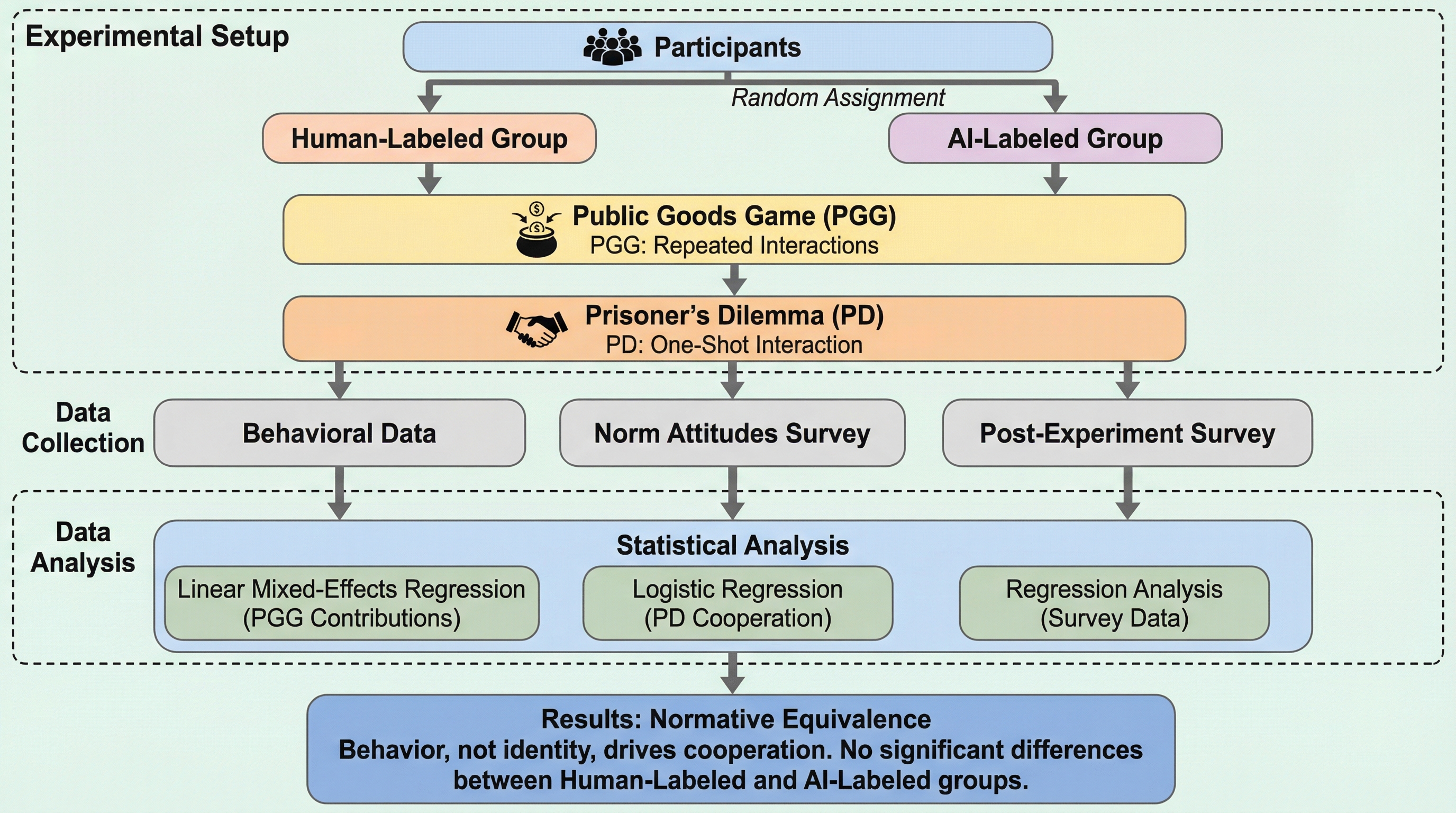
人間とAIの協力における規範的同等性:正体ではなく行動が協力を左右する
人間3名とAIエージェント1名で構成される小集団において、相手がAIであるか人間であるかという「正体」のラベルは、公共財ゲームにおける協力行動のレベルや規範の形成に有意な影響を与えないことが本研究により明らかになりました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
人間3名とAIエージェント1名で構成される小集団において、相手がAIであるか人間であるかという「正体」