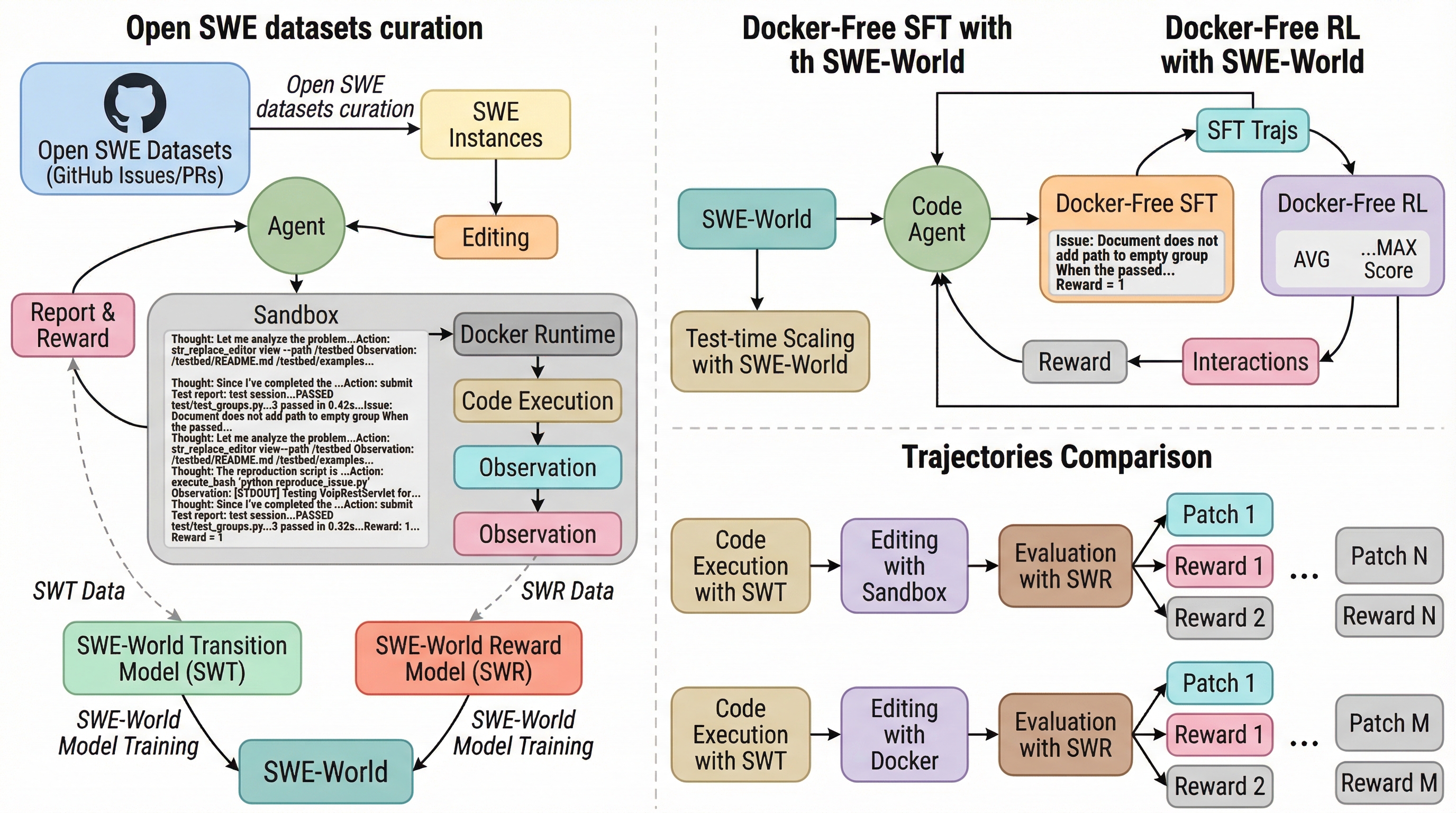
従来のソフトウェアエンジニアリングエージェントは、コード実行やテストのためにDockerなどの重いコンテナ環境に依存しており、環境構築の失敗や膨大な計算リソースの消費が、大規模な学習や評価を妨げる深刻なボトルネックとなっていました。
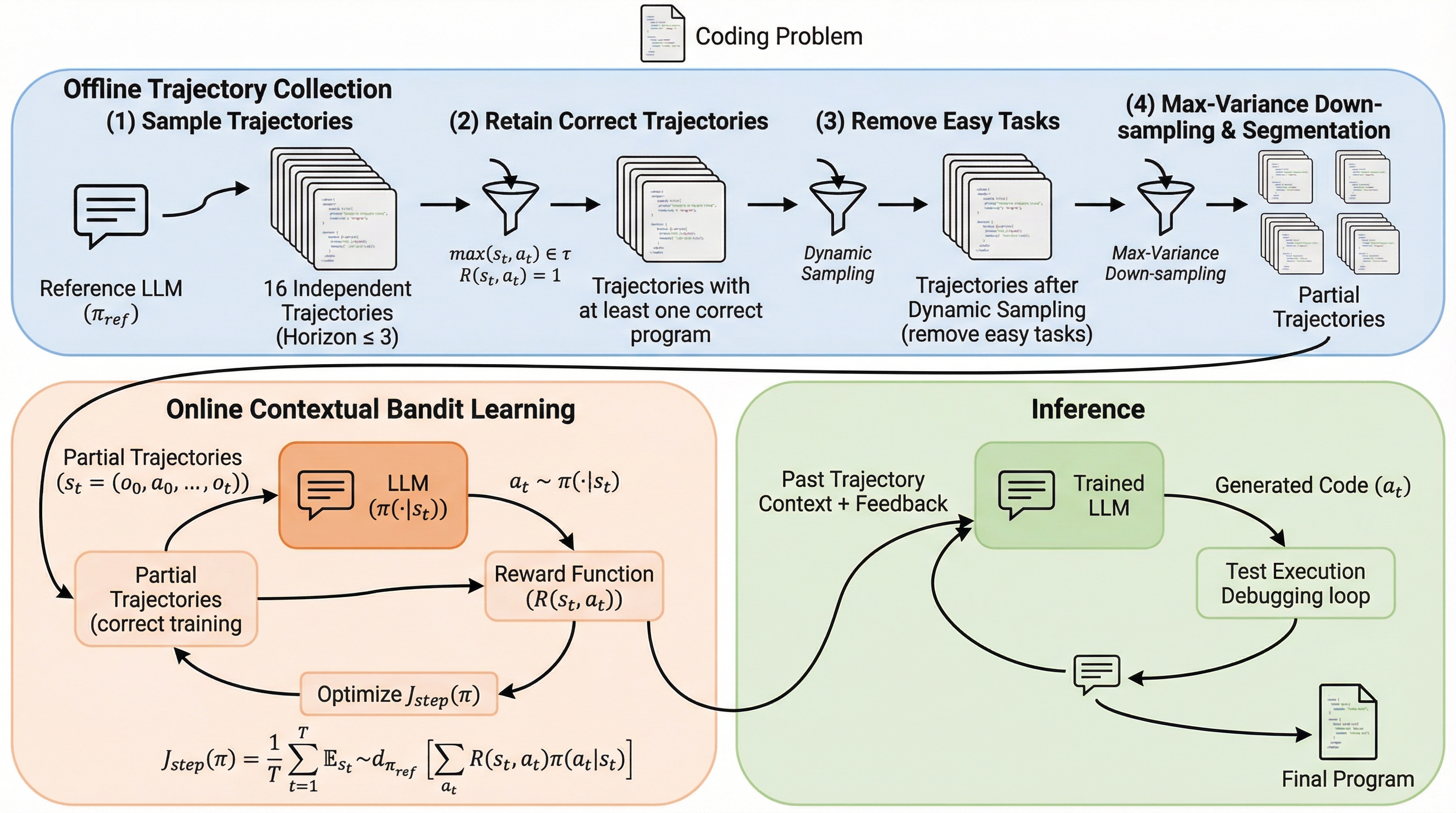
