Dex4D:生成動画から得た点追跡を条件に、シミュレーション学習だけで実機の巧緻操作へ展開するタスク非依存ポリシー。
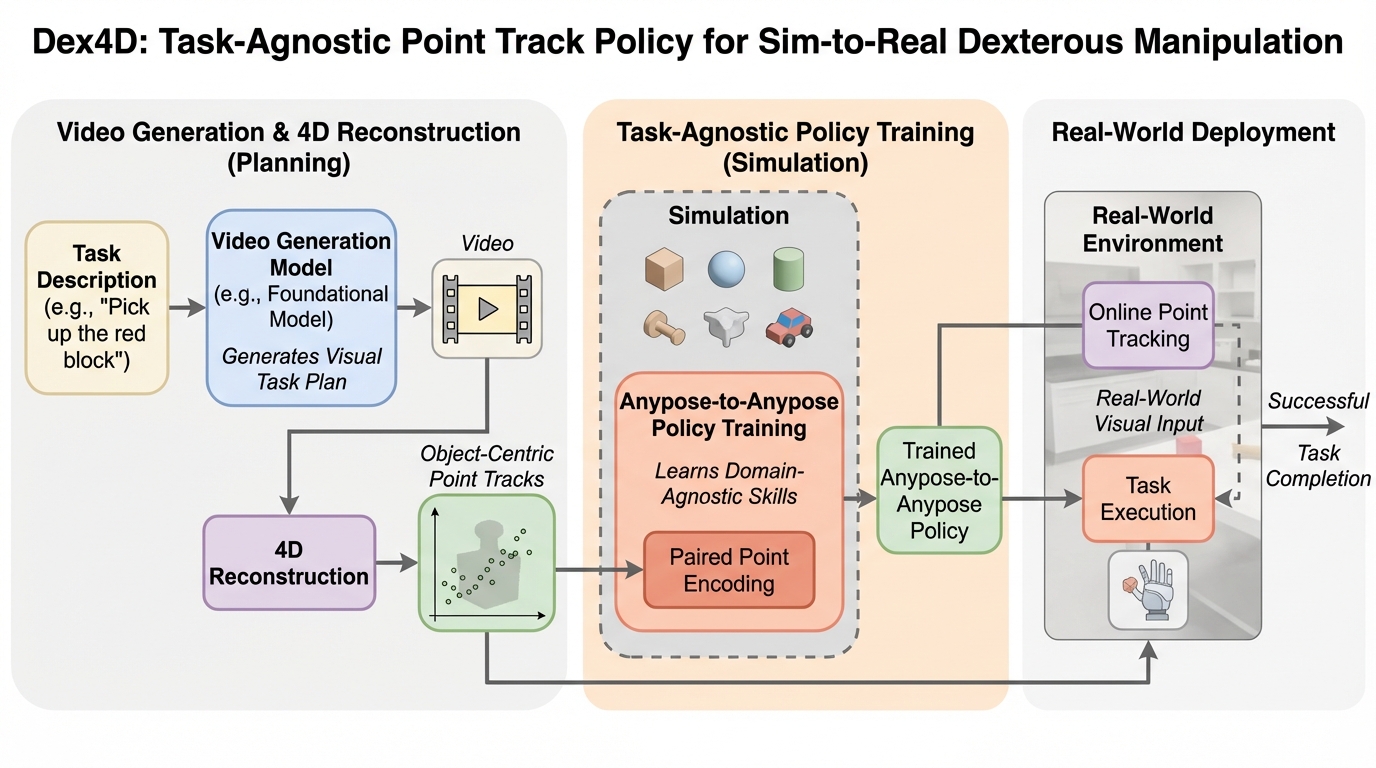
Dex4Dは、個別タスクごとの環境設計や報酬設計を増やすのではなく、「物体を現在姿勢から目標姿勢へ動かす」という共通能力をシミュレーションで学び、実機の多様な巧緻操作へつなげる枠組みです。 / 目標は言語そのものではなく、生成動画と4D再構成から得る物体中心の3D点トラックで与え、実行中はオンライン点追跡で現在の点を更新しながら、点トラック条件付きポリシーで閉ループ制御します。 / シミュレーションと実機の広範な実験により、ファインチューニングなしのゼロショット展開、先行ベースラインに対する成功率・タスク進捗・頑健性の一貫した改善、そして新規物体や背景などへの強い汎化が報告されています。
TL;DR(結論)
- Dex4Dは、個別タスクごとの環境設計や報酬設計を増やすのではなく、「物体を現在姿勢から目標姿勢へ動かす」という共通能力をシミュレーションで学び、実機の多様な巧緻操作へつなげる枠組みです。
- 目標は言語そのものではなく、生成動画と4D再構成から得る物体中心の3D点トラックで与え、実行中はオンライン点追跡で現在の点を更新しながら、点トラック条件付きポリシーで閉ループ制御します。
- シミュレーションと実機の広範な実験により、ファインチューニングなしのゼロショット展開、先行ベースラインに対する成功率・タスク進捗・頑健性の一貫した改善、そして新規物体や背景などへの強い汎化が報告されています。
なぜこの問題か
巧緻操作で「日常の多様なタスクをこなせる汎用ポリシー」を学習する際、最大の障壁は高品質で多様なデータを十分な規模で集めにくい点です。実機でテレオペレーションにより操作軌道を大量収集する方法は、費用が高く、計測や運用も難しく、スケールしにくいと述べられています。さらに、多自由度で高速に動くロボットハンドは操作者が精密に扱うこと自体が難しく、収集が遅くなり誤りも入りやすいという問題が重なります。そこで代替としてシミュレーション学習が有力になりますが、今度は「タスクごとに」環境を作り込み、指示やタスク記述を整え、報酬を設計し、学習手順を調整する工学的負担が大きいと整理されています。タスクの種類が増えるほど、設計・調整作業も増え続けるため、汎用化を狙うほど学習側の負担が膨らみやすい構造です。 著者らはこの状況に対し、言語で直接指示可能なタスク特化ポリシーを大量に作るよりも、並列化しやすいシミュレーションで「タスク非依存の基礎スキル」を先に獲得し、テスト時に柔軟に組み合わせる方針を取ります。…
核心:何を提案したのか
Dex4Dが提案する中心アイデアは、タスク名や手順の違いをいったん脇に置き、「任意の物体を任意の目標姿勢へ動かす」能力そのものを、点トラックを条件とするポリシーとして学習することです。この学習課題はAnypose-to-Anypose(AP2AP)として定義されており、タスク固有の構造、事前定義された把持、モーションプリミティブに依存しない形で、物体の姿勢変換を基本目的に据えています。学習はシミュレーション内で行い、多数の物体と多様な姿勢構成にまたがるロボット・物体相互作用を広くカバーし、テスト時に合成できるようにする方針です。 デプロイ時には、生成動画から抽出した「物体中心の3D点トラック」を目標として与えるだけで、実機にゼロショット転移でき、ファインチューニングは不要と説明されています。さらに実行中はオンライン点追跡を用いて、見えている物体点の位置を更新し続け、知覚と制御を閉ループ化します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related