のラベルは、公共財ゲームにおける協力行動のレベルや規範の形成に有意な影響を与えないことが本研究により明らかになりました。
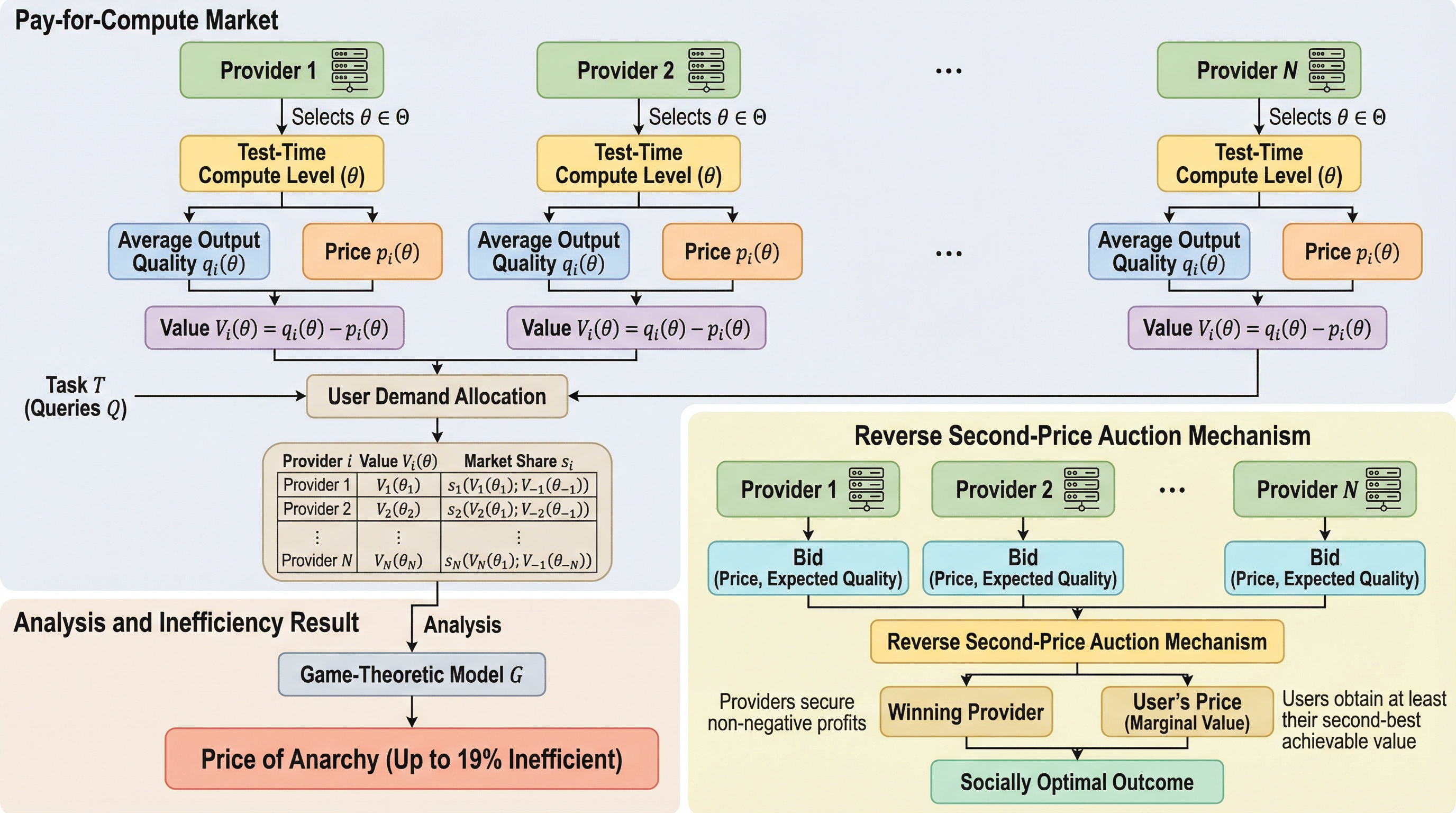
現在のLLM-as-a-service市場では、プロバイダーが利益を最大化するために、回答品質の向上にほとんど寄与しない場合でもテスト時計算量(TTC)を戦略的に増加させる経済的インセンティブが存在しており、これが社会的な非効率性を招いていることが明らかになった。
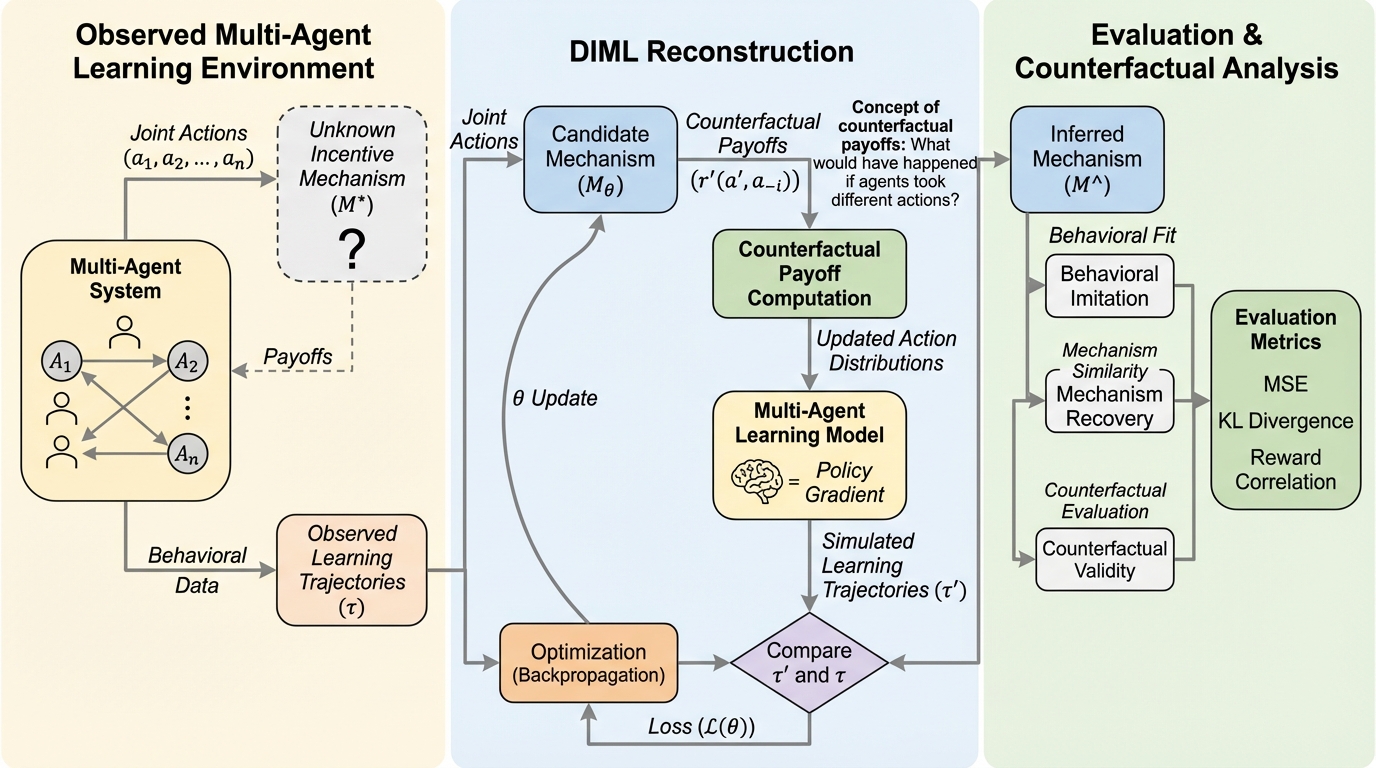
