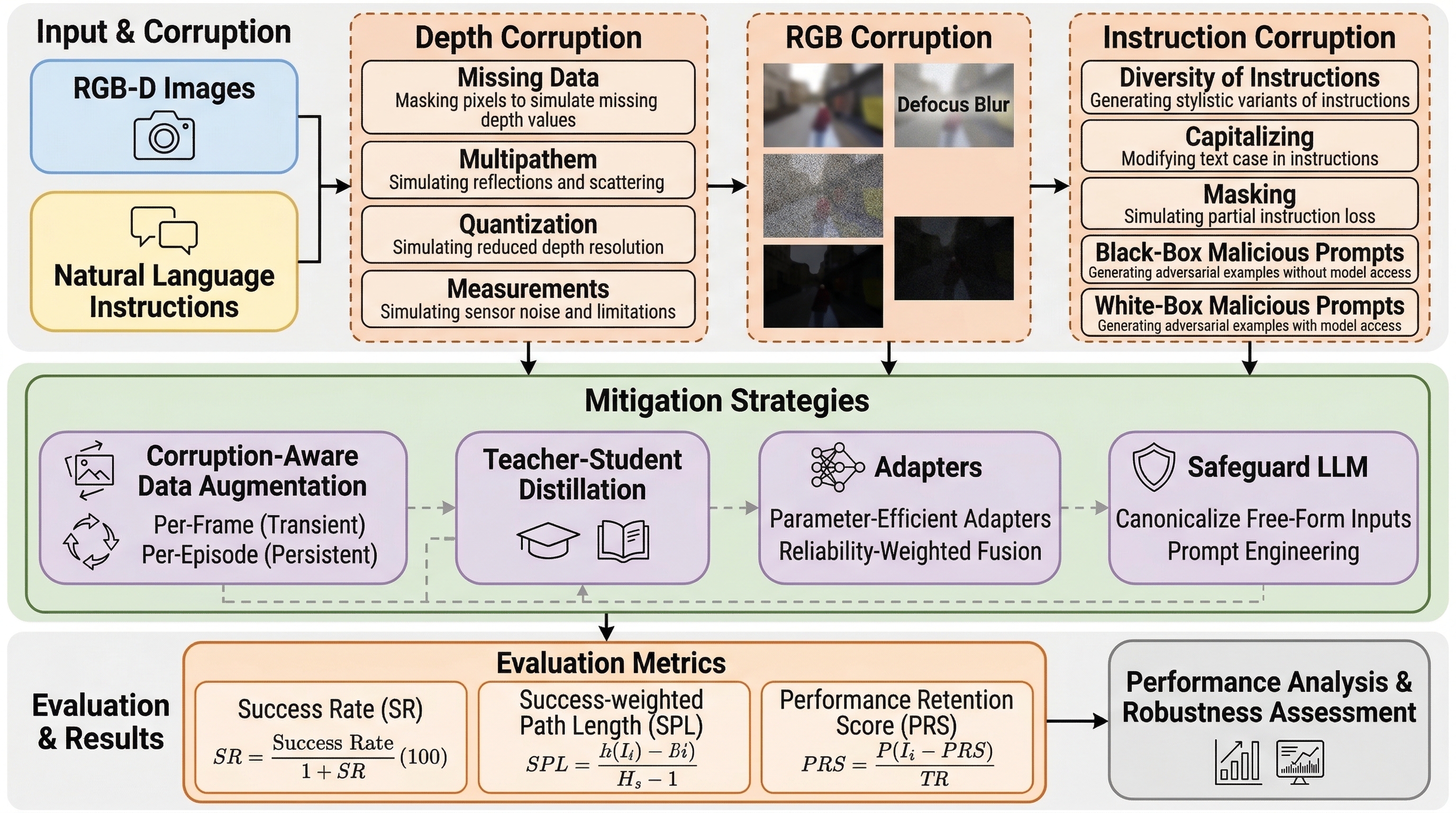
NavTrust:壊れたセンサーと壊れた指示で、Embodied Navigation はどこまで崩れるか
NavTrust は、視覚と言語によるナビゲーションと物体目標ナビゲーションを同じ枠組みで評価しながら、RGB、深度、指示文の破損を系統的に注入して、実世界に近い条件でどれだけ信頼性が崩れるかを測るベンチマークです。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
