SWE-Spot: リポジトリ中心学習による小規模なリポジトリ専門家モデルの構築
従来のタスク中心学習では、小規模言語モデルが複雑なコードベースの推論時に十分な汎化性能を発揮できず、表面的なパターンの学習に留まるという課題がありました。 本研究は、特定のコードベースに対する垂直的な深さを優先する「リポジトリ中心学習(RCL)」を提案し、静的なコードを対話的な学習信号に変換する4つの経験ユニットを設計しました。 この手法で構築された4BパラメータのSWE-SPOTは、8倍大きなオープンモデルや商用モデルに匹敵する性能を、高いサンプル効率と低い推論コストで実現することに成功しました。
TL;DR(結論)
従来のタスク中心学習では、小規模言語モデルが複雑なコードベースの推論時に十分な汎化性能を発揮できず、表面的なパターンの学習に留まるという課題がありました。 本研究は、特定のコードベースに対する垂直的な深さを優先する「リポジトリ中心学習(RCL)」を提案し、静的なコードを対話的な学習信号に変換する4つの経験ユニットを設計しました。 この手法で構築された4BパラメータのSWE-SPOTは、8倍大きなオープンモデルや商用モデルに匹敵する性能を、高いサンプル効率と低い推論コストで実現することに成功しました。
なぜこの問題か
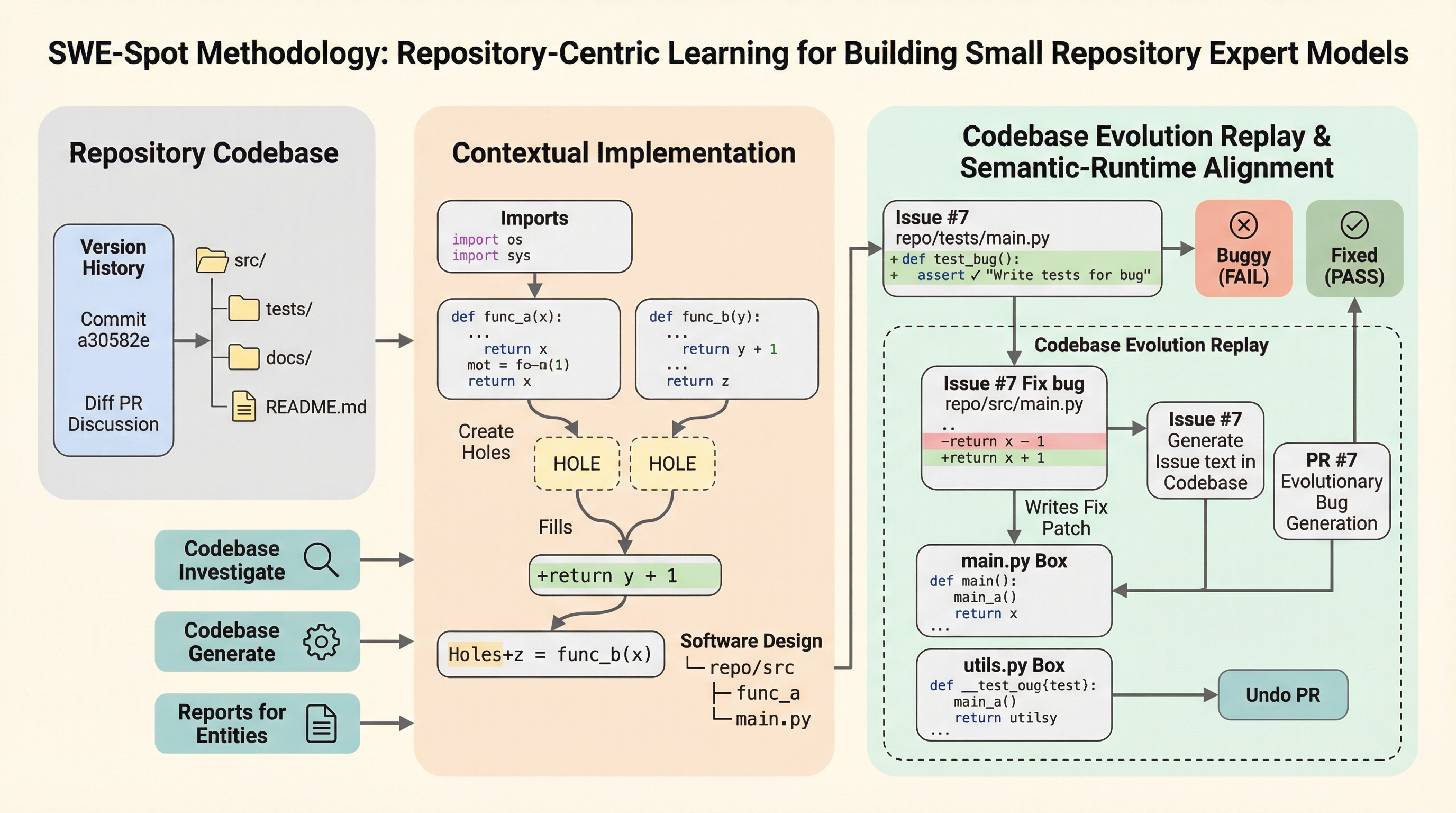
現在のソフトウェアエンジニアリングにおけるエージェントワークフローは、主に数千億のパラメータを持つクローズドな商用モデルに依存しています。しかし、これらのモデルは運用コストが高く、プライバシーが重視される環境やリソースが制限された環境でのローカル展開には適していません。そのため、10Bパラメータ未満でローカル展開が可能な、能力の高い小規模言語モデル(SLM)への需要が急速に高まっています。 既存の小規模モデルの能力不足を補うためのアプローチとして、これまでは「タスク中心学習(TCL)」が主流でした。これは、多数の異なるリポジトリにわたってGitHubのIssue解決などのタスクを学習させる手法です。この手法の背後には、膨大な数のタスク軌跡に触れることで、汎用的なバグ修正スキルが獲得できるという仮定があります。しかし、このパラダイムを小規模モデルに適用すると、根本的な限界に直面することが明らかになりました。 大規模なフロンティアモデルは、未知の環境においても推論時の広範な探索や試行錯誤、自己反省を通じて、欠落している知識を補うことができます。一方で、小規模モデルにはそのような推論時の能力が欠けています。…
核心:何を提案したのか
本研究では、小規模言語モデルが推論時にリポジトリ固有の知識を確実に取り込むことができないのであれば、その知識を訓練中に内部化し、展開時には事前知識として保持しておくべきであるという洞察に基づき、「リポジトリ中心学習(RCL)」という新しいパラダイムを提案しました。これは、タスクの広さを追求する従来の学習とは対照的に、特定のリポジトリに対する垂直的な理解の深さを優先するものです。 このアプローチは、人間の開発者が専門知識を構築するプロセスに似ています。人間は、数千の無関係なプロジェクトで孤立したバグを修正することによって習熟するのではなく、特定のターゲットリポジトリとの持続的な対話を通じて専門性を高めます。コードの読み込み、実行、テスト、デバッグ、そして反復的な修正といった一連の経験を通じて、開発者はリポジトリの構造や動作、依存関係、実行ダイナミクス、不変条件などの「運用の意味論」を暗黙的に表現できるようになります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related