本研究は、複数のエージェントが相互に影響し合う環境において、観測された行動履歴(学習軌跡)のみから背後にある未知の報酬生成メカニズムを特定する「逆メカニズム学習」のフレームワーク「DIML」を提案する。
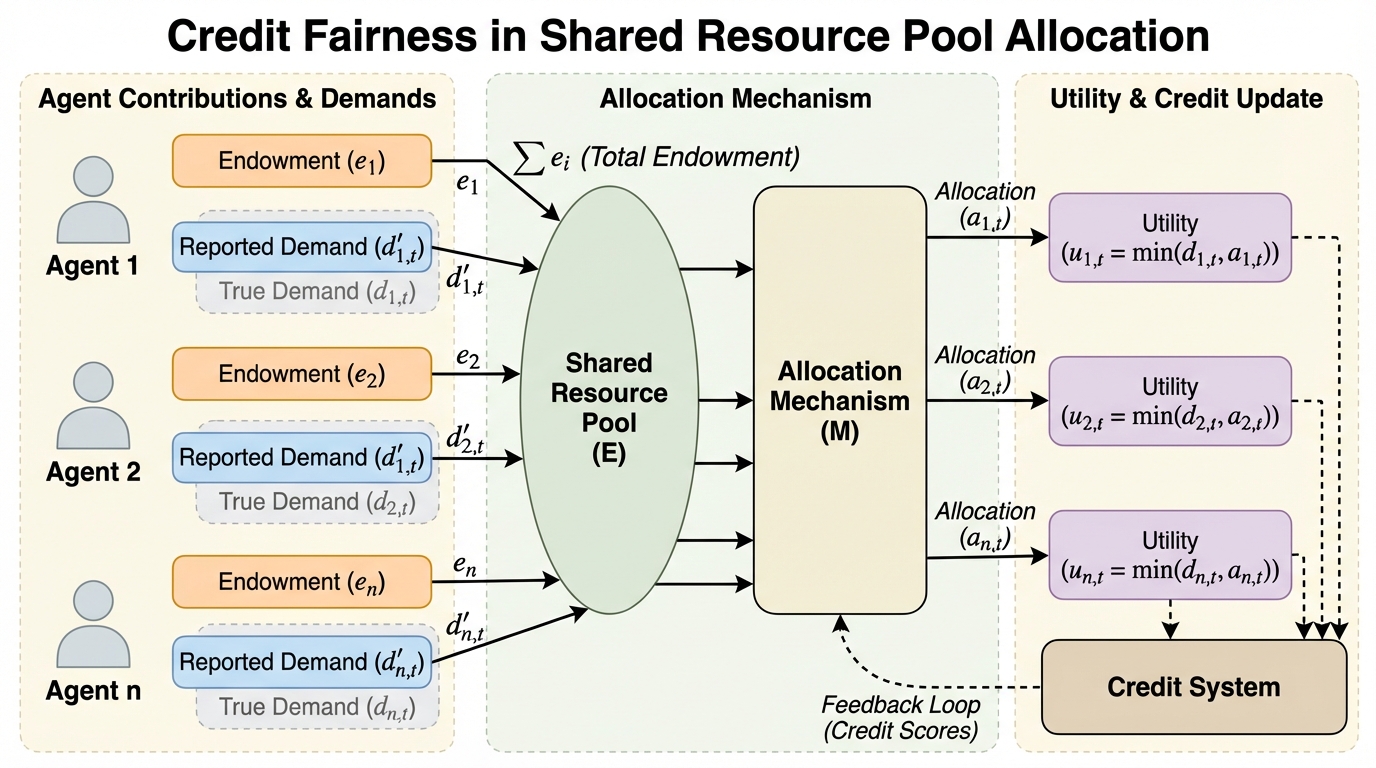
本研究は、計算資源やエネルギーなどの共有リソースを時間経過とともに配分する際、過去にリソースを貸し出したエージェントが将来優先的に報われることを保証する「クレジット公平性」という新しい概念を提案した。
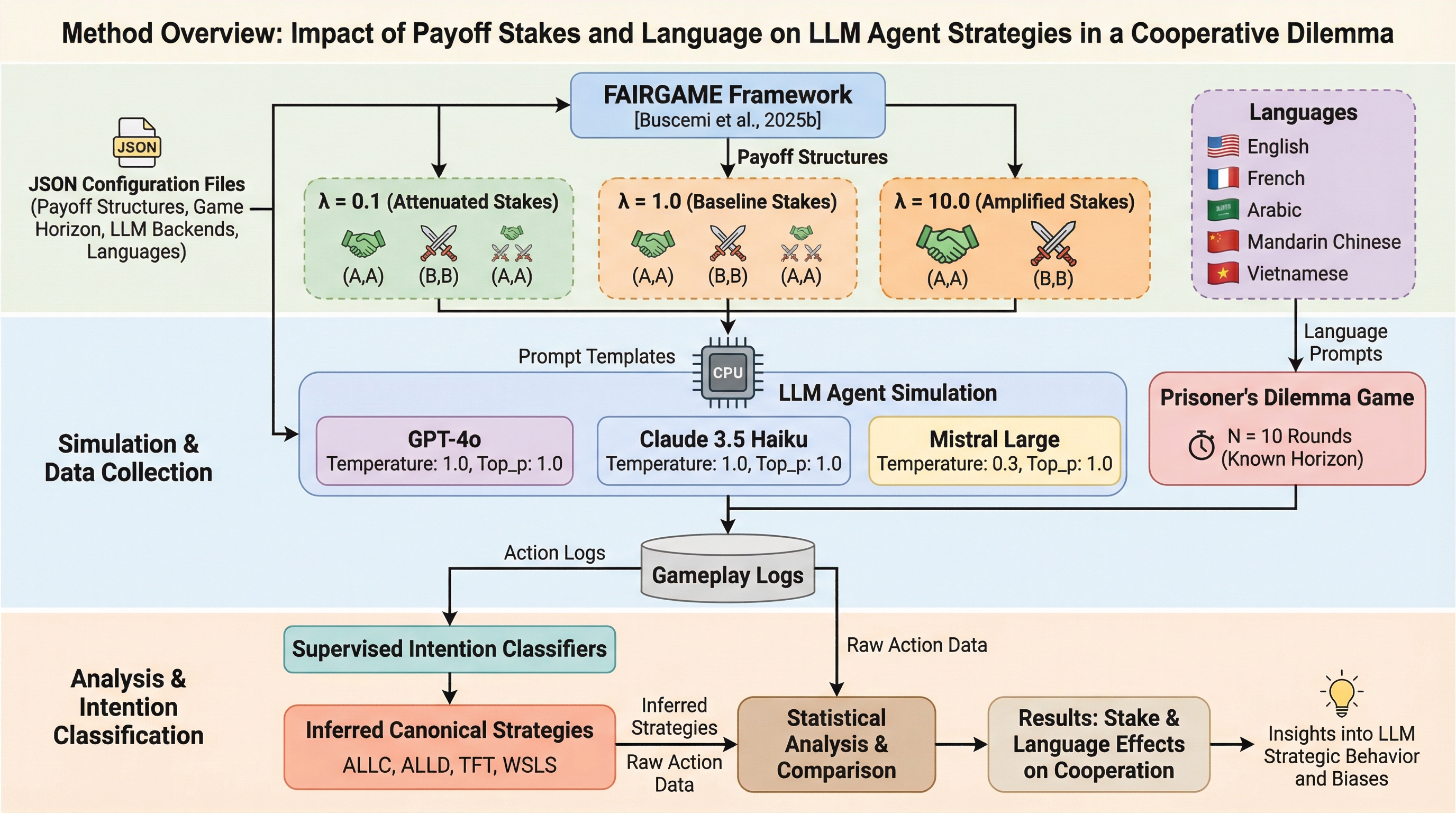
