VLMはロボットの動きの好みをどこまで読めるか:軌道選択で測る空間推論
視覚言語モデルが、ロボットの経路そのものに対する自然言語の好みをどこまで理解できるかを、軌道選択課題として系統的に測った研究です。single-query 方式と Qwen2.5-VL が強く、近接性にはかなり反応できる一方で、path style や幾何的比較にはまだ弱さが残ります。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
視覚言語モデルが、ロボットの経路そのものに対する自然言語の好みをどこまで理解できるかを、軌道選択課題として系統的に測った研究です。single-query 方式と Qwen2.5-VL が強く、近接性にはかなり反応できる一方で、path style や幾何的比較にはまだ弱さが残ります。
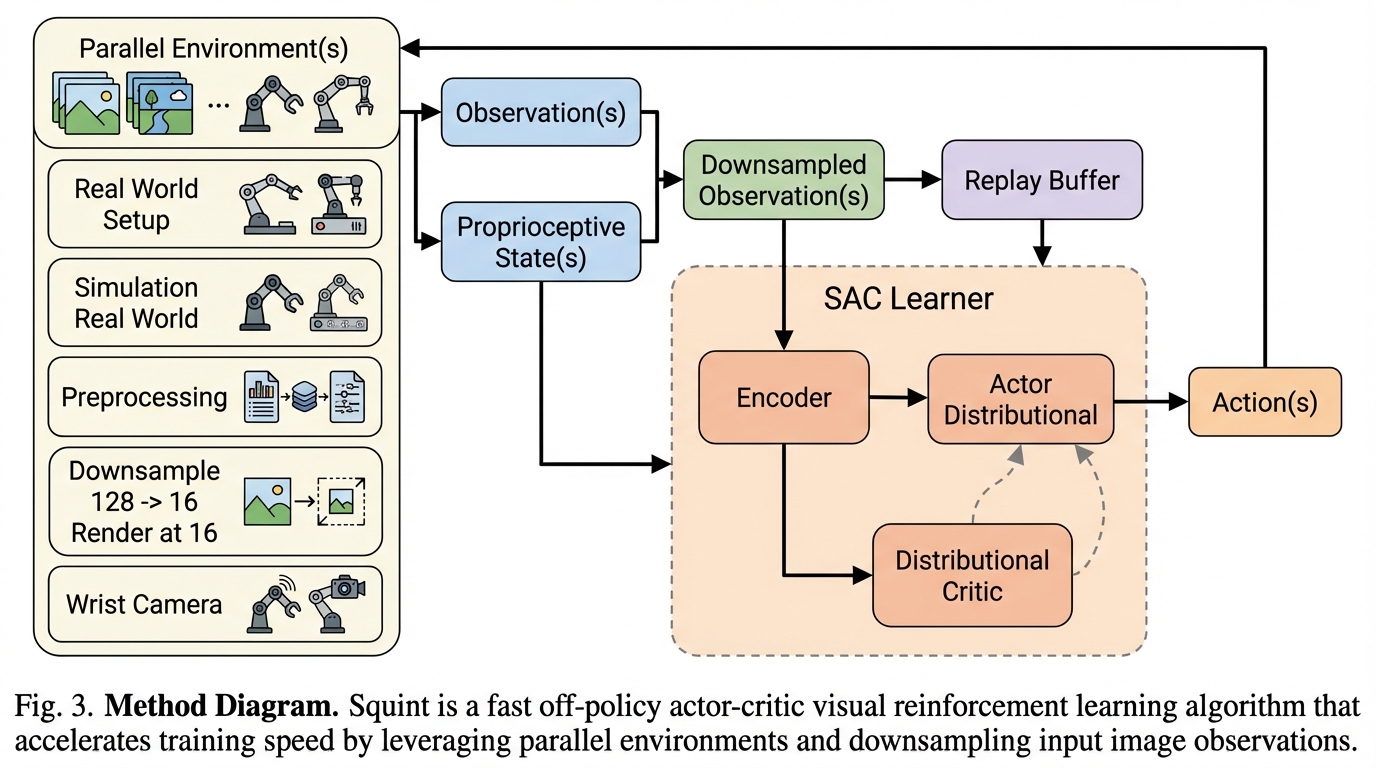
Squintは、カメラ画像と自己受容情報から操作方策を学習する視覚SACで、並列シミュレーションと経験再利用を両立させつつ、学習の実時間を従来の視覚オフポリシー法・オンポリシー法より短くすることを狙った手法です。
Vision Transformerは画像内のパッチ間の関係を自己注意で同時に扱える一方、計算量とメモリ要求が大きく、GPUを増やしても学習が素直に速くならない状況が起こり得ます。 / 本研究はDeepSpeedをVision Transformer(ViT b16)の学習に組み込み、ノード内・ノード間のデータ並列を複数GPU構成で動かし、学習時間・通信オーバーヘッド・強いスケーリングと弱いスケーリングの傾向を、主にCIFAR-10とCIFAR-100で追跡しています。 / 実測では、GPUの同質性が崩れると同期待ちが増えてスケーリングが乱れやすく、またバッチサイズを大きくすると同期コストが下がる傾向が見られ、64または128が通信とメモリの折り合いとして有望だと整理されています。
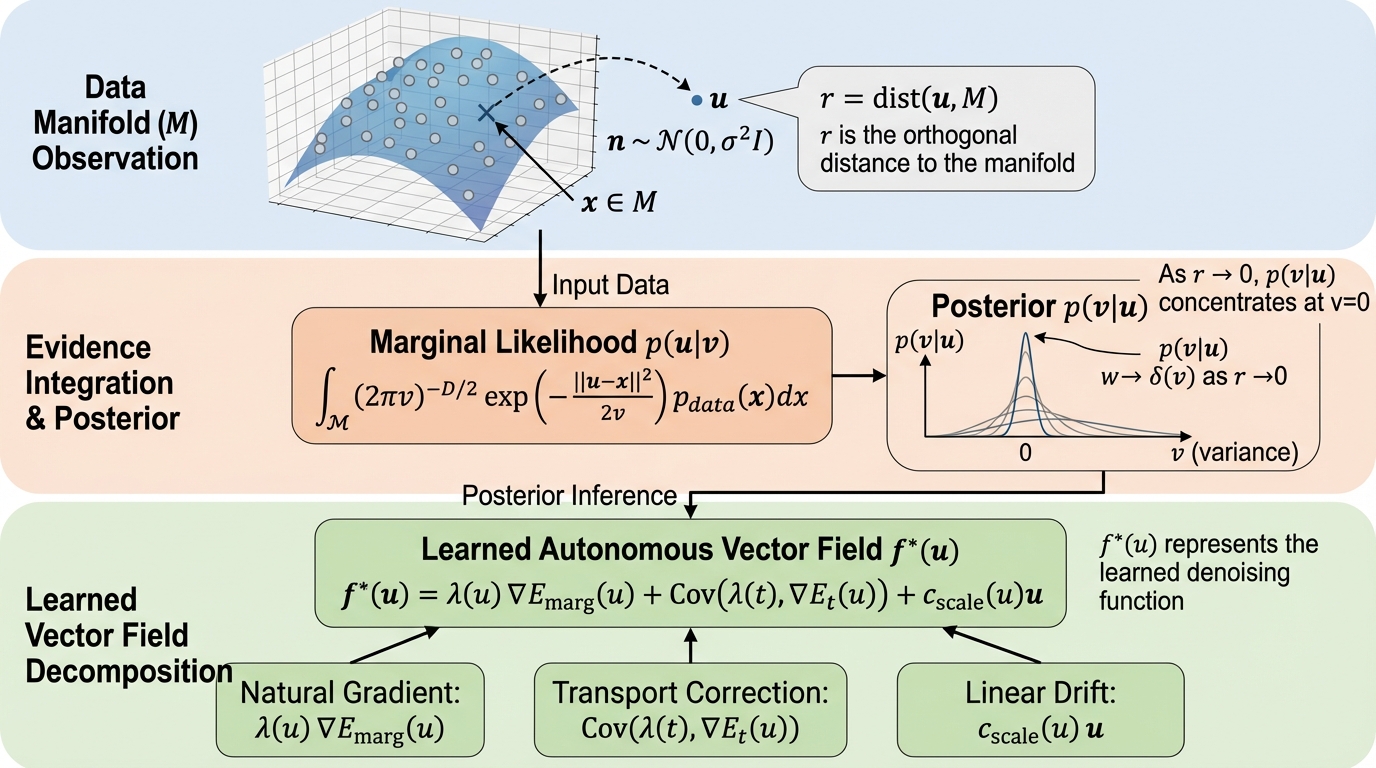
