安いチェックをいつ信じるか:推論における弱い検証と強い検証
推論を含む大規模言語モデルの運用では、速くて安いが不完全な弱い検証と、信頼を確立しやすい一方で資源を要する強い検証の使い分けがボトルネックになりやすく、本論文はその緊張関係を「いつ強い検証に委ねるか」という意思決定として整理しています。
TL;DR(結論)
- 推論を含む大規模言語モデルの運用では、速くて安いが不完全な弱い検証と、信頼を確立しやすい一方で資源を要する強い検証の使い分けがボトルネックになりやすく、本論文はその緊張関係を「いつ強い検証に委ねるか」という意思決定として整理しています。
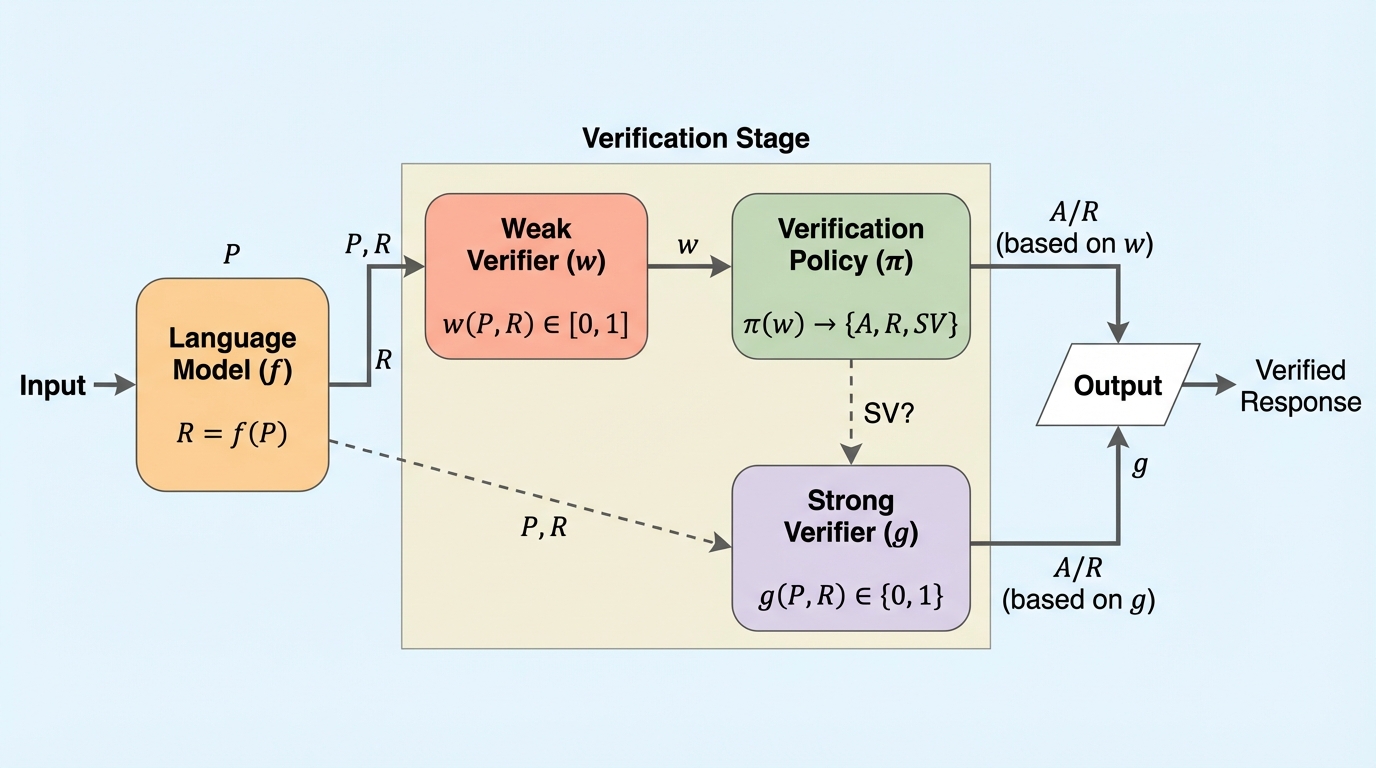
- 弱い検証スコアだけを見て「受理・却下・強い検証に回す」を選ぶポリシーを定式化し、誤って受理する割合、誤って却下する割合、強い検証を呼ぶ頻度という指標でトレードオフを測りつつ、母集団の観点では最適ポリシーが二つのしきい値で表せることや、弱い検証の有用性が較正と鋭さに左右されることを示します。
- さらに、問い合わせ列・言語モデル・弱い検証器に仮定を置かないオンライン手法(SSV)を提案し、弱い検証だけで判断した部分での弱い信号と強い信号の食い違いを制御しながら、実験では網羅的に強い検証を行う場合に近い信頼性を保ちつつ強い検証コストを抑えられることを示します。
なぜこの問題か
大規模言語モデル(LLM)の推論は、単発の生成で終わるというよりも、検証を挟みながら候補を更新していく「検証ループ」の中で運用される場面が増えています。論文は検証を二つに分けて考えており、内部で回せる安価なチェック(自己一貫性、代理的な報酬、学習された批評など)を弱い検証と呼び、外部で人が出力を吟味し、必要ならフィードバックでモデルを誘導するような確認を強い検証と呼んでいます。強い検証は、行ごとの目視確認や、領域によっては外部での試験なども含み得るため、文脈・嗜好・専門知識といったテキストに載りにくい情報も使えて信頼を作りやすい一方で、どうしても資源が必要になります。これに対して弱い検証は速くスケールしやすい反面、ノイズがあり不完全で、弱い検証だけで最終判断をすると誤受理や誤却下が起き得ます。 ここで難しいのは、弱い検証と強い検証が単に「精度が違う」だけでなく、意思決定の層が違う点です。弱い検証は候補のスコアリングや絞り込みには使われやすい一方で、「この場面では強い検証を呼ぶべきか」という上位の制御規則としては、原理立てて整理されていないことが多いと論文は述べています。…
核心:何を提案したのか
提案の核は、弱い検証と強い検証を同時に扱うための「弱い–強い検証ポリシー」の定式化です。各ラウンドでモデルが応答を出し、弱い検証がスコアを返したときに、ポリシーは三つの行動から一つを選びます。すなわち、強い検証を呼ばずに受理する、強い検証を呼ばずに却下する、あるいは強い検証に委ねてその判定に従う、という選択です。この枠組みにより、「安いチェックをどこまで信用してよいか」が、アルゴリズムが下す意思決定として明示されます。 次に論文は、この意思決定が生むトレードオフを三つの指標で捉えます。一つ目は誤受理で、強い検証なら不正解と判定されるはずの応答を、弱い検証だけで受理してしまう頻度です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related