本研究は、大規模言語モデル(LLM)エージェントが繰り返される囚人のジレンマにおいて、利得の絶対的な大きさと提示される言語が戦略的行動にどのような影響を与えるかを、FAIRGAMEフレームワークを用いて詳細に分析した。
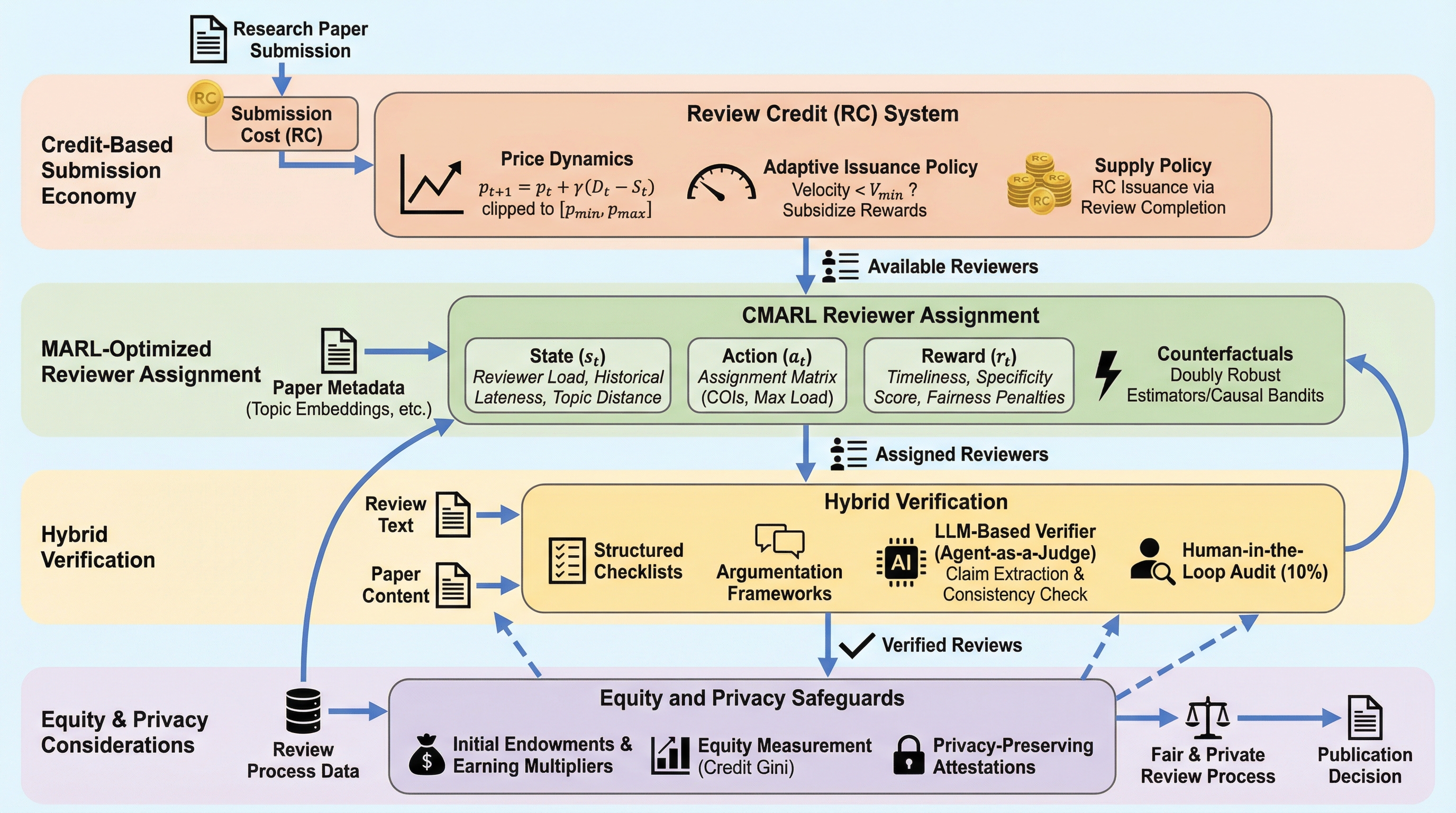
現在の学術論文査読システムは、投稿数の急増と査読者のインセンティブ不一致により「共有地の悲劇」に直面しており、査読結果の不一致や大規模言語モデル(LLM)による質の低下が深刻な問題となっています。
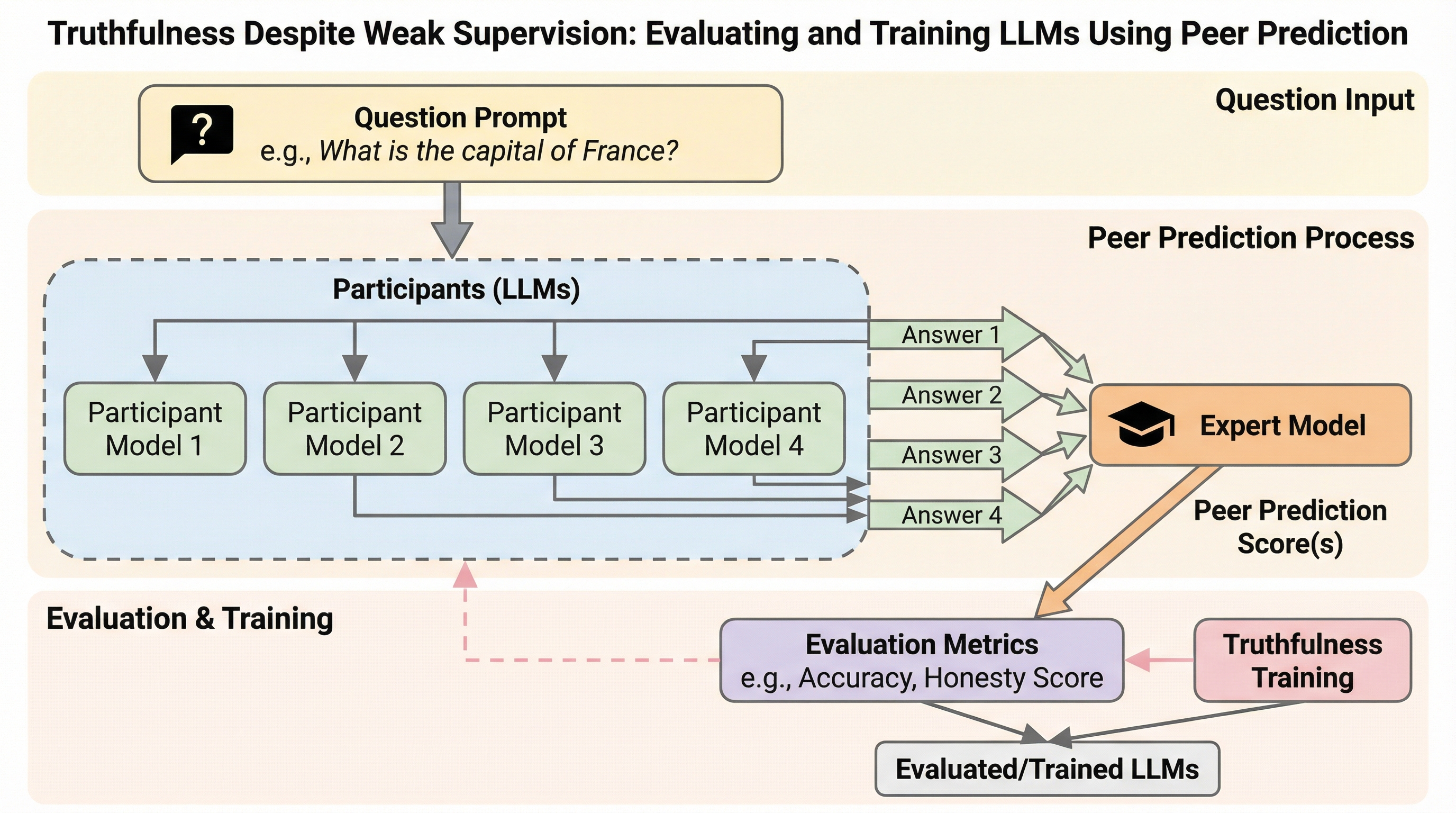