マルチターンでコードを書き直すLLMは、どうすれば「強く」かつ「安く」育てられる? オンラインRLが強いのは分かる。でも高コストで不安定——そこで発想を変える。 この記事では、COBALTが“マルチターン”を“一手ずつ”に分解して橋をかけた狙いと手触りを追う。
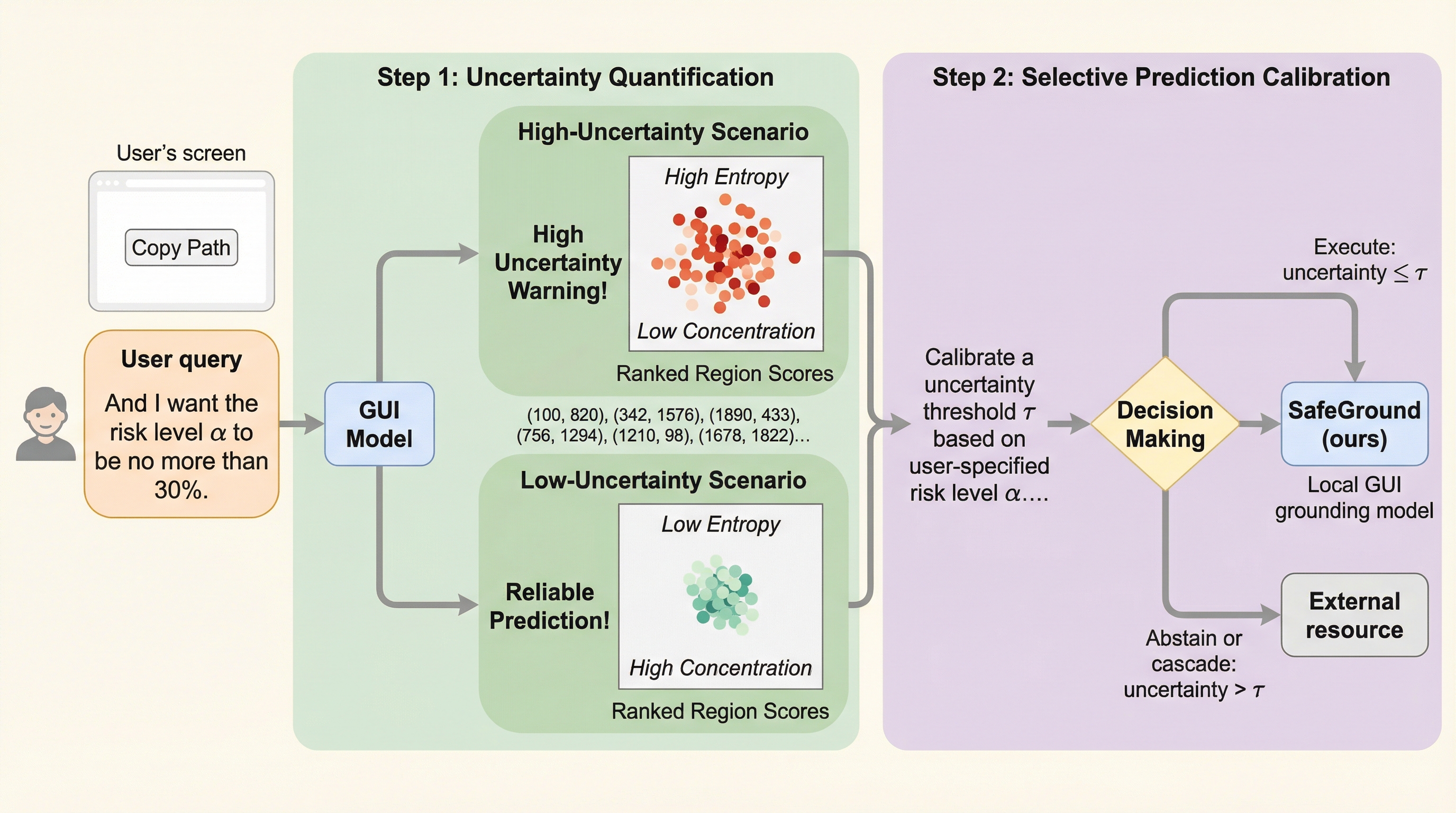
クリック位置を外しただけで、支払い承認のような取り返しのつかない操作が走ったらどうでしょうか。 しかもその瞬間、システムは迷いなく「成功した体」で先へ進んでしまうかもしれません。 