NavTrust は、視覚と言語によるナビゲーションと物体目標ナビゲーションを同じ枠組みで評価しながら、RGB、深度、指示文の破損を系統的に注入して、実世界に近い条件でどれだけ信頼性が崩れるかを測るベンチマークです。
視覚言語モデルが、ロボットの経路そのものに対する自然言語の好みをどこまで理解できるかを、軌道選択課題として系統的に測った研究です。single-query 方式と Qwen2.5-VL が強く、近接性にはかなり反応できる一方で、path style や幾何的比較にはまだ弱さが残ります。
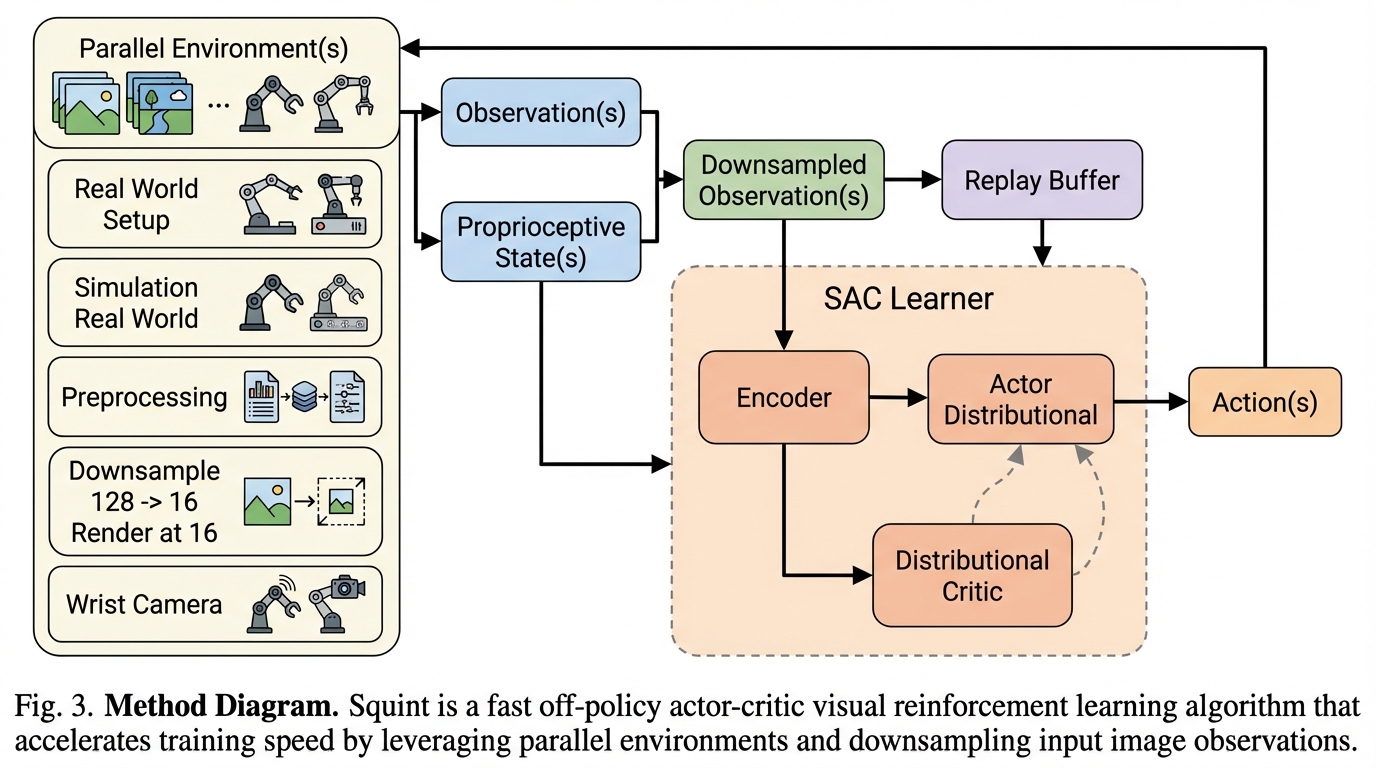
