カスケード等価仮説:音声大規模言語モデルはいつ自動音声認識→言語モデルのパイプラインのように振る舞うのか。
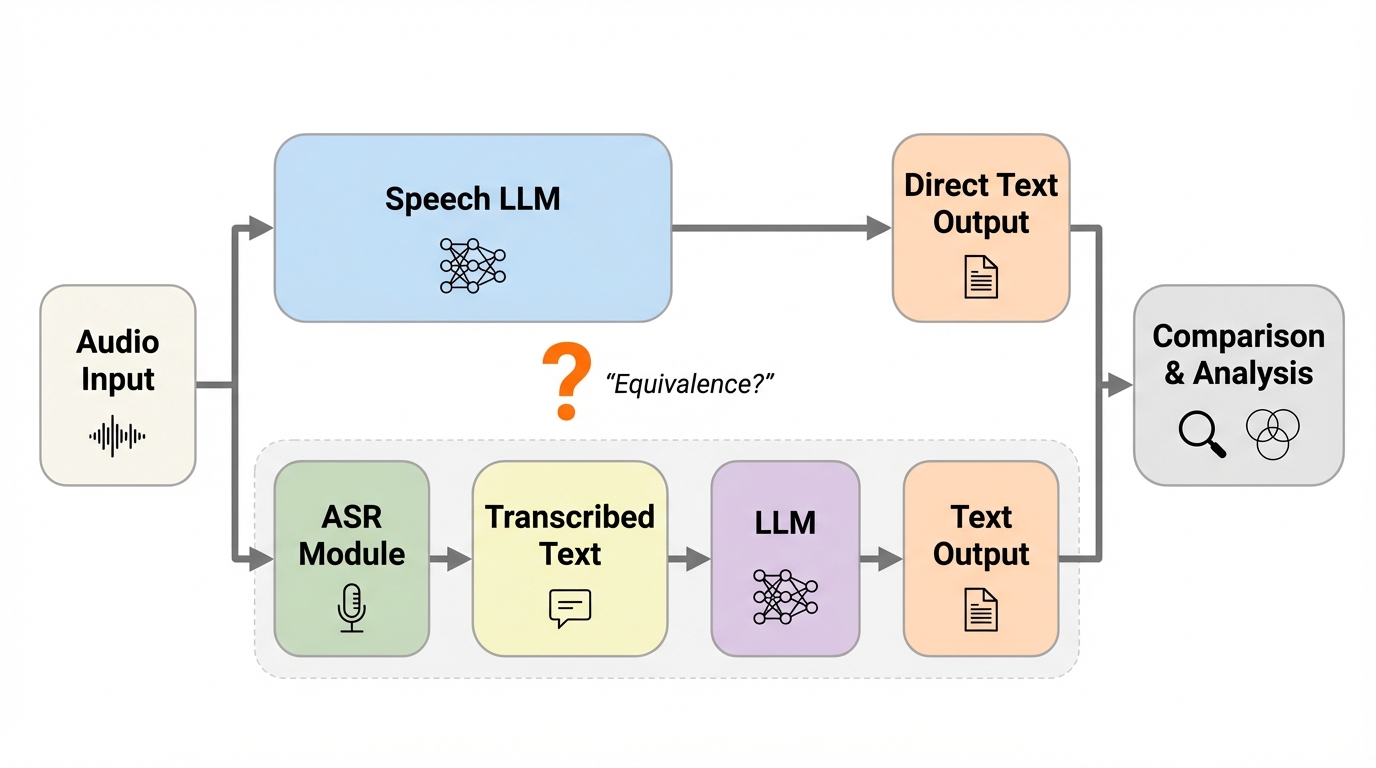
書き起こしだけで解ける課題では、多くの音声大規模言語モデルが内部で暗黙の書き起こし表現を作り、その後に言語モデルとしての推論を進めるため、同じ言語モデルを組み合わせた自動音声認識→言語モデルのカスケードと、出力だけでなく失敗の仕方まで似やすいです。
TL;DR(結論)
- 書き起こしだけで解ける課題では、多くの音声大規模言語モデルが内部で暗黙の書き起こし表現を作り、その後に言語モデルとしての推論を進めるため、同じ言語モデルを組み合わせた自動音声認識→言語モデルのカスケードと、出力だけでなく失敗の仕方まで似やすいです。
- この仮説を確かめるために、複数の音声大規模言語モデルと複数タスクを対象として、内部で使われる言語モデルの種類をそろえた対応カスケードを構築し、例ごとの一致度や同じ誤答の出やすさ、さらに内部表現の解析と情報除去の介入で、テキスト表現が実際に必要かどうかまで検証しています。
- その結果、Ultravoxは対応カスケードと統計的に区別しにくい高い一致が示される一方で、Qwen2-Audioは一致が低い場面が残り、等価性は普遍ではなく設計に依存し、しかも雑音下ではWhisperベースのカスケードが有利になり得ることが示されています。
なぜこの問題か
音声を直接入力してテキスト応答を生成する音声大規模言語モデルは、従来の「自動音声認識で文字起こしを作り、その文字列をテキスト言語モデルに渡す」という手順を省ける仕組みとして位置づけられています。こうした端から端までの音声処理には、文字起こしでは失われがちな韻律、感情、強調といった音響的な手がかりまで活用できるという期待が伴います。その期待のもとで、離散的な音声トークン、学習された接続器、クロスアテンション、二重エンコーダなど、多様な設計が提案され、投資も進んできました。しかし、設計の多様さがそのまま内部処理の多様さにつながっているかどうかは、十分に検証されていません。
核心:何を提案したのか
本研究の中心は「カスケード等価仮説」です。音声入力を A、音声から得られる文字起こしを T、課題ラベルを Y としたとき、文字起こしが課題に必要な情報をほぼ保っているなら、追加の音響情報が役立つ余地は小さくなります。この直観を、音声と文字起こしの情報量の差(音響的な上乗せ)として捉え、上乗せがほぼゼロに近い課題を「テキスト十分」、韻律などが効いて文字起こしだけでは足りない課題を「テキスト不十分」と整理します。そして、テキスト十分な課題では、音声大規模言語モデルは「同じ言語モデルを使った」自動音声認識→言語モデルのカスケードと、例ごとの出力レベルで見分けがつきにくくなるはずだ、という形で仮説を明確化します。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related