いつでも有効な統計的ウォーターマーキングに向けて
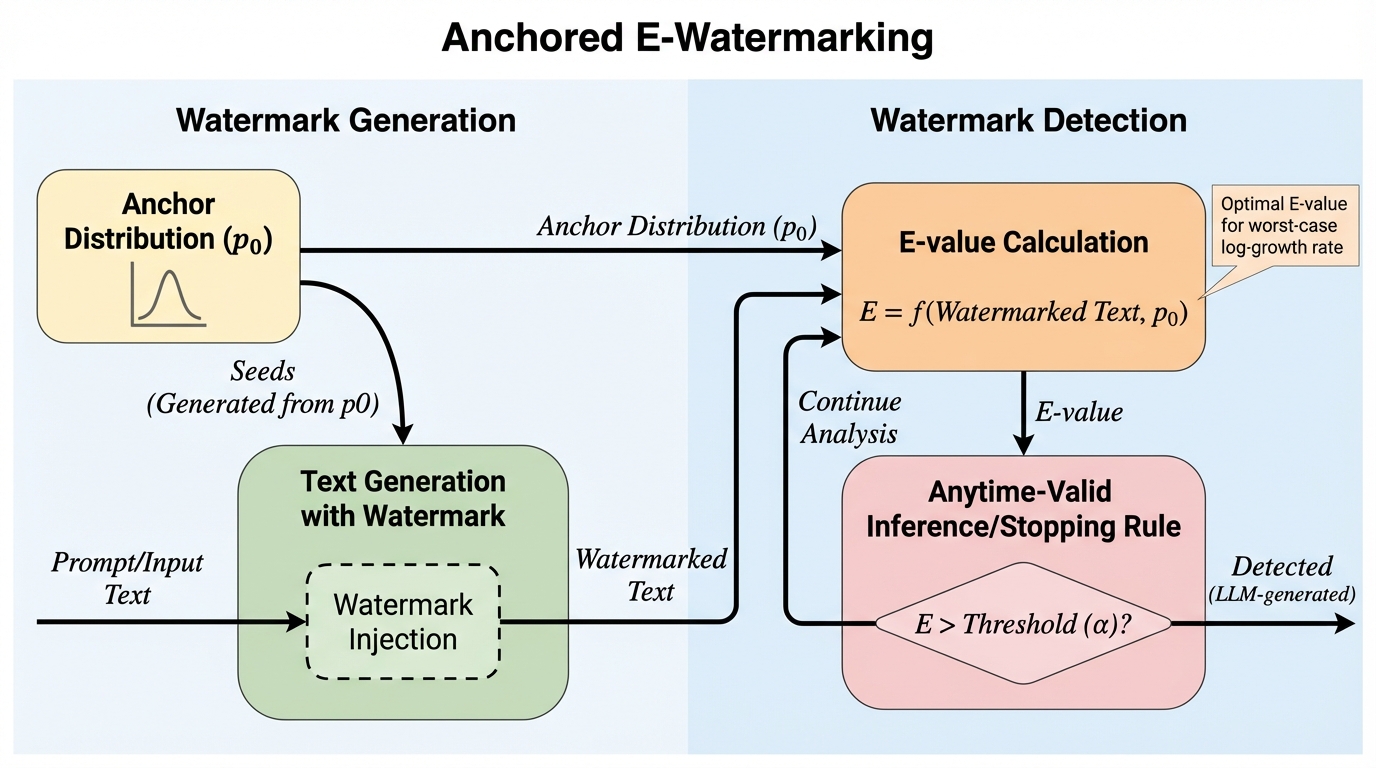
本論文は、統計的ウォーターマーキング検出を逐次(ストリーミング)で監視しながら、止めるタイミングをデータに応じて選んでも偽陽性(Type I error)の上限が崩れない枠組みを示しています。 / 生成側と検出側が共有するアンカー分布p0を導入し、ターゲット分布qがp0の近傍にあるという前提のもとで、トークンと疑似乱数シードの依存を埋め込みつつ、検出をe-value(非負のスーパー・マルチンゲール)として設計します。 / 理論として最悪ケースの対数成長率と期待停止時間の関係を与え、シミュレーションと既存ベンチマーク評価により、平均の検出トークン予算を最先端ベースラインより13〜15%削減できたと報告しています。
TL;DR(結論)
- 本論文は、統計的ウォーターマーキング検出を逐次(ストリーミング)で監視しながら、止めるタイミングをデータに応じて選んでも偽陽性(Type I error)の上限が崩れない枠組みを示しています。
- 生成側と検出側が共有するアンカー分布p0を導入し、ターゲット分布qがp0の近傍にあるという前提のもとで、トークンと疑似乱数シードの依存を埋め込みつつ、検出をe-value(非負のスーパー・マルチンゲール)として設計します。
- 理論として最悪ケースの対数成長率と期待停止時間の関係を与え、シミュレーションと既存ベンチマーク評価により、平均の検出トークン予算を最先端ベースラインより13〜15%削減できたと報告しています。
なぜこの問題か
大規模言語モデル(LLM)の普及により、人間が書いた文章と機械生成文を区別する信頼できる仕組みが必要だと論文は述べています。本文抜粋では、将来の学習コーパスが機械生成文で汚染されるリスク、偽情報の拡散、学術的不正といった社会的懸念が具体例として挙げられています。そこで注目されているのが、生成時のデコーディング過程に統計的な偏り(信号)を埋め込み、検出器が鍵に基づいてその痕跡を検定する統計的ウォーターマーキングです。本文抜粋は、この手法を「トークン列」と「疑似乱数シード列」の依存性を調べる仮説検定として定式化でき、検出力や必要なサンプル量がターゲット分布のランダム性に支配される統計問題になると説明しています。 しかし最先端の設計には、論文が強調する2つの根本問題があります。1つ目は、シード分布や生成・検出スキームの選び方がヒューリスティックに依存しがちで、アンカー分布を用いる発想があっても「与えられたアンカーのもとで何が最適か」という統一的な指針が不足している点です。…
核心:何を提案したのか
本論文の提案は、統計的ウォーターマーキング検出をp-valueではなくe-valueに基づく逐次推論へ移し替え、早期停止を含む任意の停止規則の下でもType I errorを制御できるようにすることです。著者らはこの目的のために、e-valueに基づく初のウォーターマーキング枠組みとしてAnchored E-Watermarkingを提示しています。中心にあるのは、検出の過程全体を「テスト用のスーパー・マルチンゲール」として構成し、観測を続けながらしきい値を超えた時点で止めても統計的な正当性が保たれるようにする発想です。これにより、固定長で回すしかなかった検出を、データ駆動で可変長に運用できることが狙いです。 同時に、生成・検出の「最適化」の指針も与える点が提案のもう一つの柱です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related