視覚・言語・行動の整合性のためのスケーリング検証:ポリシー学習のスケーリングを超える効果の立証
汎用ロボットの実現を阻む「意図と行動のギャップ」を解消するため、本研究はポリシー学習の強化ではなく、推論時の検証(テスト時スケーリング)を拡張する新フレームワーク「CoVer-VLA」を提案しました。
TL;DR(結論)
- 汎用ロボットの実現を阻む「意図と行動のギャップ」を解消するため、本研究はポリシー学習の強化ではなく、推論時の検証(テスト時スケーリング)を拡張する新フレームワーク「CoVer-VLA」を提案しました。
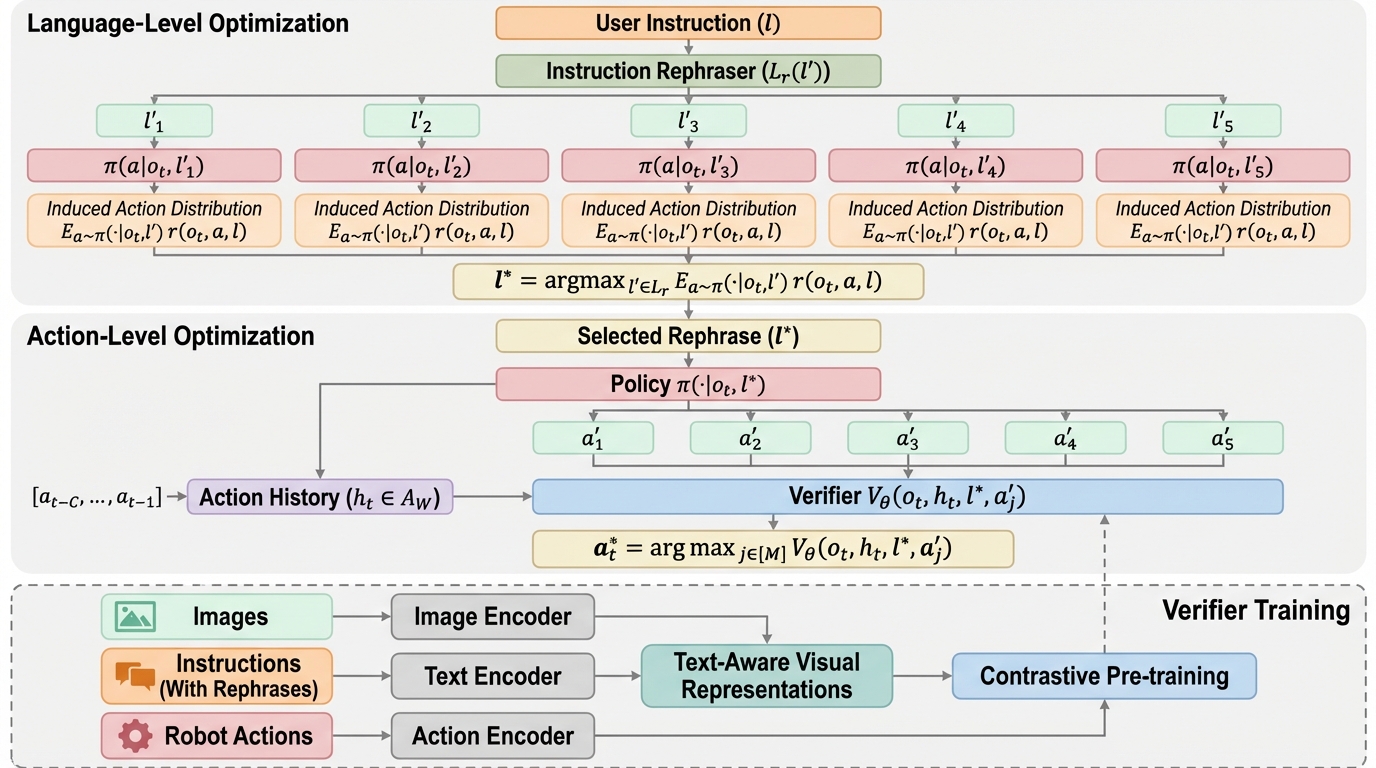
- 具体的には、対照学習を用いた検証器「CoVer」を導入し、実行前に視覚言語モデル(VLM)で指示を多様に言い換える「ブートタイム計算」と、最適な指示と言動を階層的に選択するパイプラインを構築しています。
- この手法により、実世界タスクで45%の性能向上を達成し、従来のポリシー学習のスケーリングと比較して7倍の学習効率で、シミュレーション環境においても大幅な成功率とタスク進捗の改善を確認しました。
なぜこの問題か
ロボットが人間と共生する環境で実用化されるためには、自然言語による指示を正確に理解し、それに基づいた適切な行動を実行する能力が不可欠です。近年の視覚・言語・行動(VLA)モデルは、大規模なマルチモーダルデータを用いた事前学習によって、多様なタスクへの適応能力を示してきました。しかし、これらのモデルには依然として「意図と行動のギャップ(intention-action gap)」という深刻な課題が残っています。これは、モデルが生成する行動が、与えられた言語指示の意図と食い違ってしまう現象を指します。 例えば、ロボットに「プラスチックの容器を引き出しに入れる」という指示を与えた場合、ロボットは容器を正しく掴むことには成功しても、その後の移動先で引き出しと近くにあるオーブンを混同し、誤ってオーブンの中に容器を置いてしまうことがあります。このような誤りは、プラスチックが溶けたり火災を引き起こしたりするなど、実世界での運用において致命的なリスクを伴います。…
核心:何を提案したのか
本論文では、VLAモデルの整合性を向上させるために、ポリシー学習をスケールさせるよりも「テスト時の検証(Verification)」をスケールさせる方が、計算効率と性能の両面で優れているという新たな視点を提案しました。この核心となる提案が、対照学習を用いた検証器「CoVer(Contrastive Verifier)」と、それを利用した階層的なテスト時検証パイプラインです。このフレームワークは、ロボットが推論時(テスト時)に追加の計算資源を投入し、生成された行動と指示の整合性を自ら評価・選択できるようにするものです。 提案手法の大きな特徴の一つは、「ブートタイム計算(boot-time compute)」という概念の導入です。これは、ロボットが実際の動作を開始する前の待機時間に、VLMを用いてシーン内のオブジェクトや空間関係を詳細に推論し、元の指示を意味的に等価な複数の表現に言い換えておくプロセスです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related