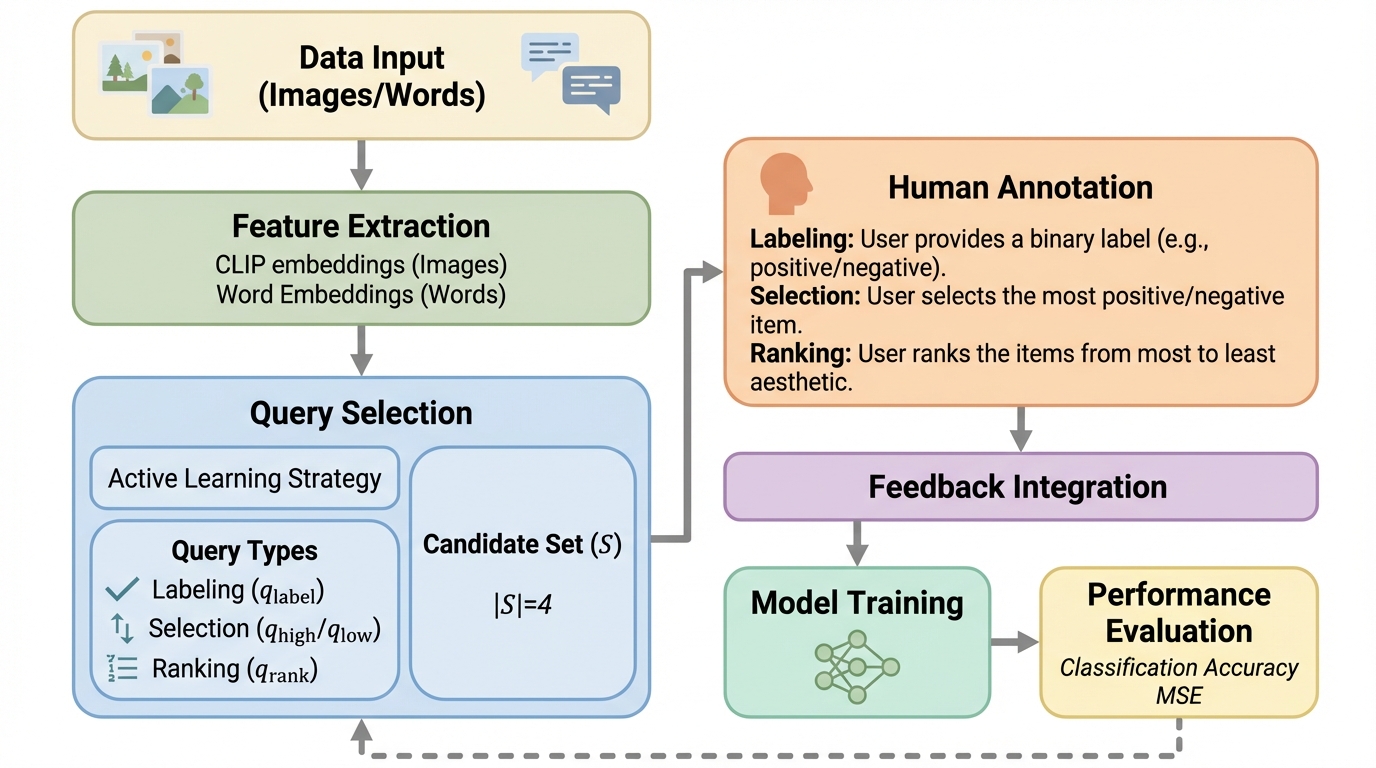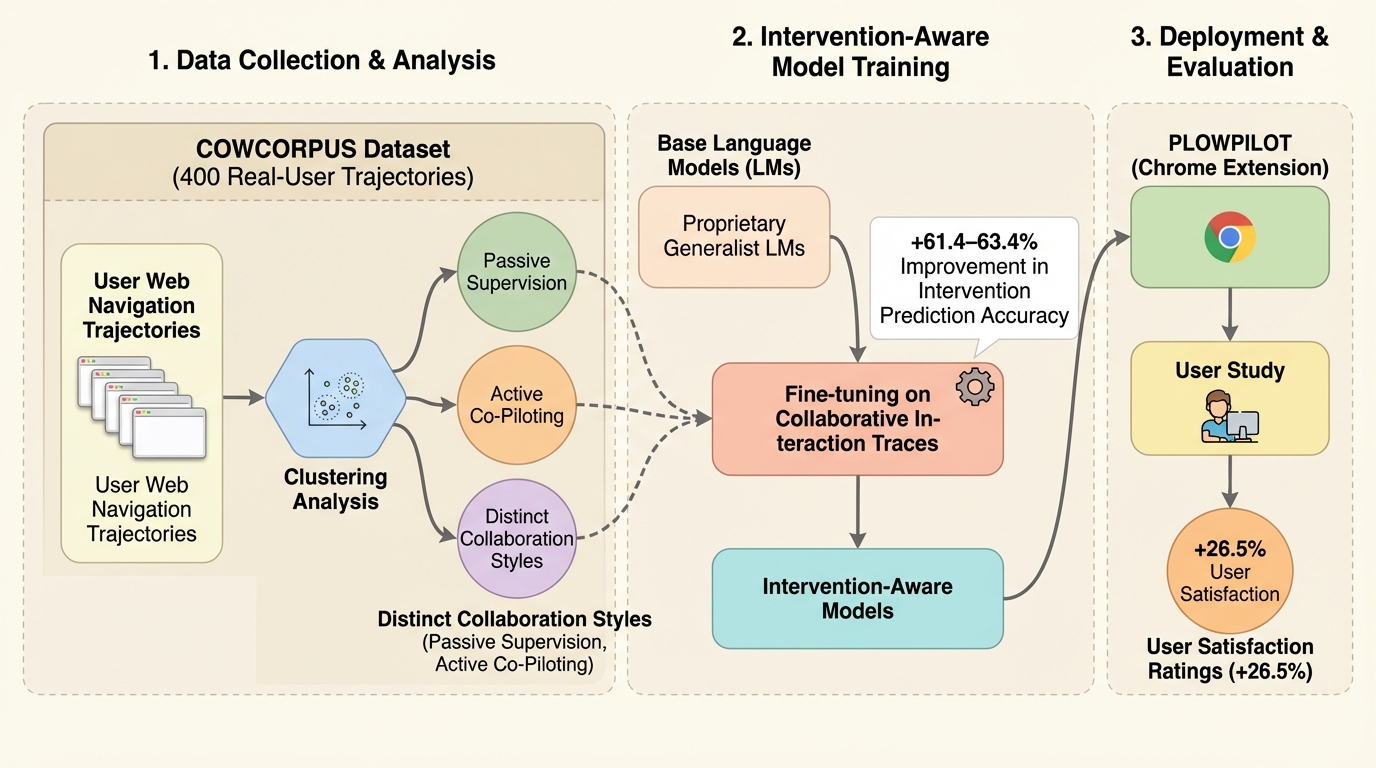
Webエージェントにおける異なる人間のインタラクションをモデル化する
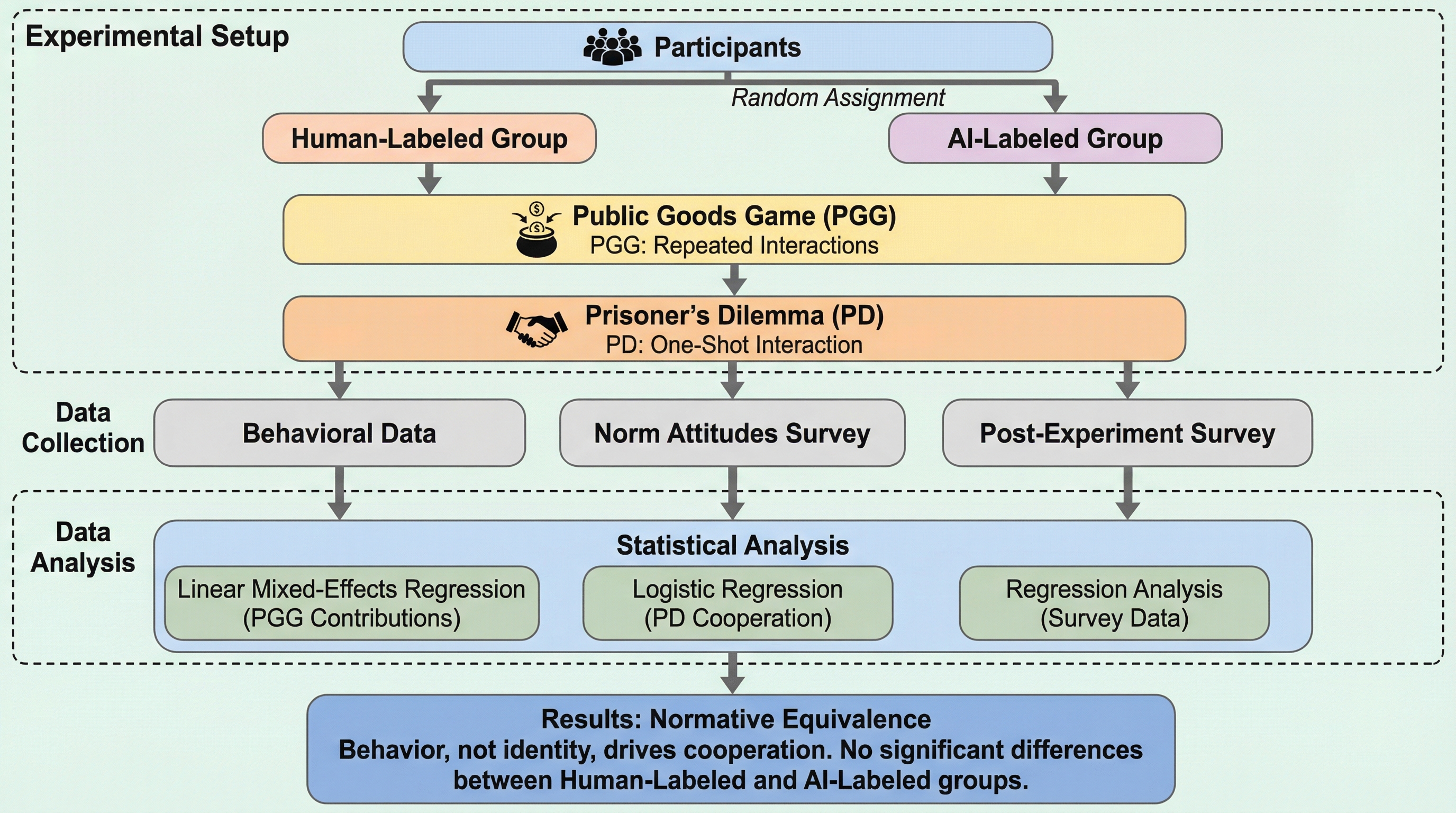
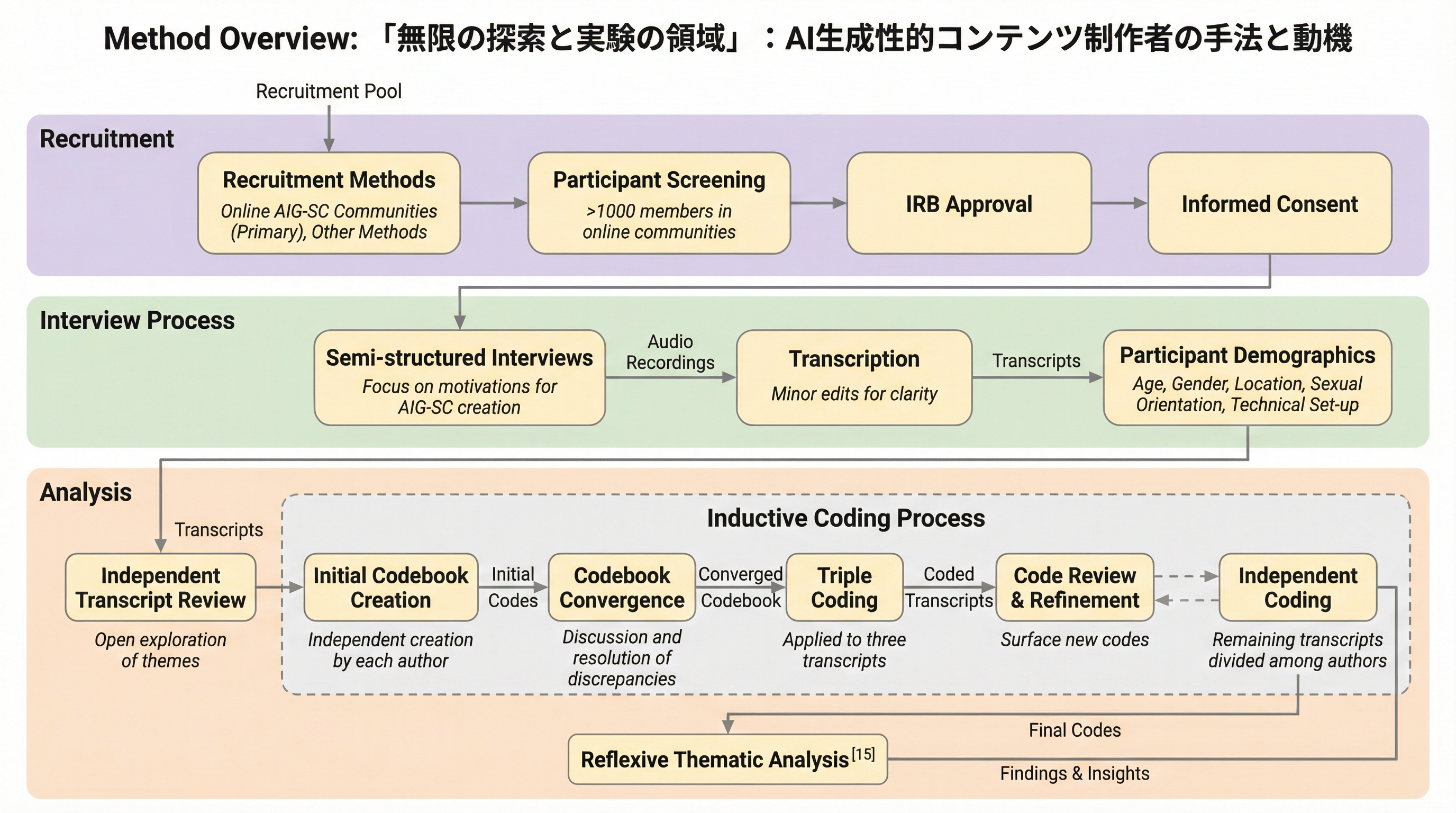