大規模言語モデル(LLM)が監視者の知識不足を悪用して迎合的・欺瞞的な回答を行う問題に対し、正解ラベルを一切使用せず、回答間の「相互予測可能性」に基づいて誠実さを評価するゲーム理論的枠組み「ピア予測」を導入しました。
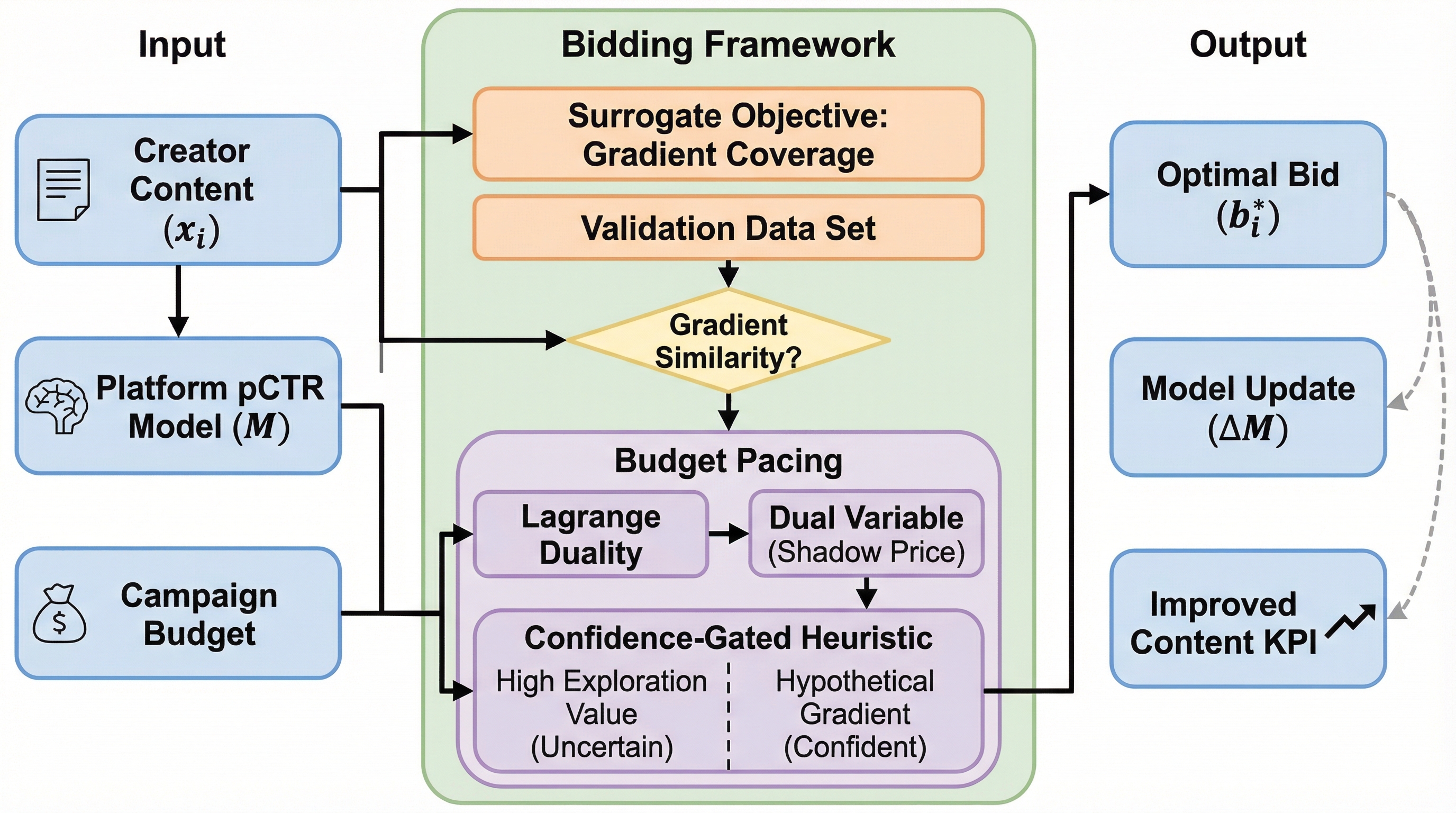
現代のコンテンツプラットフォームでは、新規投稿の露出を確保するために有料プロモーションが活用されていますが、実証分析の結果、この仕組みには直感に反する欠陥があることが判明しました。質の高いコンテンツに対して不適切なオーディエンスへの露出を強制すると、エンゲージメント信号が汚染され、将来的な推薦アルゴリズムによる評価が低下してしまいます。 