GUIグラウンディングの怖さは、精度不足そのものより「間違えるときに黙って実行してしまう」ことにあります。
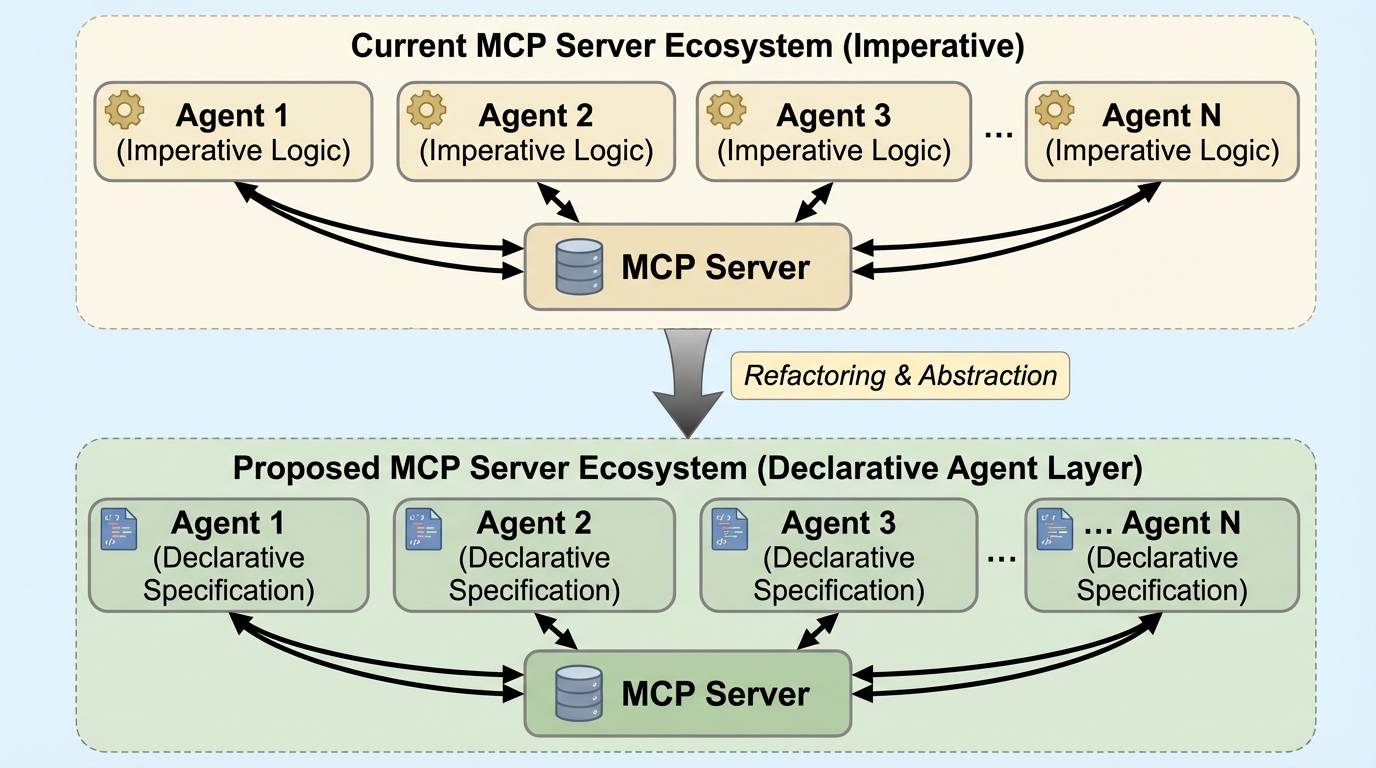
大規模言語モデル(LLM)ベースのエージェントは、行動の根拠となる明示的な構造を欠いているため、実行不可能な計画の作成やハルシネーションといった深刻な信頼性の問題に直面しており、既存のマルチエージェントシステムでは41%から86%という高い失敗率が報告されている。