Squintは、カメラ画像と自己受容情報から操作方策を学習する視覚SACで、並列シミュレーションと経験再利用を両立させつつ、学習の実時間を従来の視覚オフポリシー法・オンポリシー法より短くすることを狙った手法です。
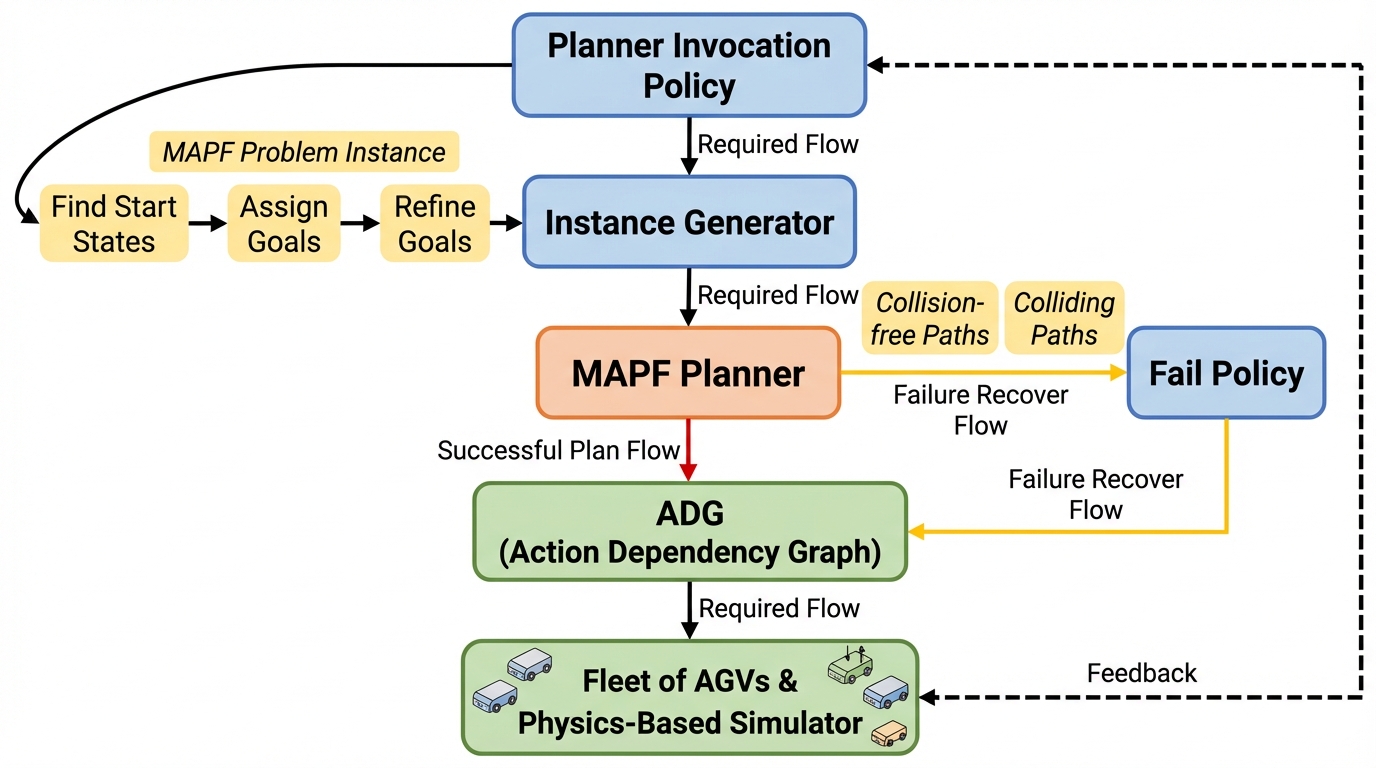
LSMARTは、中央集権の生涯型フリート管理システムでAGV群を動かす状況を対象に、任意の多エージェント経路探索を現実的な実行条件(運動学、通信遅延、実行時間のばらつき)込みで評価できるオープンソースの試験基盤です。
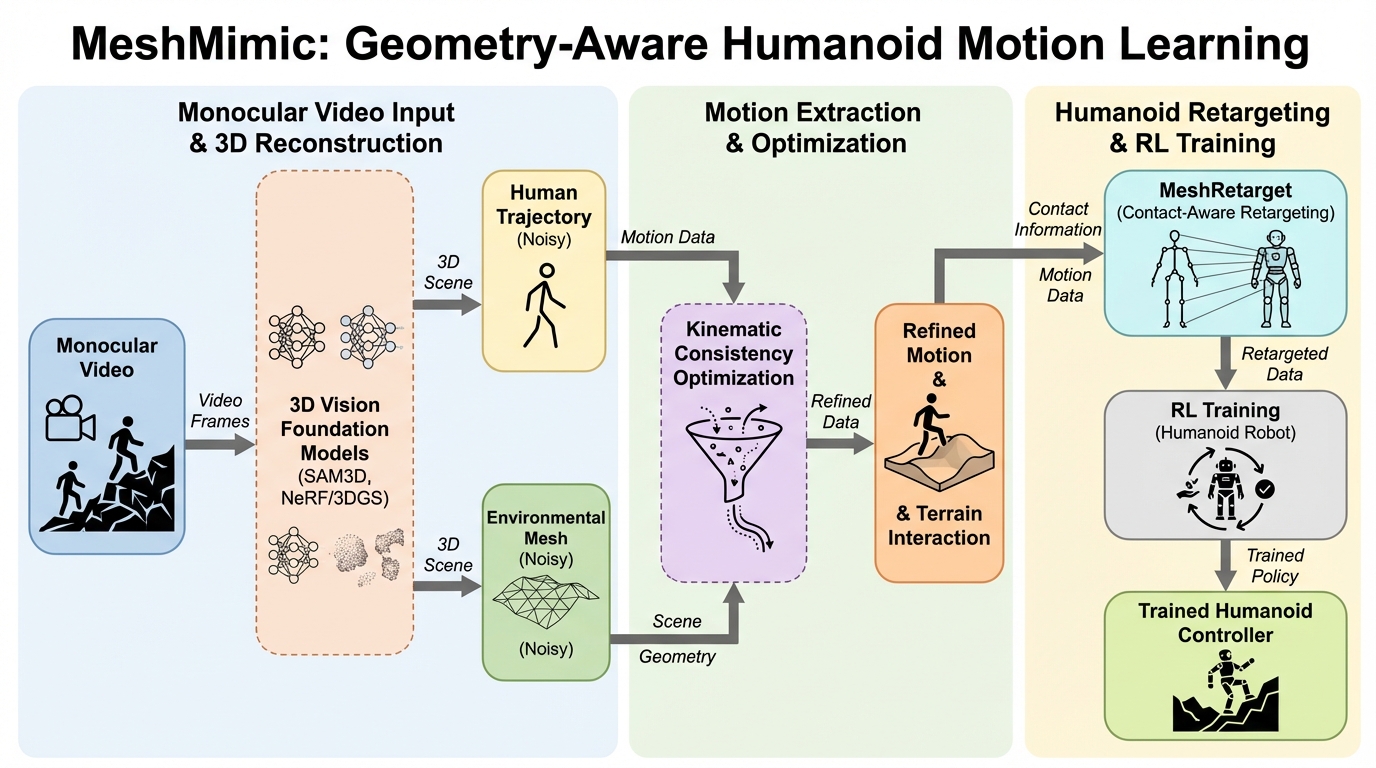
