SOTAlign:少数ペアと大量の非ペアで視覚と言語をそろえる半教師ありアラインメント
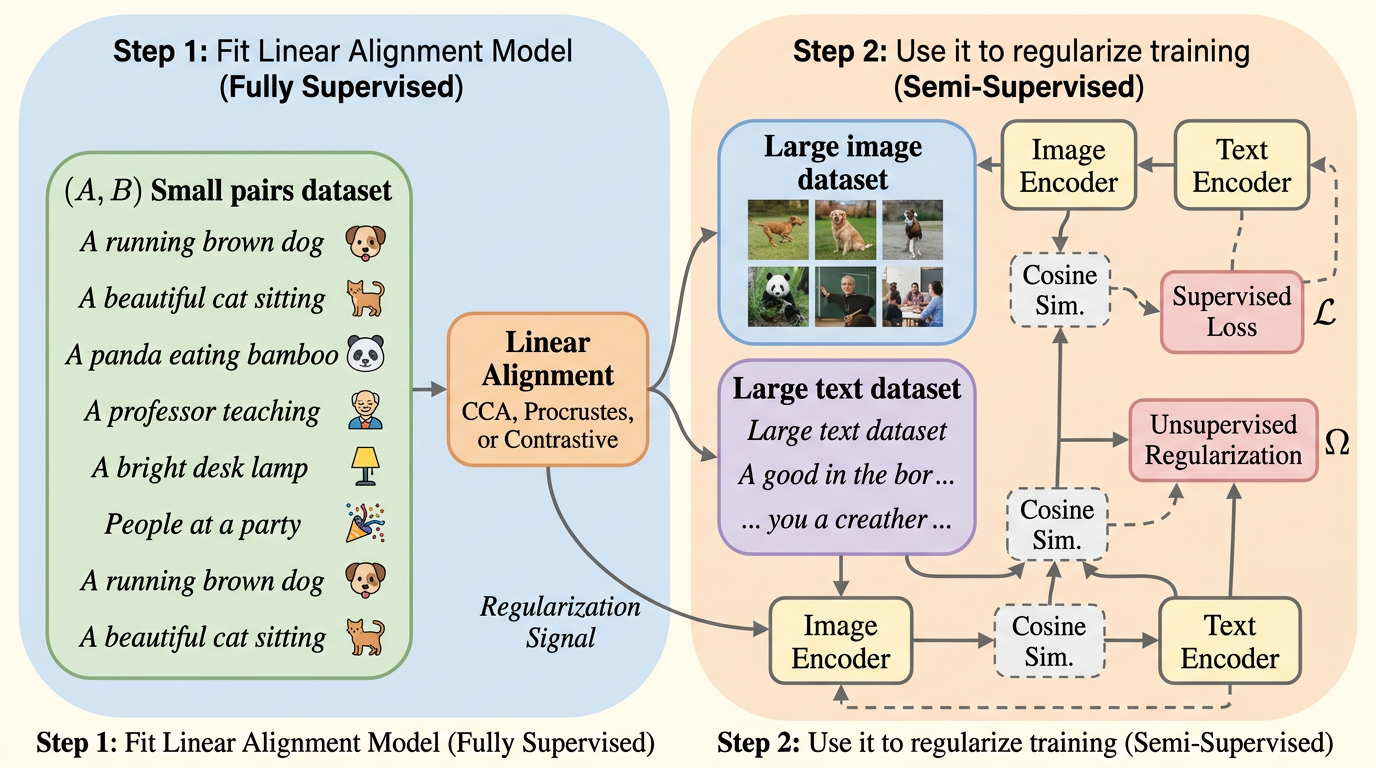
SOTAlign は、少数の画像・テキスト対と大量の非ペアデータを使って、視覚と言語の表現空間をそろえる半教師あり手法です。線形教師で作った粗い共通幾何を KLOT により非ペア側へ移し、検索やゼロショット分類で既存手法を広く上回ります。
論文図解
TL;DR(結論)
- SOTAlign は、少数の画像・テキスト対と大量の非ペア画像・非ペアテキストを使って、視覚と言語の表現空間をそろえる半教師あり手法です。
- まず少量のペアで線形教師を作り、その幾何構造を KLOT という最適輸送ベースの距離で非ペア側へ移す二段階構成が効きます。
- COCO / Flickr30k の検索や ImageNet のゼロショット分類で、既存の supervised / semi-supervised baselines を広く上回り、同程度の性能に必要なペア監督量を大きく減らせます。
なぜこの問題か
視覚と言語の共通空間があれば、ゼロショット分類、検索、クロスモーダル転移など、多くの応用が可能になります。ただ、主流の方法は大量の paired image-text data を必要とします。医療、産業、科学、監視、法務のような特殊領域では、ペア作成そのものが高価で、そこがボトルネックになります。
核心:何を提案したのか
提案の中心は、少量の paired data から作った線形教師の関係構造を、非ペアデータを使ってより柔軟な alignment layers へ移すことです。重要なのは、「ペアが無い非ペア画像と非ペアテキストの間で、無理に擬似的な一対一対応を作らない」ことです。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related