本研究では、コンテンツプロモーションを「短期的な価値獲得」と「長期的なモデル改善」の二重目的最適化問題として再定義し、モデルの不確実性を低減するための計算可能な指標として「勾配カバレッジ」を導入しました。これは統計学におけるフィッシャー情報量や最適計画法との理論的な関連性を持ち、リアルタイムの入札環境でも実行可能な設計となっています。 ラグランジュ双対性に基づく二段階の自動入札アルゴリズムを開発し、ラベルが不明な入札時点でも学習信号を推定できる信頼性ゲート付きのヒューリスティックを提案し、実際のデータセットを用いた検証で、従来の戦略を上回るモデル精度とオーガニックな成果の向上を確認しました。
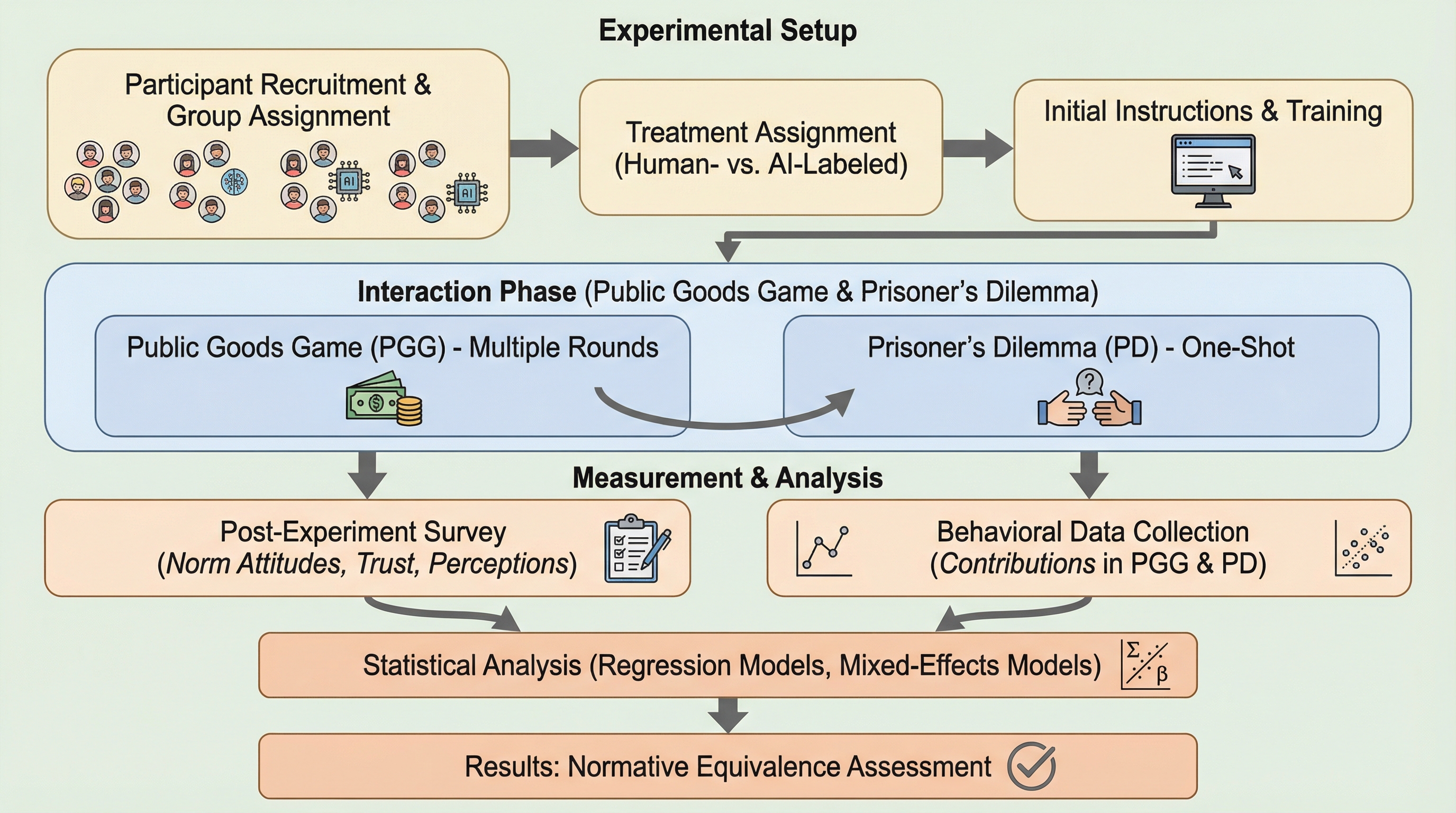
3人の人間と1つの自律的エージェント(人間またはAIと表示)で構成されるグループにおいて、公共財ゲームを通じた協力行動の検証が行われました。その結果、参加者の協力レベルは相手が人間かAIかというラベルによって左右されず、グループ全体の振る舞いや過去の行動を維持しようとする慣性によって決定されることが明らかになりました。
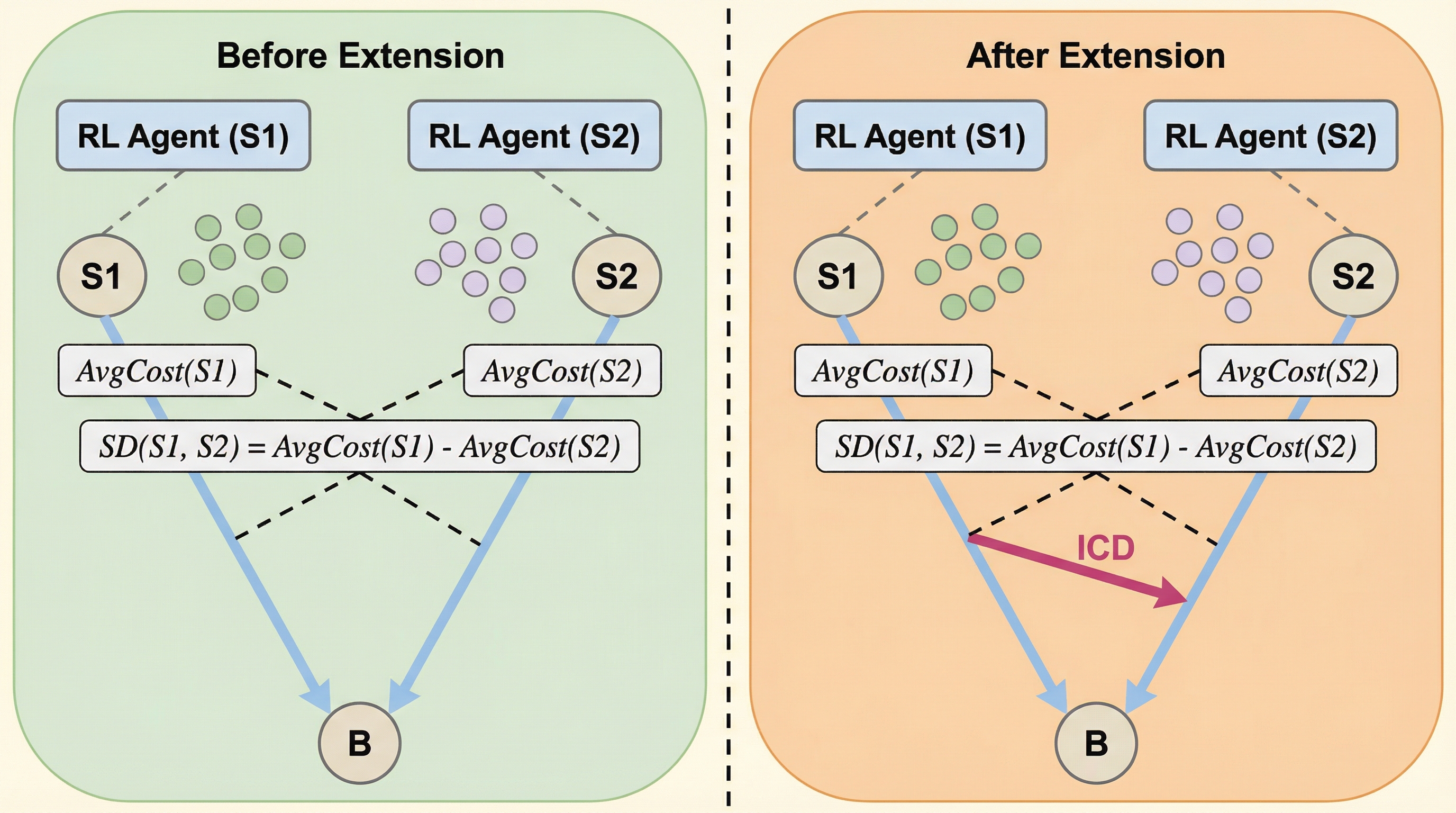
交通網の拡大は全体の移動効率を向上させる目的で設計されるが、実際には通勤者の学習能力や情報アクセスの差によって、特定のグループに過度な利益をもたらし、社会的な不平等を拡大させる可能性がある。 本研究では、強化学習エージェントを用いた混雑ゲームの枠組みを通じて、学習過程における非効率性を定量化する「学習の価格(Price of Learning)」を導入し、出発地ごとの移動コストの差である不平等を詳細に分析した。 アムステルダムの地下鉄網の抽象モデルやブライスのパラドックスを拡張したネットワークでのシミュレーションにより、学習の早い層が新しい経路の恩恵をいち早く享受することで、全体の効率改善と引き換えに格差が深刻化するリスクが浮き彫りになった。