MeshMimicは、単眼の動画から人の動きだけを取り出すのではなく、その動きが成立している地形や物体の三次元形状も同時に復元し、動作と地形の相互作用を結び付けた参照データとしてヒューマノイドの学習に使う枠組みです。
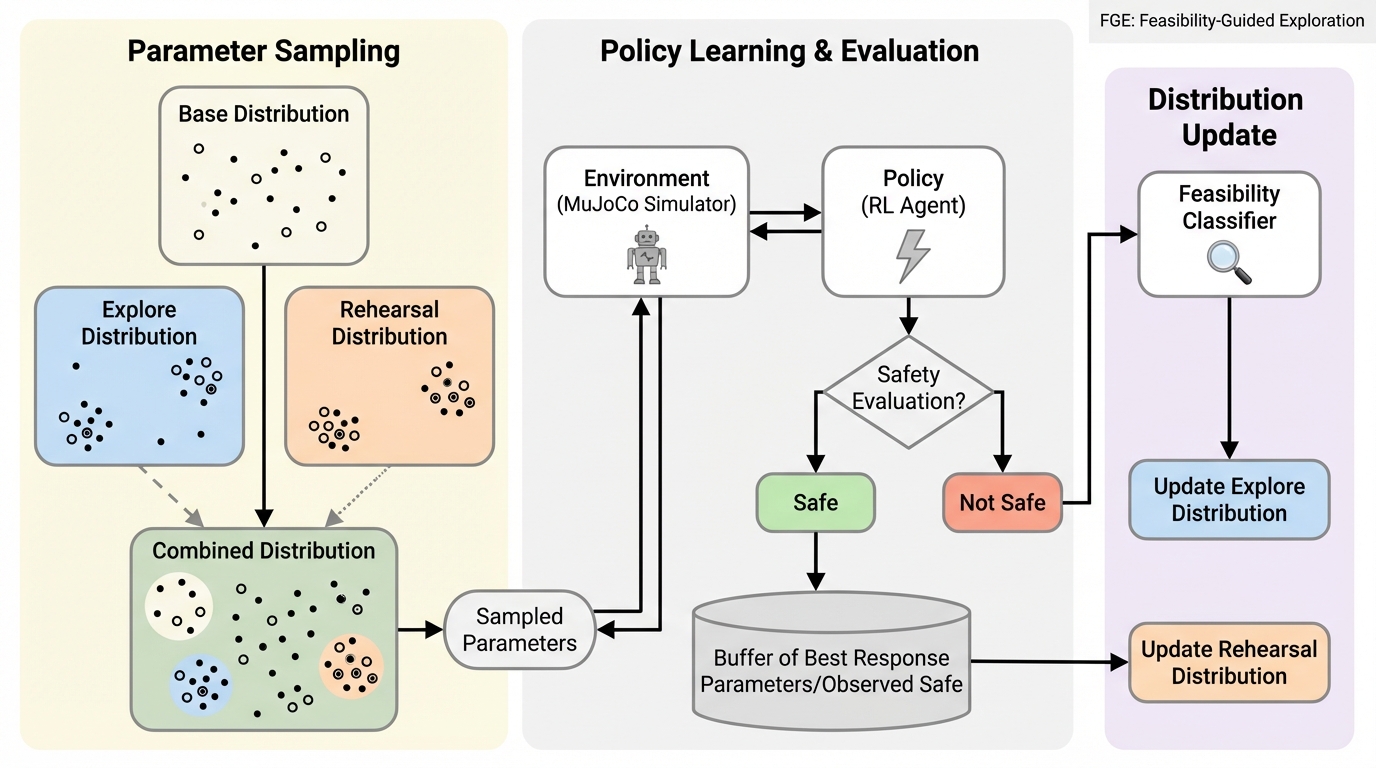
安全集合を最大化して「ずっと安全」を保証したい目的と、強化学習がユーザ指定の分布に対する期待値を最適化しやすい目的のずれにより、確率は低いが本来は安全にできる状態で方策が破綻しやすくなります。 / そこで、初期状態・ダイナミクス・安全仕様を決めるパラメータ集合のうち「安全な方策が存在する部分集合