物体中心表現は合成的一般化に強いのか――視覚VQAベンチマークによる体系比較
見慣れた属性を材料に「未学習の組み合わせ」を扱う合成的一般化では、物体中心(OC)表現がとくに難しい条件で優位になりやすく、データ量・多様性・下流計算量のいずれかが制約されると強みが出やすいです。
TL;DR(結論)
- 見慣れた属性を材料に「未学習の組み合わせ」を扱う合成的一般化では、物体中心(OC)表現がとくに難しい条件で優位になりやすく、データ量・多様性・下流計算量のいずれかが制約されると強みが出やすいです。
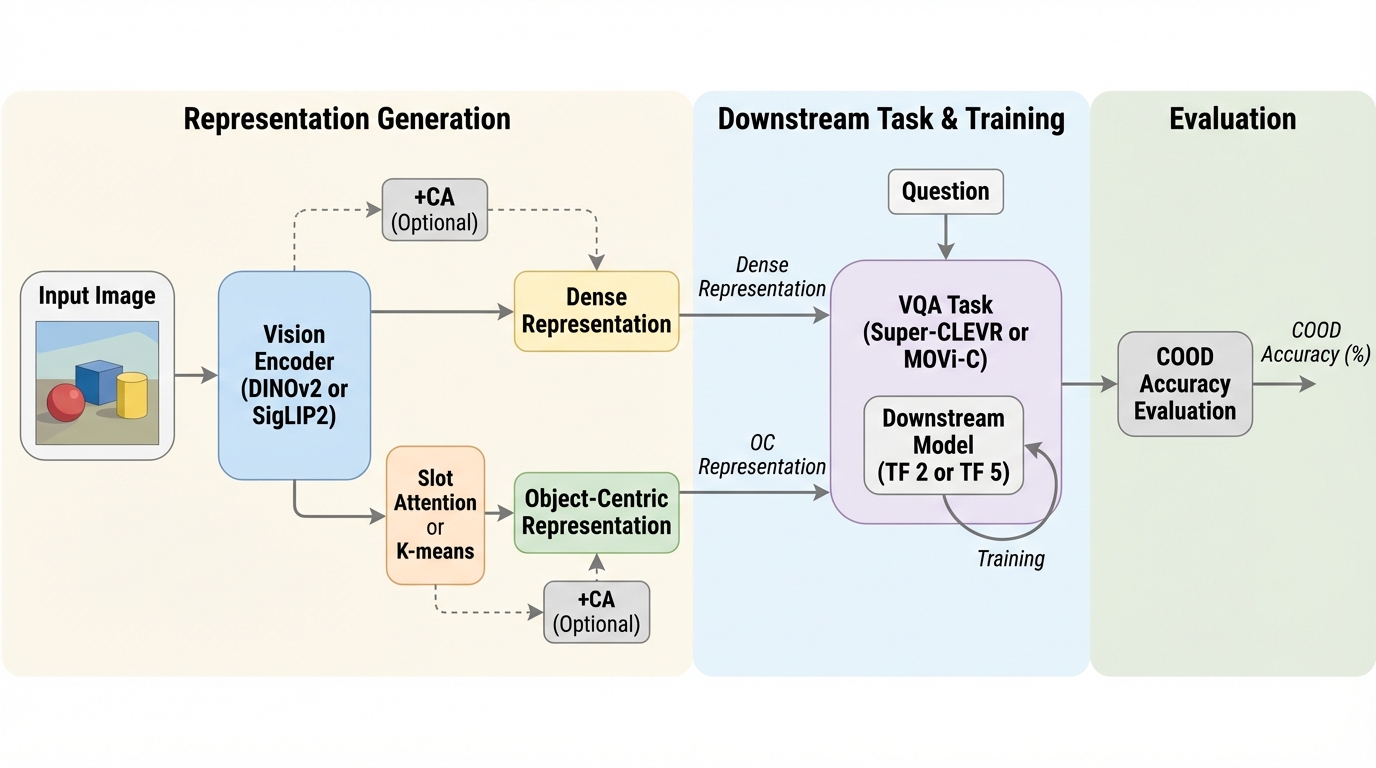
- CLEVRTex、Super-CLEVR、MOVi-Cの制御された視覚世界で、物体属性の組み合わせを意図的に保持した合成的分布外(COOD)テストを用意し、DINOv2とSigLIP2および各OC版を表現サイズや下流モデル容量などを揃えて比較しています。
- 易しい条件では密な(Dense)表現が上回る場合がある一方、より大きな下流計算資源や十分なデータ多様性が必要になりやすく、制約下での実運用を考えるとOC表現は有力な選択肢になり得ます。
なぜこの問題か
合成的一般化は、すでに知っている概念の「新しい組み合わせ」に対しても推論できる能力であり、人間の認知の基本的な性質として重要視されています。機械学習でも同様に重要ですが、学習時に登場した要素自体は理解していても、その組み合わせが変わるだけで性能が不安定になることがあるとされています。自然言語では、単語や数の並べ替え、再結合に対して正しく応答できるかで合成的一般化を確かめられますし、視覚でも「見たことのある属性を組み替えて新しい物体を作る」「既知の物体を新しい配置で組み合わせる」といった設定で問題を作れます。 一方、実務的な観察として、視覚言語モデルが紛らわしい負例に弱いことや、テキストから画像を生成するモデルがプロンプトに含める実体が増えるほど品質が落ちやすいことが指摘されています。規模の拡大だけではこの種の弱さが解消しにくく、未知の組み合わせで精度低下が残り、事前学習データ内での出現頻度や多様性への依存が見られるという報告もあります。 こうした背景から、合成的一般化をより自然に支える視覚表現が求められてきました。…
核心:何を提案したのか
本研究の提案は、物体属性の合成(object property composition)に焦点を当て、視覚エンコーダが「未学習の属性組み合わせ」にどれだけ一般化できるかを、視覚質問応答(VQA)で測るベンチマークを整備することです。舞台として、CLEVRTex、Super-CLEVR、MOVi-Cという3つの制御された視覚世界を用い、物体の属性要因(例として形状・素材・サイズなど)の組み合わせを明示的に管理します。ここで重要なのは、テストで出す「未学習の組み合わせ」を、学習データから意図的に除外する設計です。個々の属性値(たとえば色や形状に相当する要素)は学習で見ていても、その“組”としては学習に出ないように分割し、合成的一般化そのものを測りやすくしています。 加えて本研究は、公平で包括的な比較を強く意識しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related