ノイズレベルを入力しない自律(ノイズ非依存)生成モデルでも、学習された単一の時間不変ベクトル場は「闇雲なデノイズ」ではなく、未知ノイズを周辺化した周辺密度 \(p(\mathbf{u})=\int p(\mathbf{u}\mid t)p(t)\,dt\) に対応する周辺エネルギー \(E_{\text{marg}}(\mathbf{u})=-\log p(\mathbf{u})\) の幾何と結び付いています。 / ただし周辺エネルギーの生の勾配はデータ多様体の法線方向に \(1/t^p\) 型の特異性を持ち、通常の勾配降下では不安定になり得ますが、論文は相対エネルギー分解により、学習場が局所的な共形計量(実効ゲイン)を暗黙に含むリーマン勾配流として振る舞い、特異性を前処理して打ち消す構図を示します。 / さらに自律サンプリングの構造安定性条件を与え、ノイズ予測パラメータ化には推定誤差を増幅し得る「Jensen Gap」がある一方、速度ベースのパラメータ化は有界ゲイン条件により後部分布の不確実性を滑らかな幾何学的ドリフトへ吸収できる、という含意を導きます。
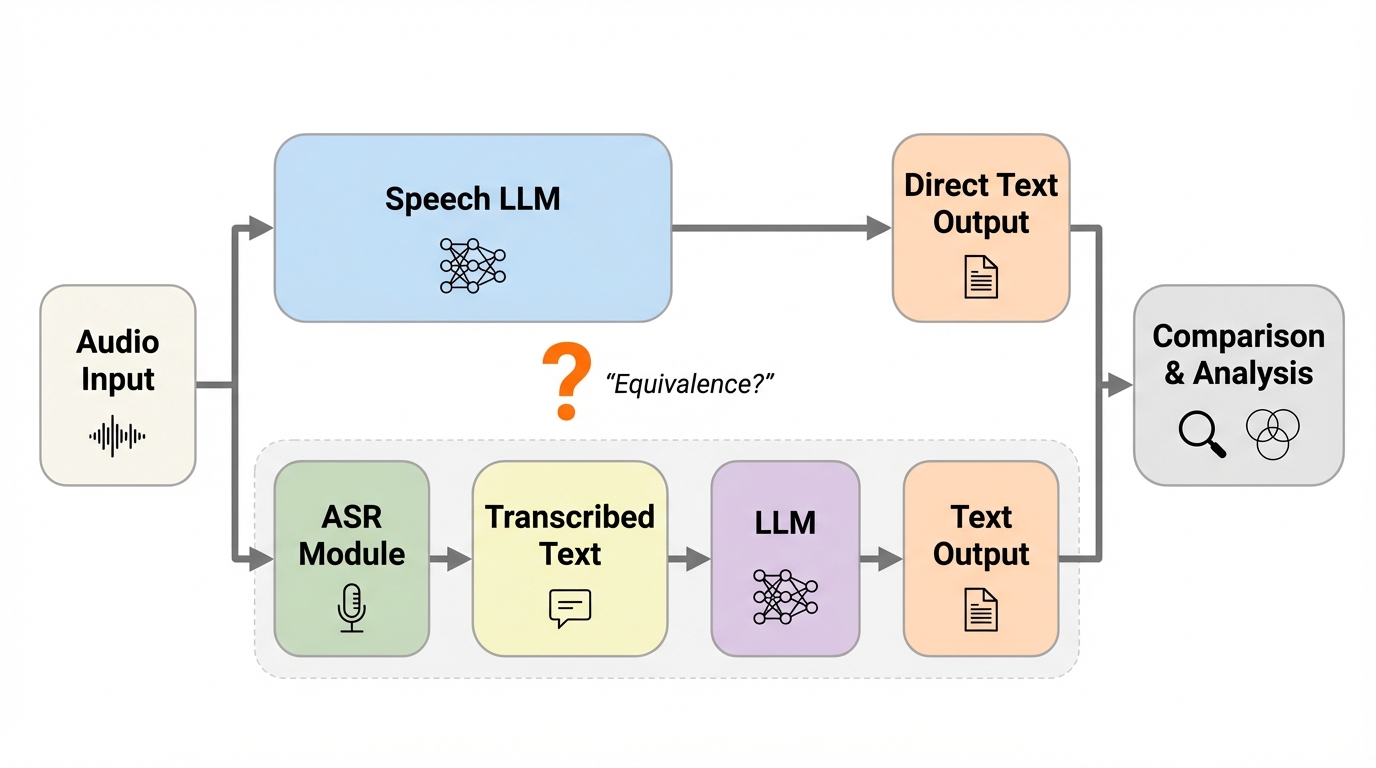
書き起こしだけで解ける課題では、多くの音声大規模言語モデルが内部で暗黙の書き起こし表現を作り、その後に言語モデルとしての推論を進めるため、同じ言語モデルを組み合わせた自動音声認識→言語モデルのカスケードと、出力だけでなく失敗の仕方まで似やすいです。
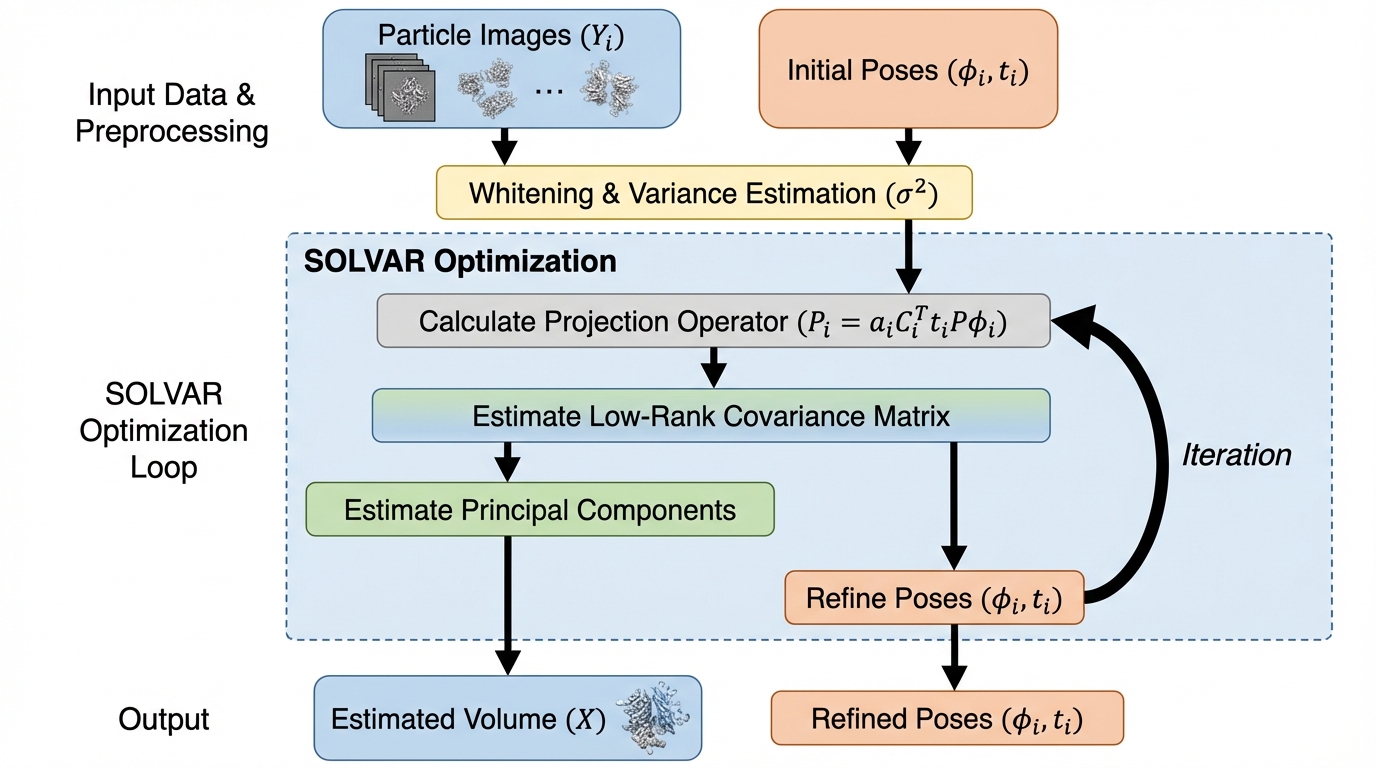