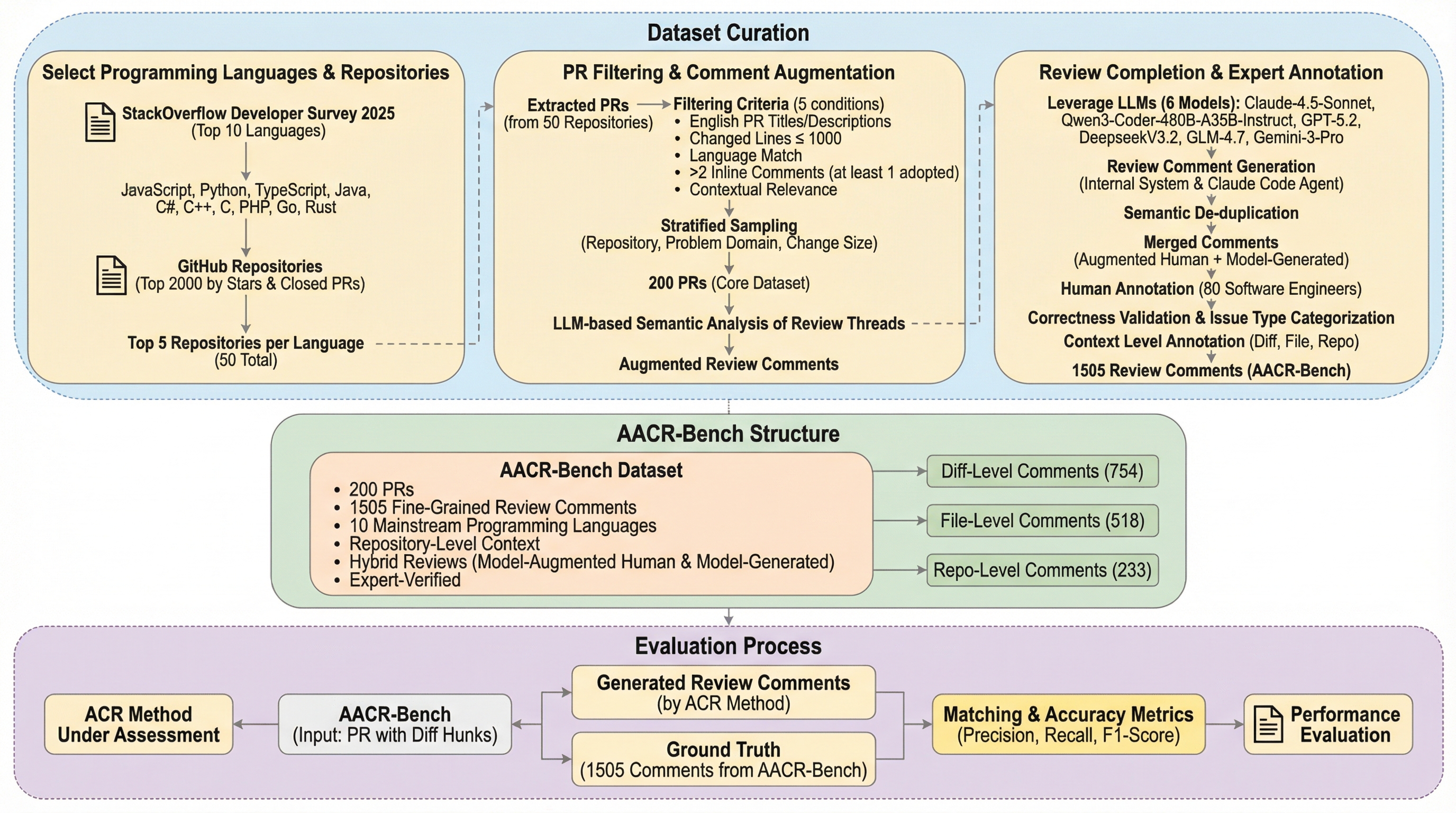
従来の自動コードレビュー(ACR)の評価は、GitHubの生のプルリクエストデータに依存していたため、正解データの網羅性が低く、特定の言語に偏っているという課題がありました。本研究が提案する「AACR-Bench」は、10種類の主要言語と50のリポジトリを対象とし、80名の熟練エンジニアと最新AIモデルを組み合わせた検証パイプラインにより、問題の網羅率を従来比で285%向上させた画期的なベンチマークです。