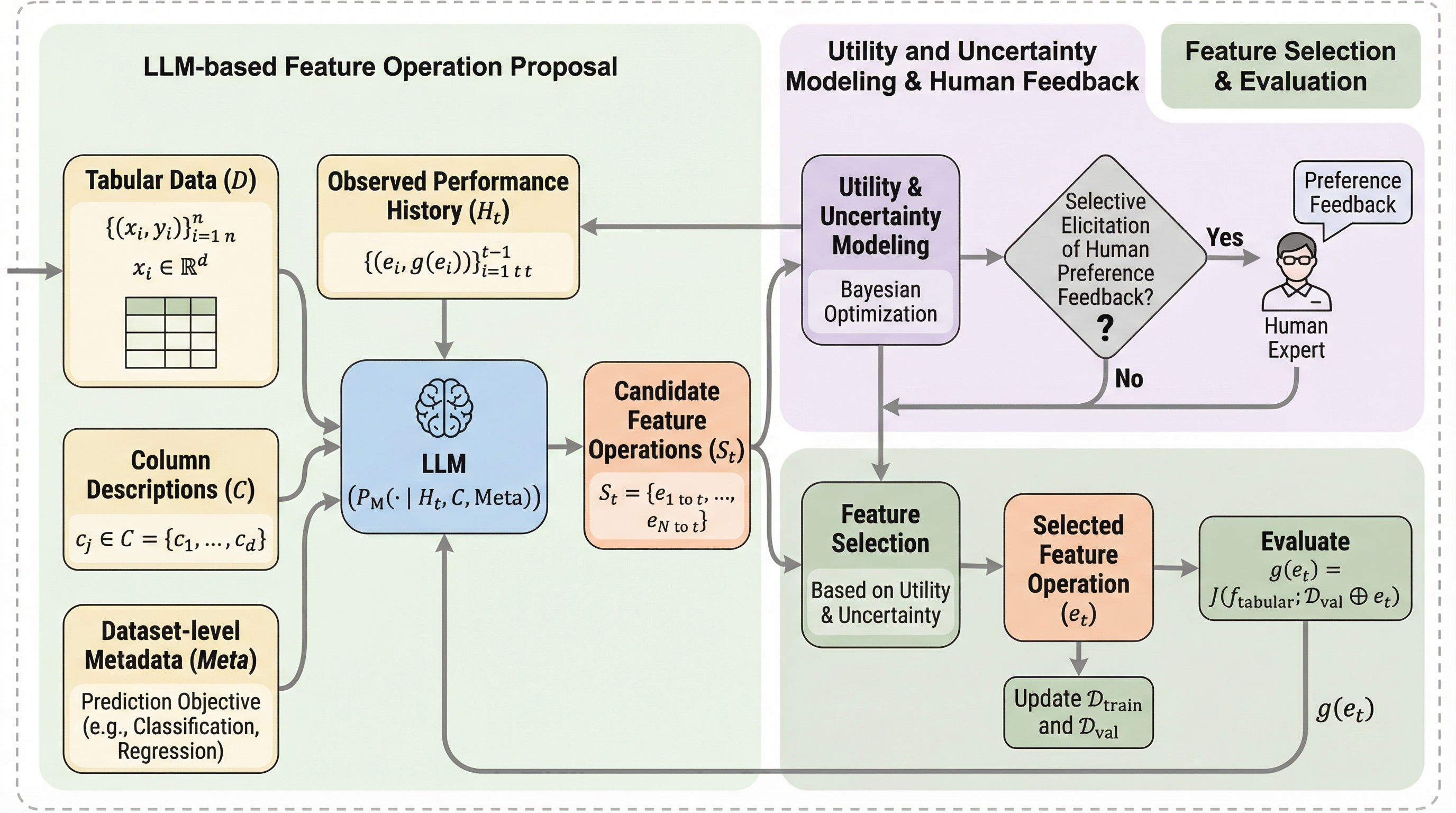
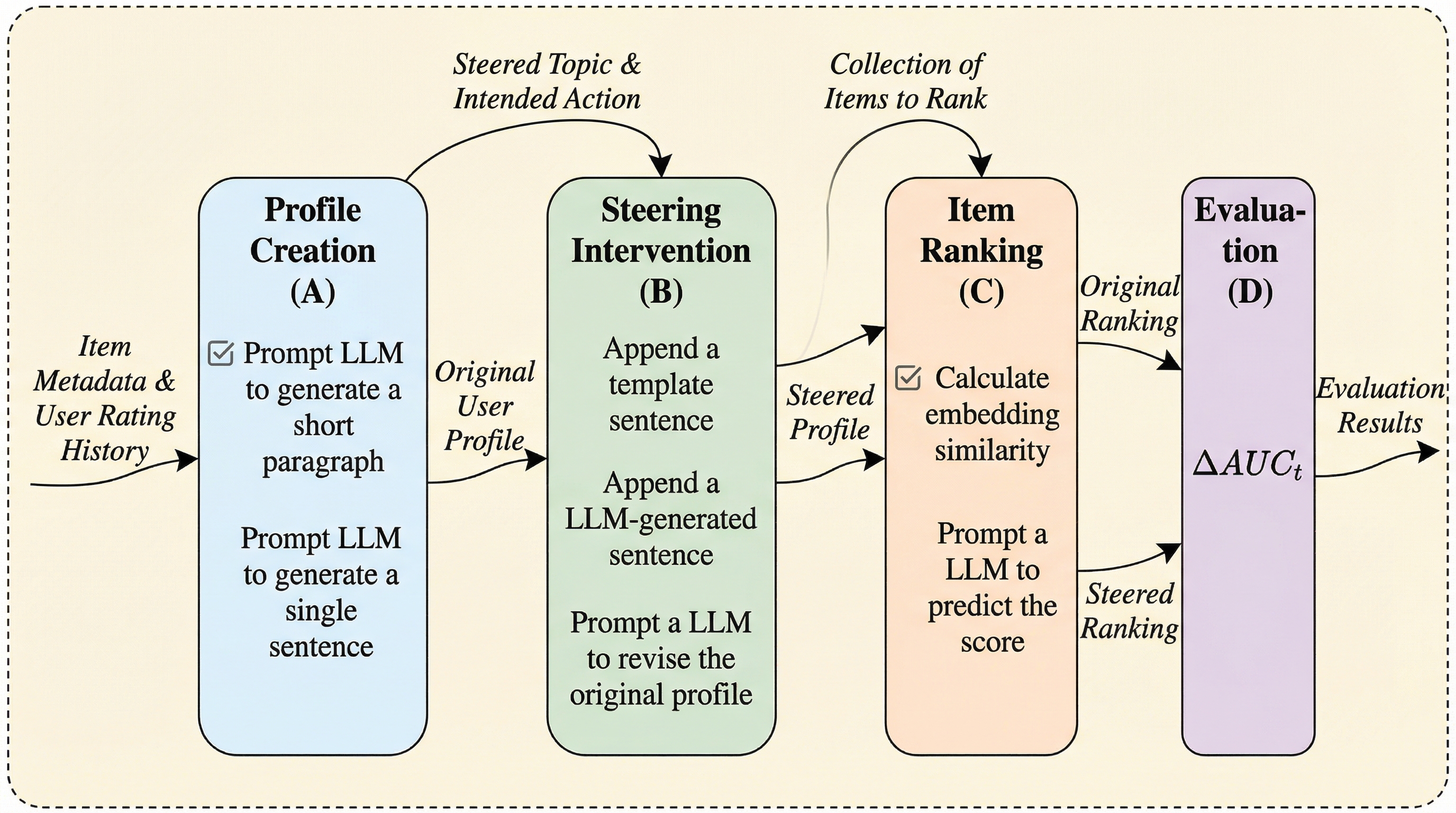
自律的に動くWebエージェントでも実行途中に人が誤り修正や好みの反映のために介入するため、介入が起きるタイミングを見越して振る舞いを調整できるかどうかが協調体験を左右します。 / 400件の実ユーザ軌跡(人とエージェントの行動が4,200件超で交互に記録)を集め、介入の仕方を4つの型に整理したうえで、スクリーンショットとアクセシビリティツリー、履歴、提案行動から次の介入有無を逐次予測するモデルを教師ありで学習します。 / 介入予測はベースの言語モデルより61.4〜63.4%改善し、さらに予測を組み込んだ実運用のWebエージェントはユーザ評価の有用性が26.5%増加しており、介入を構造化して扱うことが適応的な協調につながります。