クライオ電子顕微鏡(cryo-EM)で分子が連続的に形を変えるとき、構造変動を共分散で捉える考え方は筋がよい一方、共分散行列が巨大すぎて主成分を実用的に推定しにくいという計算上の壁があります。 / SOLVARは共分散が低ランクという仮定を置き、共分散そのものではなく主成分(固有ベクトルに対応する基底体積)を目的変数にした最適化へ組み替え、確率的勾配法で素早く解く枠組みにしています。 / さらに粒子画像の姿勢(回転・平行移動)を推定途中で更新できるようにし、合成データと実データの実験で主要な変動成分を捉えつつ計算効率も維持し、最近のベンチマークでも複数データセットで高い成績を示したと述べています。
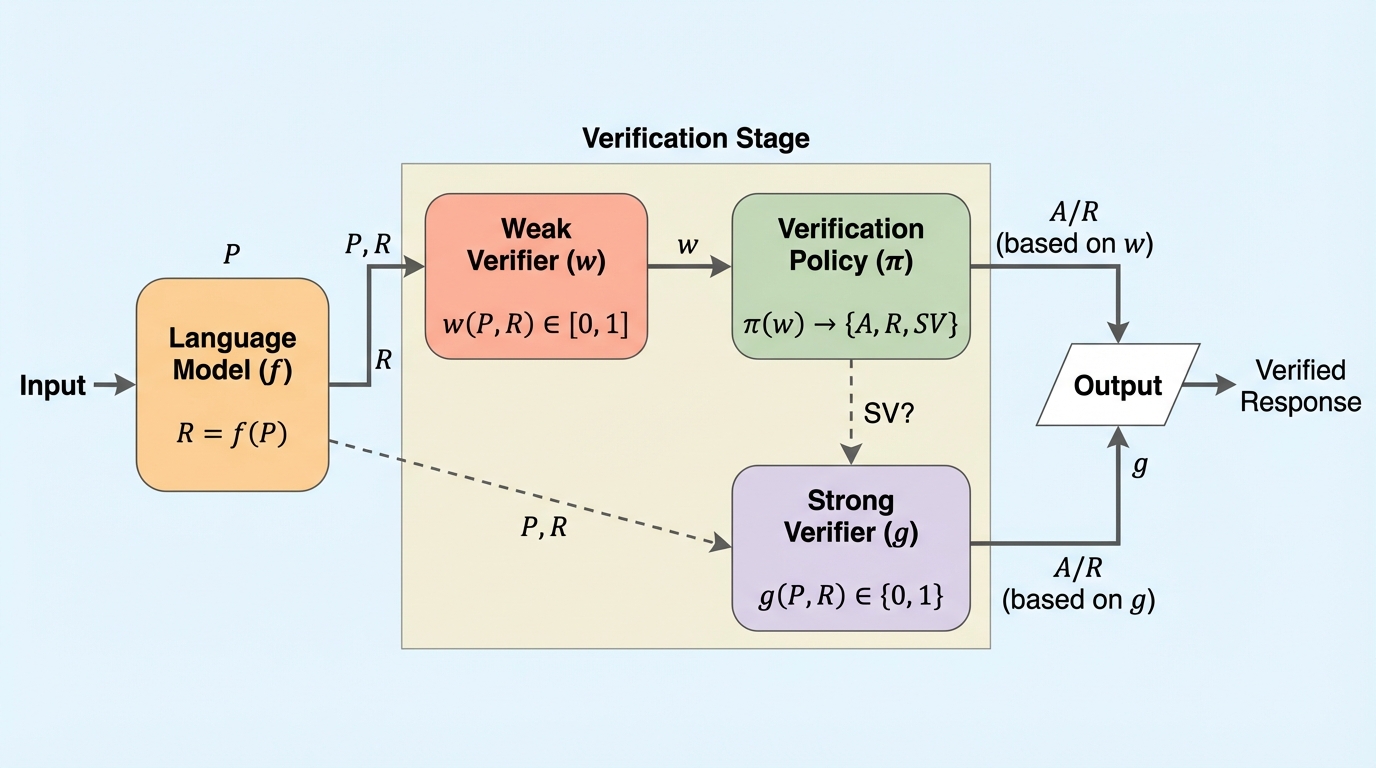
推論を含む大規模言語モデルの運用では、速くて安いが不完全な弱い検証と、信頼を確立しやすい一方で資源を要する強い検証の使い分けがボトルネックになりやすく、本論文はその緊張関係を「いつ強い検証に委ねるか」という意思決定として整理しています。
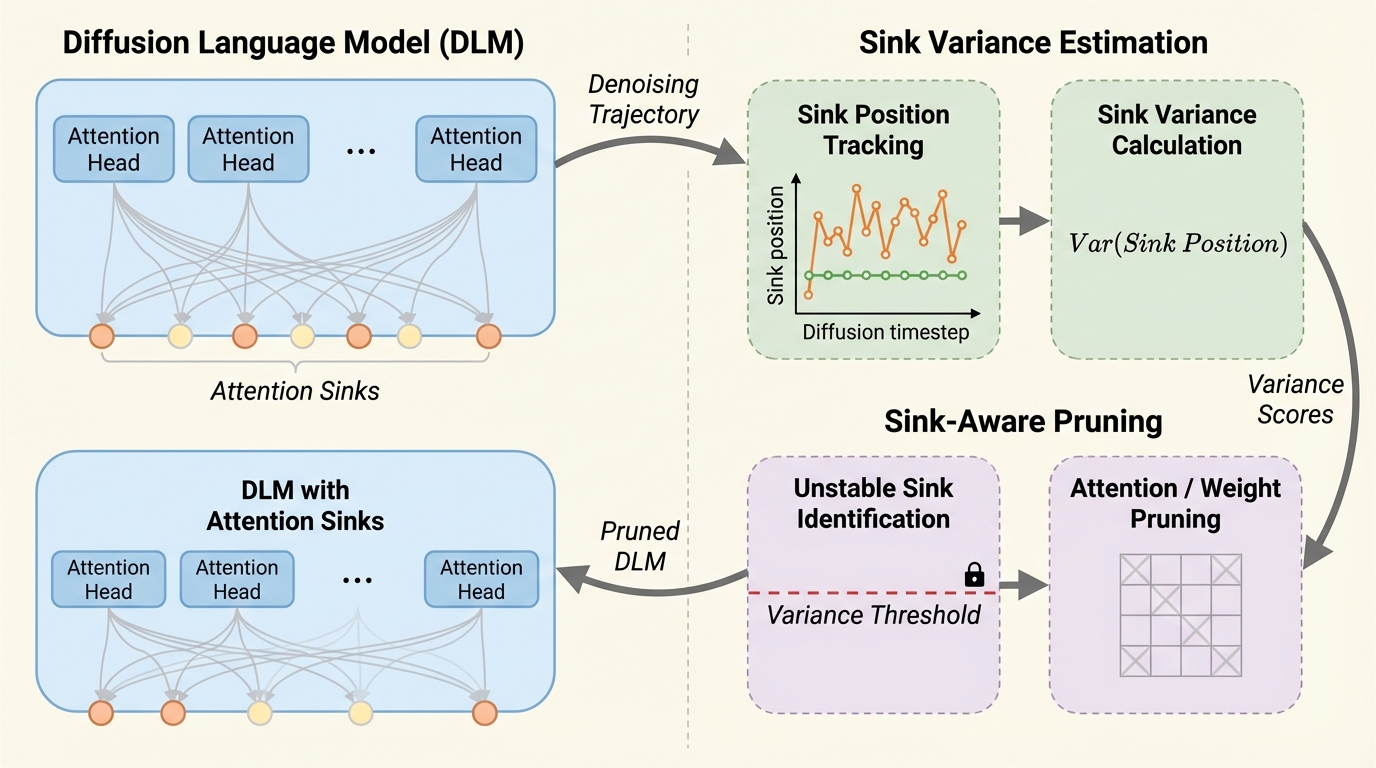
拡散言語モデル(DLMs)では、生成の反復的なデノイジング過程を通じて注意の集中先(attention sink)の位置が大きく動きやすく、自己回帰(AR)モデルで広まった「sinkは安定した錨なので残すべき」という前提がそのまま当てはまりにくいと示されています。