検証の結果、リポジトリレベルの文脈提供やエージェント構成の採用がモデルの性能に与える影響は、使用する言語やモデルの特性によって大きく異なることが明らかになり、今後の自動レビュー技術開発における重要な指針を提示しました。
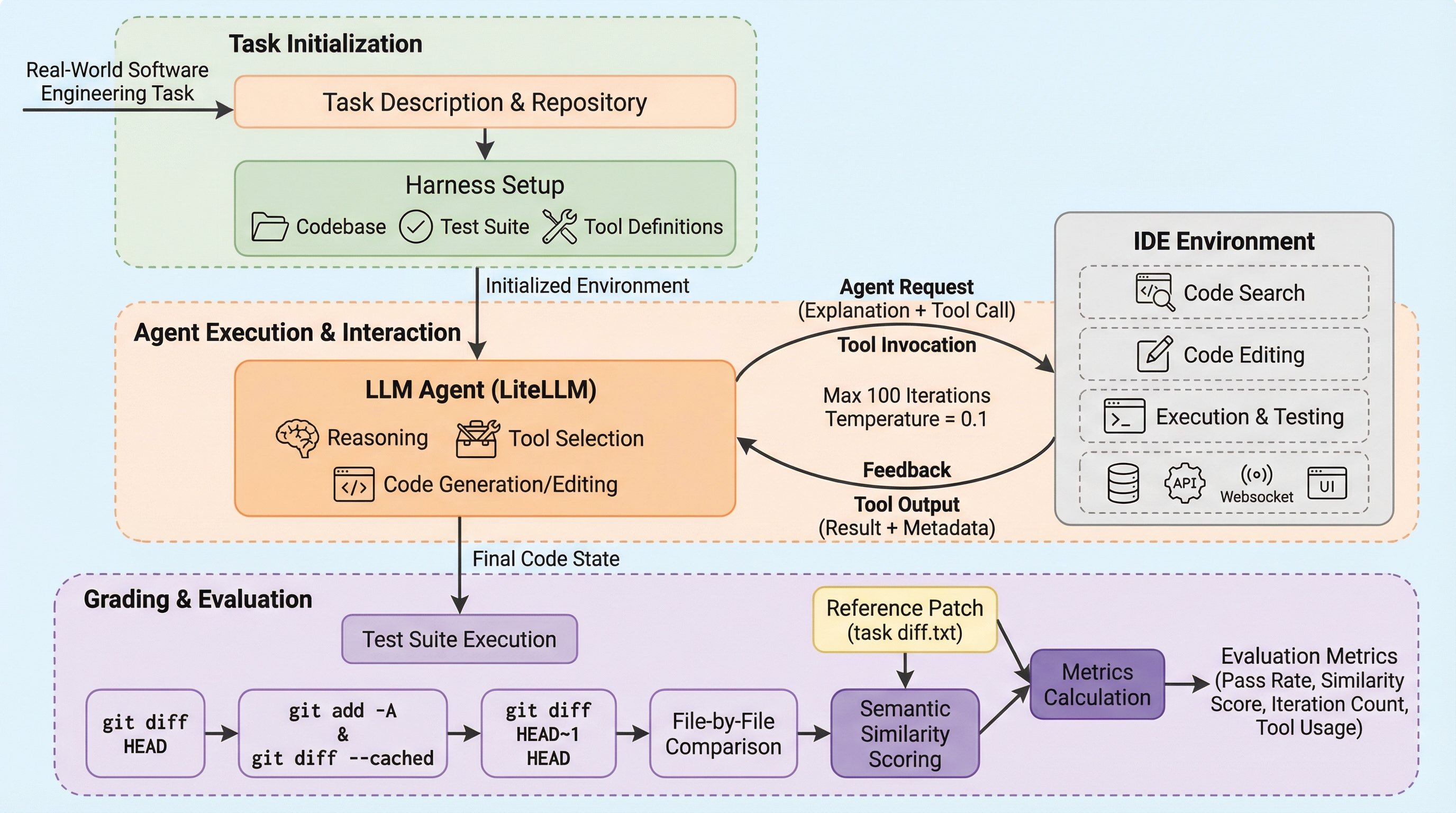
IDE-Benchは、CursorやWindsurfのようなAIネイティブIDEの動作を模した、LLMを「IDEエージェント」として評価するための新しいベンチマークフレームワークである。 学習データへの汚染を防ぐために作成された未公開の8つのリポジトリ(C/C++、Java、MERNスタック等)と80のタスクを用い、コード検索や編集、テスト実行といった17種類のツールを駆使した多段階の課題解決能力を厳密に測定する。 評価の結果、GPT 5.2が95%の成功率(pass@5)で首位となったが、多くのモデルで「アルゴリズムは正しいが形式や端的なケースで失敗する」という課題や、言語・フレームワークごとの得意不得意が顕著に現れた。