Squint:視覚強化学習を「分」で回し、15分学習の方策をSim-to-RealでSO-101へゼロショット展開する高速SAC
Squintは、カメラ画像と自己受容情報から操作方策を学習する視覚SACで、並列シミュレーションと経験再利用を両立させつつ、学習の実時間を従来の視覚オフポリシー法・オンポリシー法より短くすることを狙った手法です。
TL;DR(結論)
- Squintは、カメラ画像と自己受容情報から操作方策を学習する視覚SACで、並列シミュレーションと経験再利用を両立させつつ、学習の実時間を従来の視覚オフポリシー法・オンポリシー法より短くすることを狙った手法です。
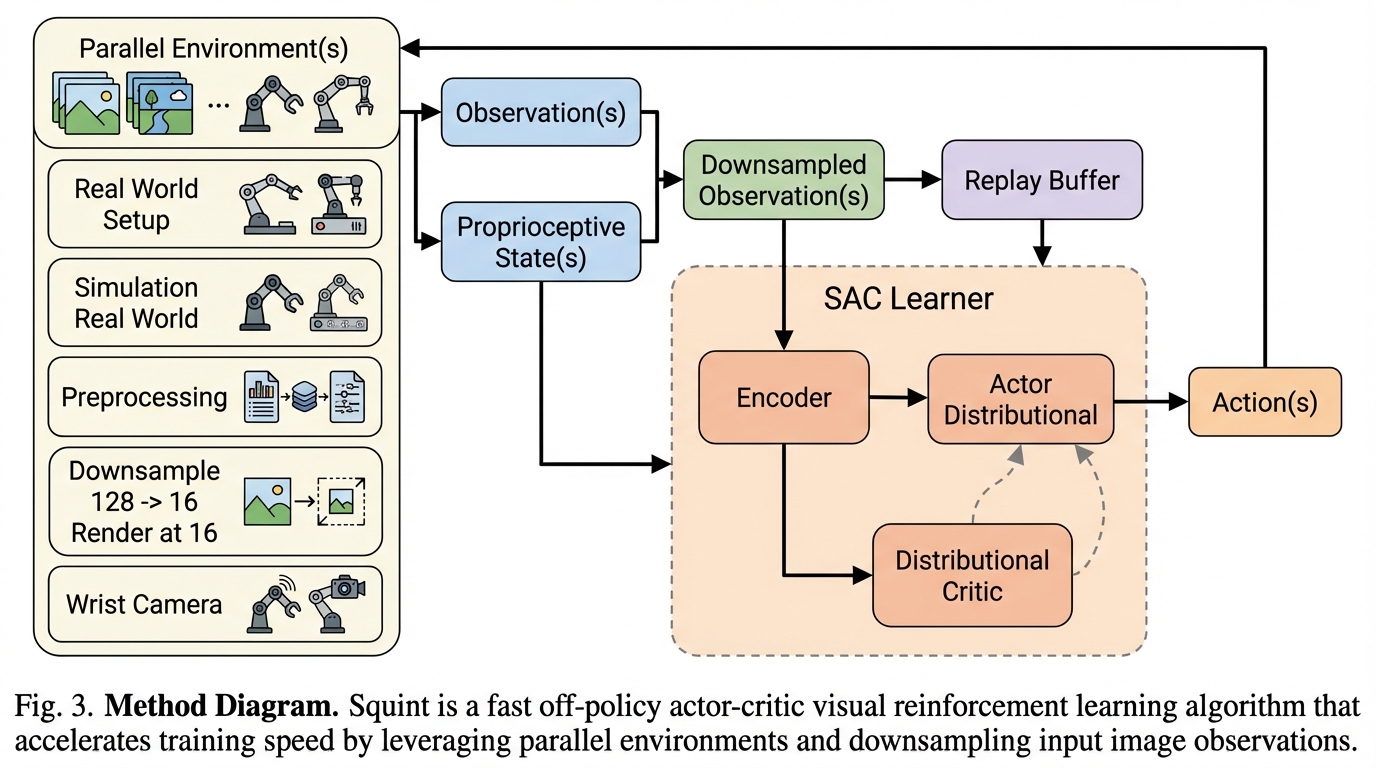
- 分布型(C51)クリティック、128×128で描画して16×16へ面積ダウンサンプルする「スクイント」、Layer Normalization、更新回数とデータ量の比(UTD比)の調整、さらにPyTorch compileやcudagraphs、AMP bfloat16などの実装最適化を組み合わせ、画像入力で生じる保存・エンコードの負担を抑えます。
- ManiSkill3上のSO-101 Task Set(8タスク)で、単一のRTX 3090により15分学習し多くが6分未満で収束したとされ、15分時点のシミュレーション平均成功率96.1%と、実機SO-101での80試行平均91.3%(ゼロショット展開)を報告しています。
なぜこの問題か
視覚強化学習は、ロボットにカメラ入力を与えるだけで方策を学ばせられるため、タスクごとの特別な計測や追加の計装に依存しにくい点が魅力です。しかし、画像にもとづく方策学習は一般に学習コストが高く、環境との相互作用回数が増えやすいことに加えて、計算資源や時間の負担が増大しやすいと整理されています。特に、オフポリシー手法はリプレイバッファに経験を蓄えて再利用できる一方で、学習更新の計算が重くなり、学習の実時間が伸びやすいという問題意識が提示されています。逆に、オンポリシー手法は経験再利用がないためサンプル効率は不利になりやすいものの、多数の環境に素直に並列化でき、GPUで加速されたシミュレータでは実時間の短さが強みになりやすいと説明されています。 近年、状態入力中心の制御では、オフポリシーでも実時間を優先して調整することでオンポリシーより速く学習できる可能性が示されてきましたが、画像入力に拡張することは容易ではないとされています。理由として、高次元な画像はリプレイバッファの保存負荷が大きく、畳み込みネットワークによるエンコード計算も増え、学習の動力学自体も難しくなる点が挙げられています。…
核心:何を提案したのか
提案はSquintという、視覚入力向けのSoft Actor Critic(SAC)ベースのオフポリシー手法です。目標は、従来の視覚オフポリシー手法および視覚オンポリシー手法よりも、学習の実時間を短くすることです。単一の工夫で解決するのではなく、画像入力でボトルネックになりやすい要素を複数箇所から同時に詰める設計としてまとめられています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related