MeshMimic:3Dシーン再構成を組み込んで、単眼動画から地形と一体でヒューマノイド動作を学ぶ
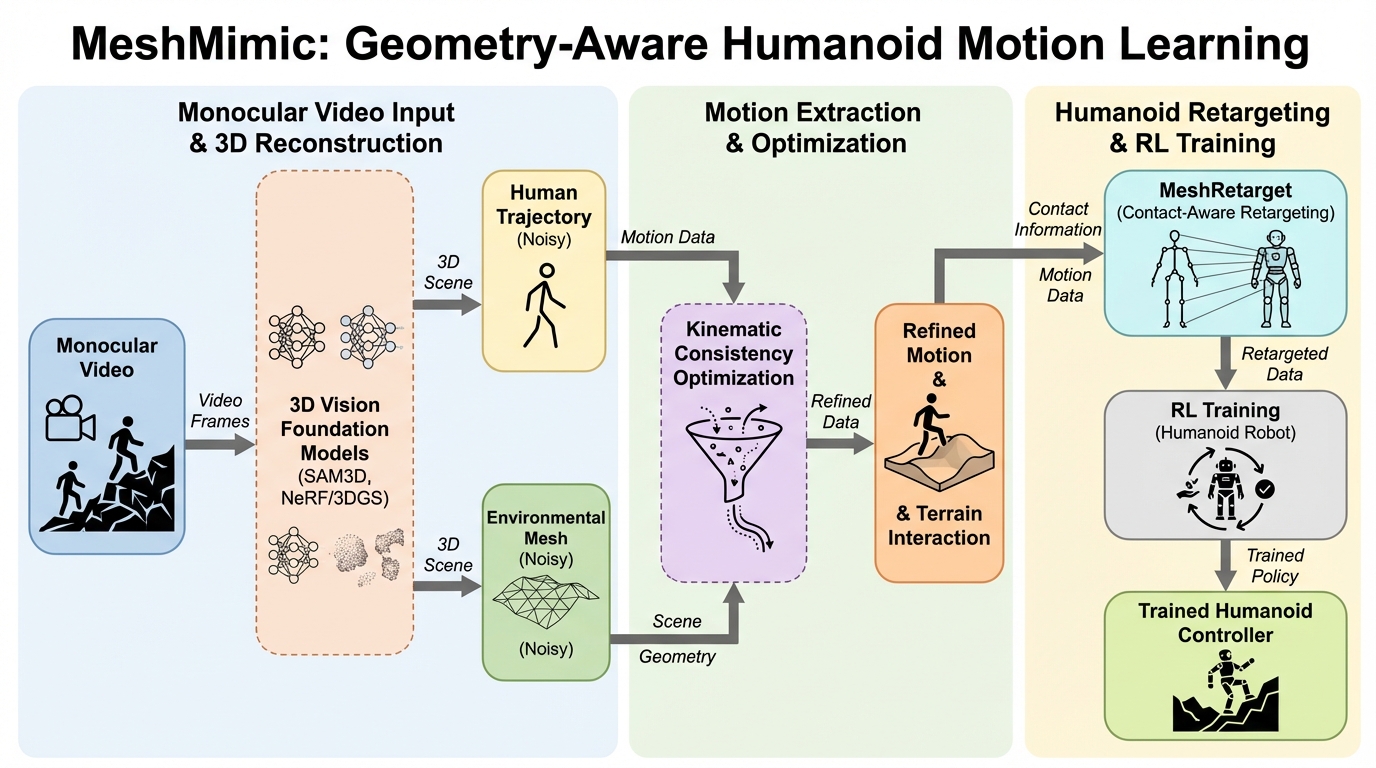
MeshMimicは、単眼の動画から人の動きだけを取り出すのではなく、その動きが成立している地形や物体の三次元形状も同時に復元し、動作と地形の相互作用を結び付けた参照データとしてヒューマノイドの学習に使う枠組みです。
TL;DR(結論)
- MeshMimicは、単眼の動画から人の動きだけを取り出すのではなく、その動きが成立している地形や物体の三次元形状も同時に復元し、動作と地形の相互作用を結び付けた参照データとしてヒューマノイドの学習に使う枠組みです。
- 先進的な三次元視覚モデルで人物と環境を分離して再構成したうえで、運動学的一貫性にもとづく最適化により、遮蔽や深度誤差などで生じる浮き・めり込み・軌跡の不安定さを抑え、接触条件を重視したMeshRetargetで形態差をまたいで相互作用を移します。
- 不規則な地形上の動的タスクを含む検証で、地形を無視しがちな手法に比べて頑健性と物理的な整合性が高い結果を示したと報告され、一般的な単眼センサだけで複雑な物理相互作用の学習データを拡張できる可能性を示します。
なぜこの問題か
ヒューマノイドの運動制御は、深層強化学習(RL)の進展により、人らしい複雑な挙動を獲得できるようになってきた一方で、自由度が高く力学が複雑なため、手作業で動作や報酬を設計することが現実的ではないと整理されています。そこで、参照動作を与えて模倣させる動作模倣が中心的な流れになりますが、従来は高価なモーションキャプチャ(MoCap)への依存が大きい点が問題として挙げられています。さらに重要な点として、MoCapは動作自体は高精度でも、周囲の物理環境の幾何学的文脈を十分に含まない場合が多く、動作とシーンが切り離されたまま学習が進みやすいと説明されています。 この切り離しは、地形を意識すべきタスクで顕在化しやすく、接触の滑り(いわゆる足のずれ)、接触位置の不一致、メッシュの貫通といった物理的不整合につながるとされています。実運用の観点でも、慣性・光学式のMoCapを現場に持ち込みにくい状況は多く、動画から学習データを得たい動機が強いと述べられています。動画利用の方向性としてVideoMimicが言及されていますが、粗いシーンモデルに頼りやすく、接触の細かな最適化が不足しやすい点が課題として位置付けられています。…
核心:何を提案したのか
本研究はMeshMimicという枠組みを提案し、三次元シーン再構成と身体性をもつ知能を橋渡しして、単眼動画から「動作と地形が結合した相互作用(motion–terrain)」を学べるようにすると述べています。中心的な狙いは、MoCapに依存しがちな参照データ生成を、一般的な単眼動画へと広げながら、従来欠けやすかった環境幾何の文脈と接触整合を取り戻すことです。具体的には、先進的な三次元視覚モデルを用いて、人物を環境から分離し、人物軌跡と地形・物体の三次元幾何を精密に再構成します。 しかし単眼の復元にはノイズが入りやすく、遮蔽、不正確な深度推定、二次元キーポイントの揺らぎなどにより、接触が浮いたり、地形へめり込んだり、軌跡が不安定になったりすると説明されています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related