」を探索で広げながら、その部分集合上で最悪条件に耐える回避方策を学習するFGEを提案しています。 / MuJoCo上の高次元回避問題の実験では、難しい初期条件において既存最良手法よりカバレッジが50%を超えて増え、最悪条件がそもそも不可能な設定でも学習が停滞しにくい方向性を示しています。
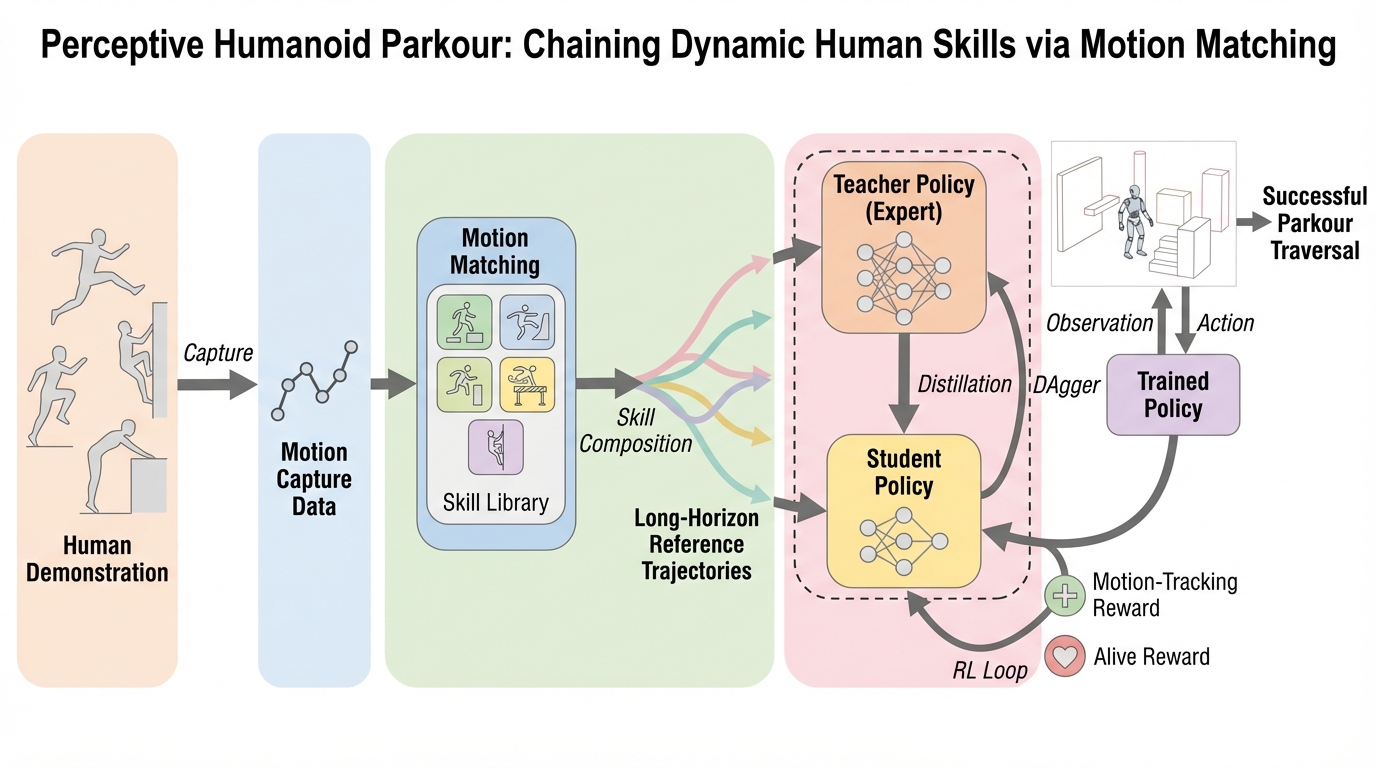
少数で短い人間の高ダイナミクス動作データからでも、ヒューマノイドが視覚にもとづいて障害物コースを長時間にわたり自律走破できるようにする、モジュール型の枠組みが示されています。 / Motion Matchingを特徴空間での最近傍探索として使い、歩行・走行と原子スキルをつないで長時間の参照軌道を合成し、その参照を追従する複数の強化学習専門家を学習したうえで、DAggerと強化学習を組み合わせて深度入力の単一方策へ蒸留します。 / Unitree G1の実機で、深度センサと離散的な2次元速度指令だけを用い、約3 m/sの跳び越えや1.25 m(身長の96%)までの壁登り、60秒の連続走破、障害物の摂動に対する閉ループ適応が確認されています。
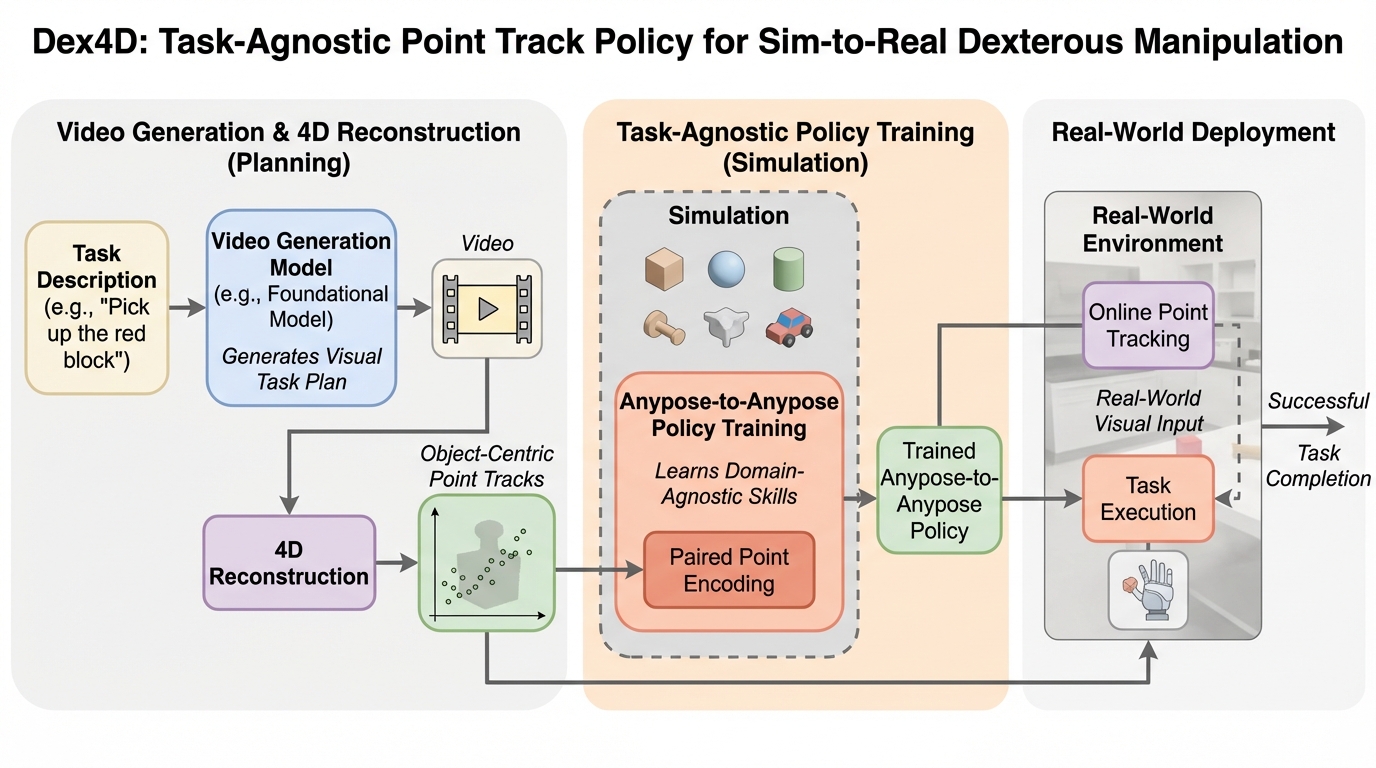
