Vision Transformerのスケーリング:画像中心のワークロードにおけるDeepSpeedの評価
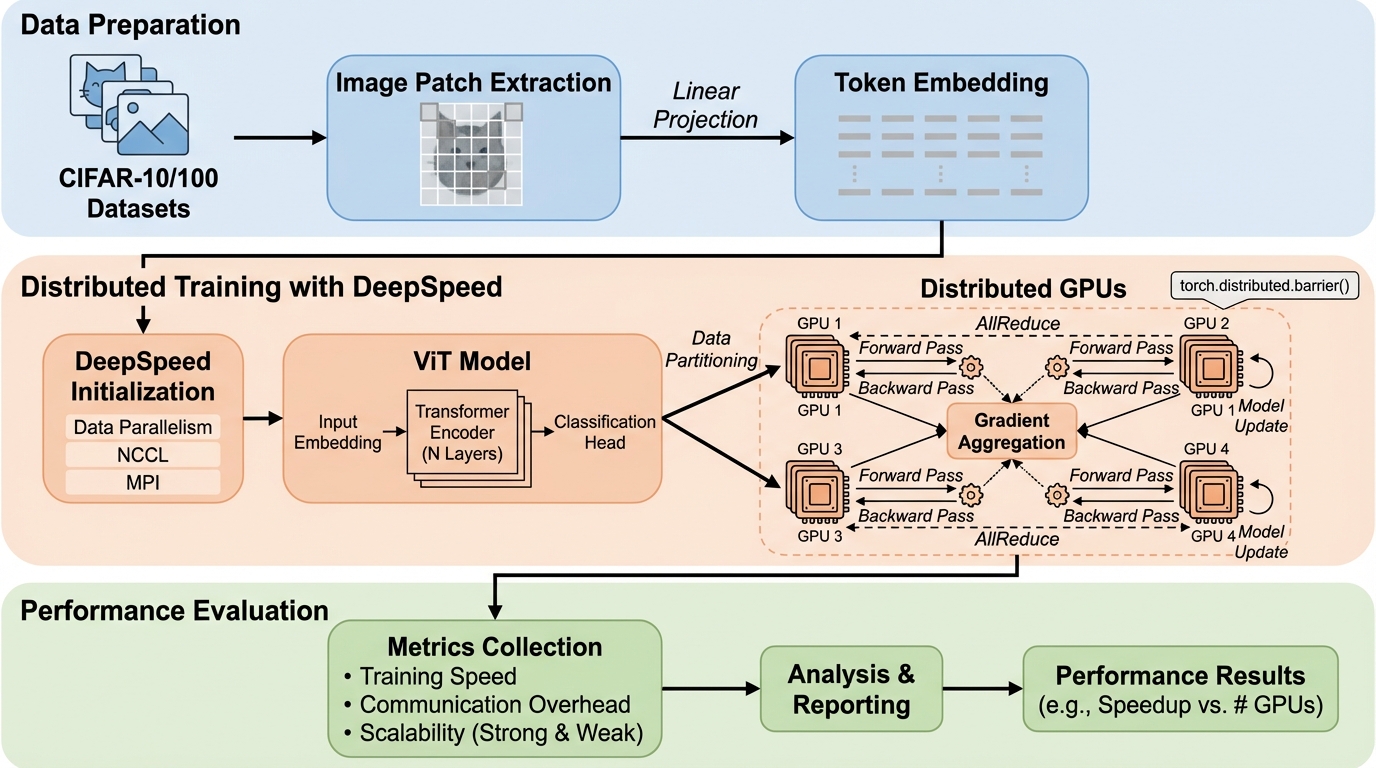
Vision Transformerは画像内のパッチ間の関係を自己注意で同時に扱える一方、計算量とメモリ要求が大きく、GPUを増やしても学習が素直に速くならない状況が起こり得ます。 / 本研究はDeepSpeedをVision Transformer(ViT b16)の学習に組み込み、ノード内・ノード間のデータ並列を複数GPU構成で動かし、学習時間・通信オーバーヘッド・強いスケーリングと弱いスケーリングの傾向を、主にCIFAR-10とCIFAR-100で追跡しています。 / 実測では、GPUの同質性が崩れると同期待ちが増えてスケーリングが乱れやすく、またバッチサイズを大きくすると同期コストが下がる傾向が見られ、64または128が通信とメモリの折り合いとして有望だと整理されています。
TL;DR(結論)
- Vision Transformerは画像内のパッチ間の関係を自己注意で同時に扱える一方、計算量とメモリ要求が大きく、GPUを増やしても学習が素直に速くならない状況が起こり得ます。
- 本研究はDeepSpeedをVision Transformer(ViT b16)の学習に組み込み、ノード内・ノード間のデータ並列を複数GPU構成で動かし、学習時間・通信オーバーヘッド・強いスケーリングと弱いスケーリングの傾向を、主にCIFAR-10とCIFAR-100で追跡しています。
- 実測では、GPUの同質性が崩れると同期待ちが増えてスケーリングが乱れやすく、またバッチサイズを大きくすると同期コストが下がる傾向が見られ、64または128が通信とメモリの折り合いとして有望だと整理されています。
なぜこの問題か
Transformerは自然言語処理で使われてきた深層学習アーキテクチャですが、画像領域にも拡張され、Vision Transformer(ViT)として画像分類や物体検出などに使われています。ViTの要点は、画像を固定サイズのパッチに分割し、それらをトークンとして扱って特徴ベクトル列に埋め込み、Transformerエンコーダへ入力する点にあります。畳み込みニューラルネットワークが畳み込み層で段階的に特徴を抽出するのに対し、ViTは自己注意によって画像全体を見渡す形で、すべてのパッチ間の相互作用を同時に扱えると説明されています。 一方で、この自己注意を中核に置く設計は、モデルやデータが大きくなるほど計算コストとメモリ要求が増えやすく、スケーラビリティの障害になります。特に分散学習では、計算を分けられても勾配同期などの通信が増え、通信待ちが計算削減分を打ち消すことがあります。したがって「GPUを増やすほど速い」という単純な期待が崩れる条件を、具体的に見極める必要があります。…
核心:何を提案したのか
本研究の中心的な狙いは、DeepSpeedをVision Transformerの学習に適用し、画像中心の分散学習でスケーリングの傾向を観察できる「基礎的な評価の土台」を作ることです。具体的には、ノード内(同一ノードの複数GPU)とノード間(複数ノードにまたがるGPU)の両方で、データ並列(Data Parallelism)を動作させ、GPU数を増やしながら学習時間、通信オーバーヘッド、精度の変化を測ります。ここでの関心は、単に速くなるかだけではなく、どの条件で効率が落ちるのか、通信が支配的になるのか、あるいは設定で改善できるのかを整理する点にあります。 また、強いスケーリングと弱いスケーリングを明示的に分けて評価します。強いスケーリングでは仕事量(データセット全体)を固定し、GPU数を増やしたときに学習時間がどれだけ短くなるかを見ます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related