BPP:重要な履歴キーフレームに注目して長い文脈を扱うロボット模倣学習
ロボットが過去の出来事を覚える必要があるタスクでは、観測履歴をそのまま入力に足すだけでは学習時の履歴に含まれる偶然の手掛かりへ依存しやすく、運用時に少し軌跡がずれただけで未学習の履歴に遭遇して失敗が連鎖しやすいと分析されています。
TL;DR(結論)
- ロボットが過去の出来事を覚える必要があるタスクでは、観測履歴をそのまま入力に足すだけでは学習時の履歴に含まれる偶然の手掛かりへ依存しやすく、運用時に少し軌跡がずれただけで未学習の履歴に遭遇して失敗が連鎖しやすいと分析されています。
- 履歴の可能性はホライズンとともに指数的に増えるため、データ収集だけで履歴空間を十分に覆えないという「カバレッジ不足」が根にあり、正則化や補助目的で損失を工夫してもタスクによって効き方が不安定になりやすい点が問題視されています。
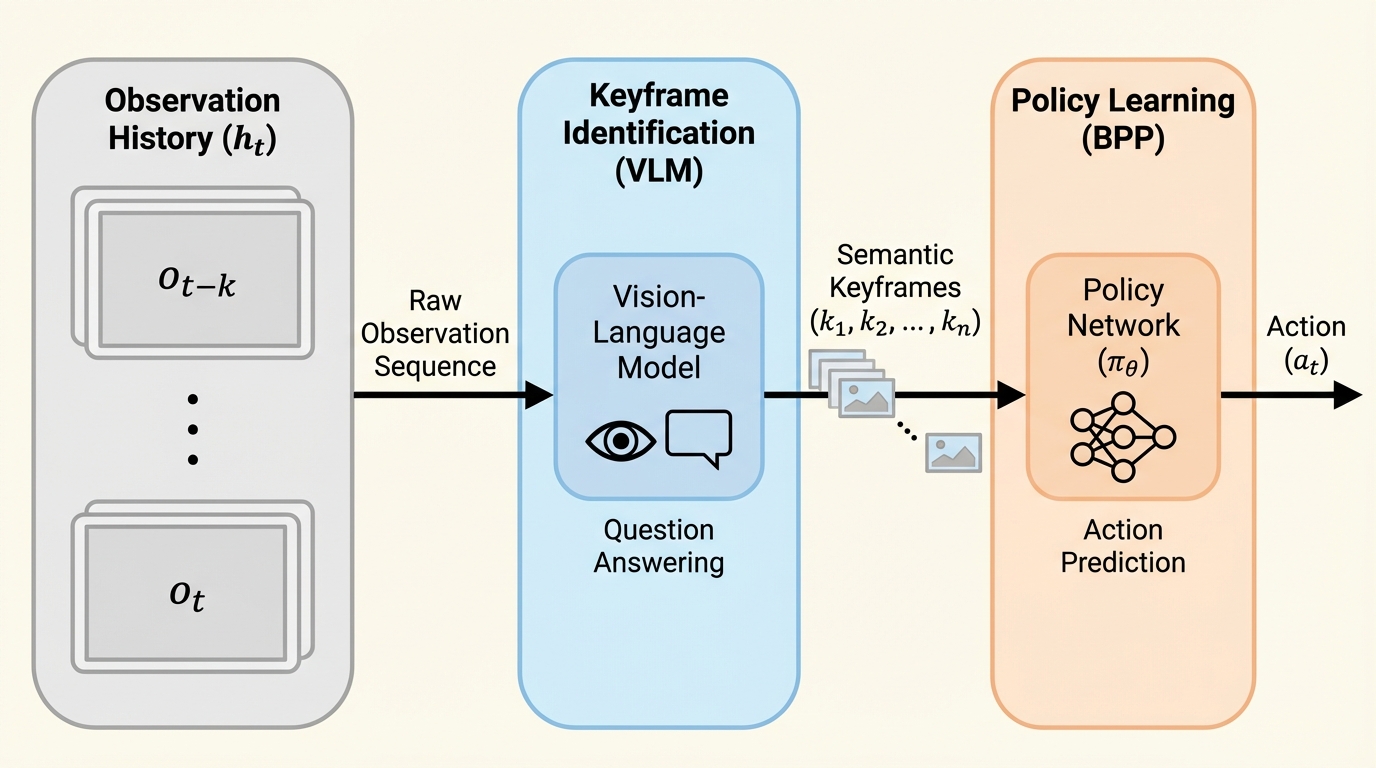
- そこで、視覚言語モデル(VLM)で履歴からタスク関連の少数キーフレームを質問応答で抽出し、その圧縮表現に方策を条件付けるBPPを提案し、実世界評価では最良の比較手法より成功率が70%高いと報告されています。
なぜこの問題か
ロボットの作業には、現在の観測だけでは次の行動が一意に決まらず、過去に何をしたかを踏まえないと成功できない状況があります。論文では、部屋の中で物を探す例として、すでにどこを探索したかを覚えていないと同じ場所を探し続けてしまう点が挙げられています。また、材料を正確な回数だけ追加する作業や、複数段階の手順を進める作業では、初期のミスや進捗が後からの観測だけでは分かりにくいことがあり、履歴に基づく推論が必要になります。ところが、模倣学習で高い性能を出している方策は、現在の観測のみに条件付けるものが多く、こうした非マルコフ的なタスクにそのまま適用しづらいとされています。 では観測履歴を入力に加えればよいかというと、履歴へ素朴に条件付けする方法は失敗しやすいと整理されています。理由は、学習データの履歴にたまたま含まれていた特徴が専門家行動の説明に使えてしまうと、方策がそれに「しがみつき」、運用時の分布外(OOD)軌跡で一般化できなくなるためです。運用では方策が少しでも専門家から外れると、学習で見ていない履歴を自分で作り出し、その誤りが積み重なる形で崩れていきます。…
核心:何を提案したのか
著者らは、長い観測履歴そのものを方策に与えるのではなく、履歴を「意味のある少数の瞬間」に写像してから方策を学習させる設計として、Big Picture Policies(BPP)を提案しています。狙いは、履歴条件付き模倣学習が抱えるカバレッジ不足を、データ収集や学習目的の変更ではなく、入力表現の変更で回避することです。非マルコフ的なタスクでは、成功に必要な情報が履歴のすべてに散らばっているとは限らず、「把持できたか」「サブゴールを達成したか」「失敗が起きたか」といった行動上の重要イベントは少数である、という見立てが前提にあります。そこでBPPは、履歴全体を保持しようとする代わりに、こうしたイベントに対応するキーフレームだけを抽出し、その集合に条件付けて行動を予測します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related