Dex4Dは、個別タスクごとの環境設計や報酬設計を増やすのではなく、「物体を現在姿勢から目標姿勢へ動かす」という共通能力をシミュレーションで学び、実機の多様な巧緻操作へつなげる枠組みです。 / 目標は言語そのものではなく、生成動画と4D再構成から得る物体中心の3D点トラックで与え、実行中はオンライン点追跡で現在の点を更新しながら、点トラック条件付きポリシーで閉ループ制御します。 / シミュレーションと実機の広範な実験により、ファインチューニングなしのゼロショット展開、先行ベースラインに対する成功率・タスク進捗・頑健性の一貫した改善、そして新規物体や背景などへの強い汎化が報告されています。
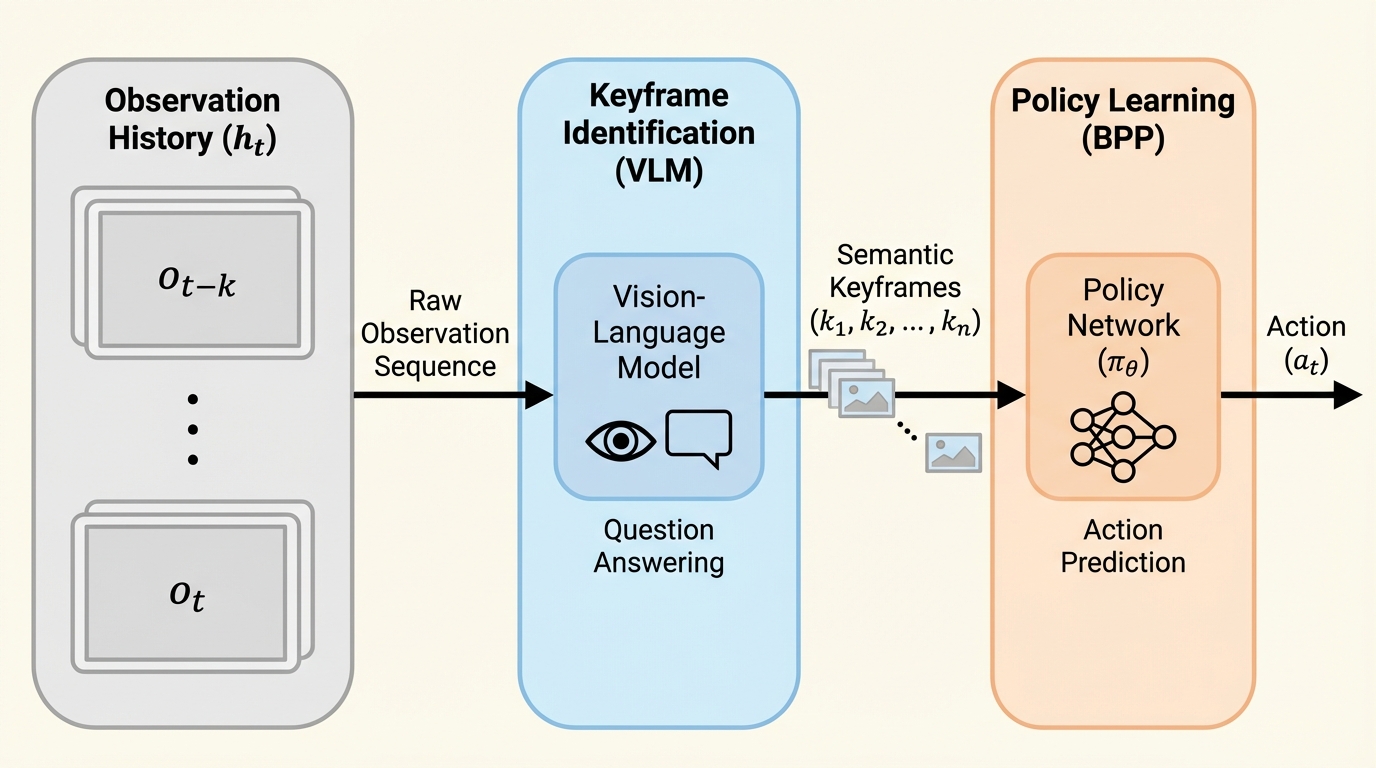
ロボットが過去の出来事を覚える必要があるタスクでは、観測履歴をそのまま入力に足すだけでは学習時の履歴に含まれる偶然の手掛かりへ依存しやすく、運用時に少し軌跡がずれただけで未学習の履歴に遭遇して失敗が連鎖しやすいと分析されています。
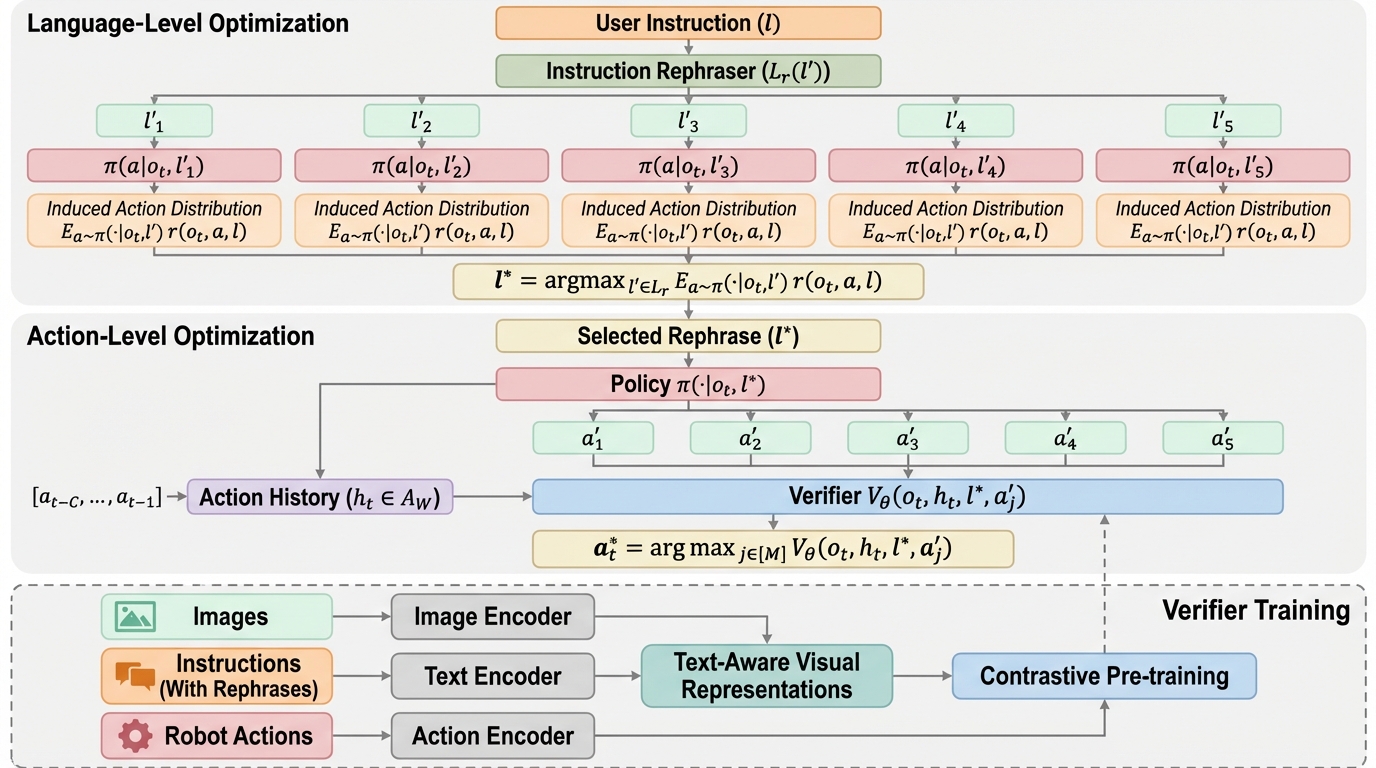
汎用ロボットの実現を阻む「意図と行動のギャップ」を解消するため、本研究はポリシー学習の強化ではなく、推論時の検証(テスト時スケーリング)を拡張する新フレームワーク「CoVer-VLA」を提案しました。