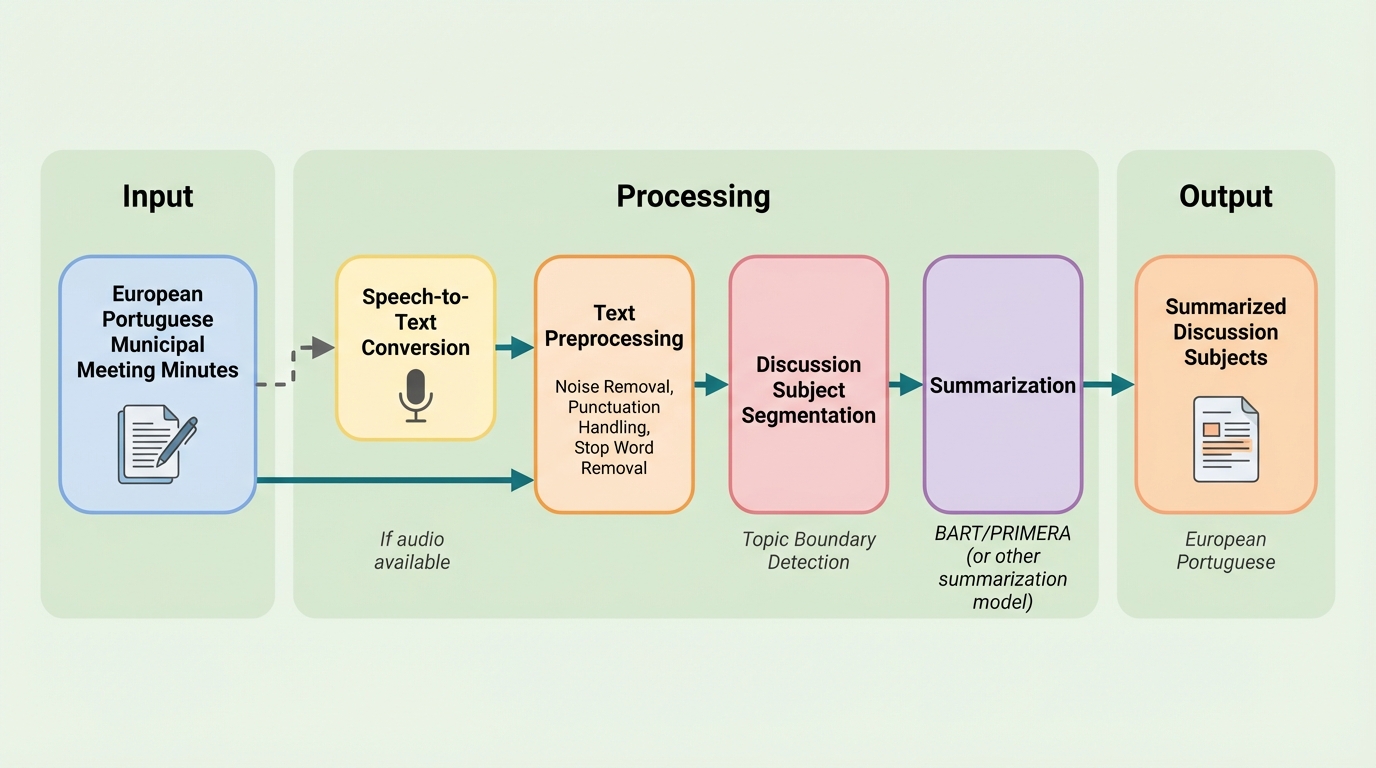
自治体の会議議事録は意思決定の記録として重要ですが、長く形式的で複数の議題が混在しやすいため、市民が必要箇所を見つけて理解する負担が大きく、議題単位での自動要約を可能にする基盤整備が課題になります。
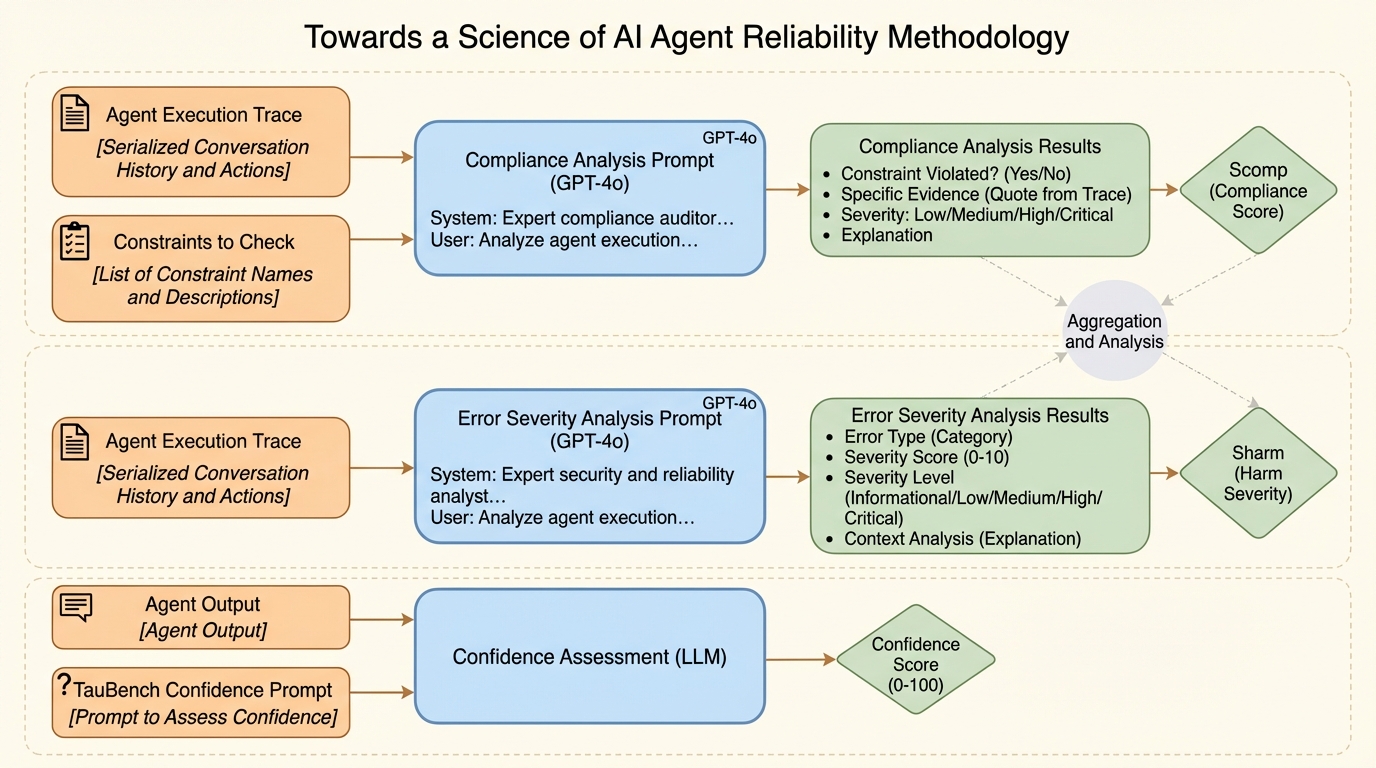
ベンチマークの平均的な成功率が上がっても、実運用で求められる「同じ条件なら同じように動くか」「少しの外乱で壊れないか」「失敗が予測できるか」「失敗しても被害が抑えられるか」は見えにくく、単一の成功率だけでは重要な弱点が隠れます。