LLM生成応答への広告挿入
大規模言語モデル(LLM)の持続可能な収益化に向け、広告挿入を応答生成から分離し、広告主が特定のクエリではなく「ジャンル」という抽象的なカテゴリに対して事前に入札を行う新しい広告枠組みを提案する。
TL;DR(結論)
大規模言語モデル(LLM)の持続可能な収益化に向け、広告挿入を応答生成から分離し、広告主が特定のクエリではなく「ジャンル」という抽象的なカテゴリに対して事前に入札を行う新しい広告枠組みを提案する。 この手法は、ユーザーのプライバシーを保護しながらリアルタイム生成の遅延を回避する高い計算効率を実現し、VCGオークションの適用によって社会的余剰の最大化と広告主の誠実な入札を促す理論的保証を両立させている。 実験ではLLMを評価者として用いる新しい指標を導入し、人間による評価と高い相関(スピアマンの順位相関係数約0.66)を示すことを確認しており、広告の文脈的整合性と透明性を高い水準で維持できることが実証された。
なぜこの問題か
現在、ChatGPTをはじめとする大規模言語モデル(LLM)は週間に7億人以上の活動的なユーザーを抱えるまでに成長したが、有料購読者はそのうち約1000万人に留まっており、膨大なトレーニングおよび運用コストの回収が大きな課題となっている。米国における生成AIへの支出は2028年までに1080億ドルに達すると予測されており、従来の検索エンジンが成功させたような広告モデルの導入が、LLMサービスの持続可能性を確保するために不可欠な状況にある。しかし、従来の検索広告は静的なキーワードに依存しているため、会話の流れの中で刻々と変化するユーザーの意図や、特定の情報やサービスを求める一時的な文脈を捉えることが困難であるという構造的な問題が存在する。 例えば、家族でのニューヨーク旅行についてLLMと対話している場合、最初は観光地の議論から始まり、宿泊施設、交通手段、予算の検討へと話題が移り変わっていくが、これら全ての段階で適切な広告を挿入するには高度な文脈理解が必要となる。…
核心:何を提案したのか
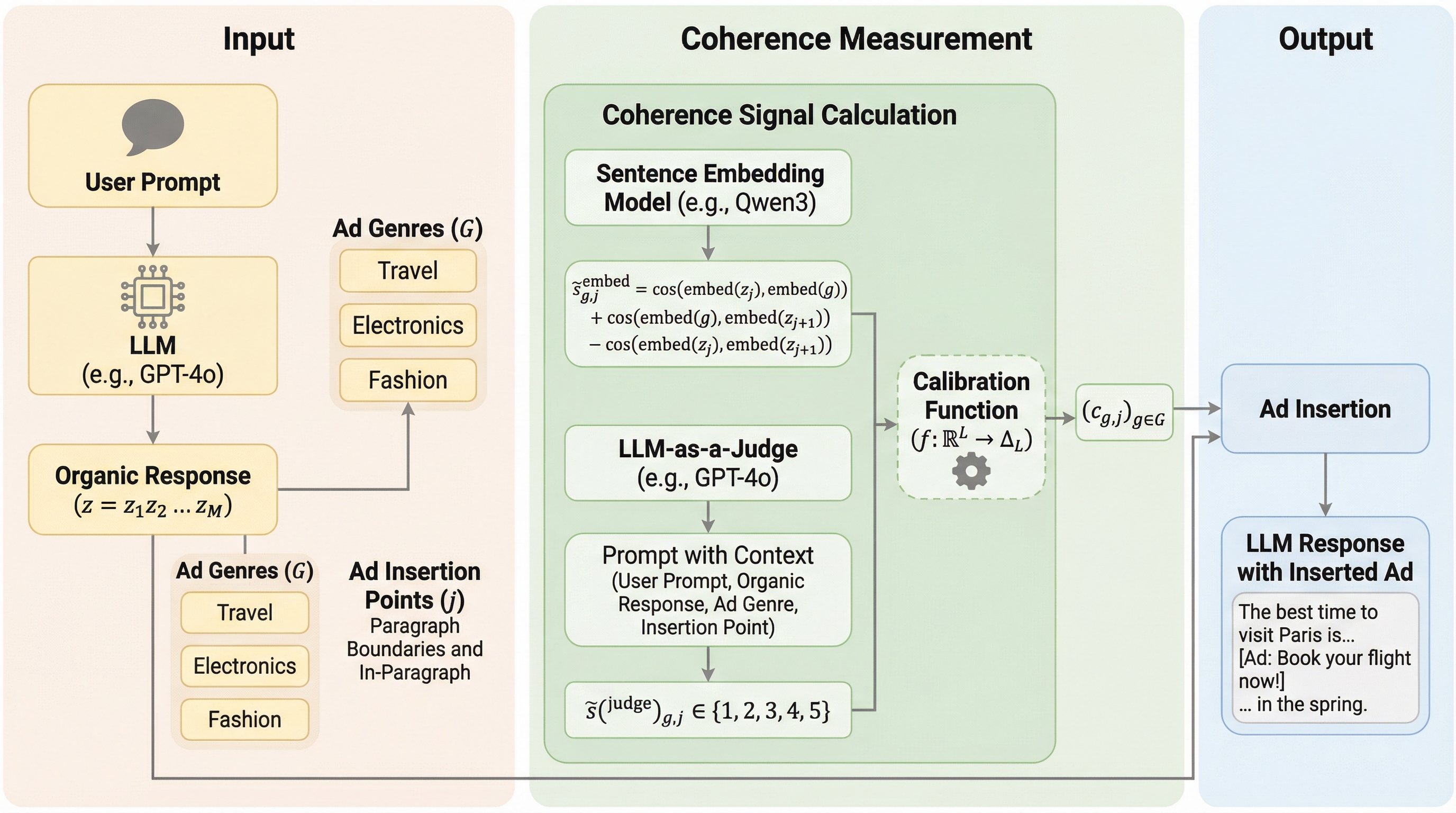
本論文では、上述の複雑な制約を解消するために、二つの「デカップリング(分離)」戦略を軸とした実用的なフレームワークを提案している。第一の戦略は、広告の挿入プロセスを応答の生成プロセスから完全に分離することである。これにより、LLMが生成した本来の回答を損なうことなく、その隙間に定義済みの広告を配置することが可能になる。この分離により、広告内容がLLMによって勝手に改変されたり、ハルシネーション(事実誤認)によって誤った宣伝文句が生成されたりするリスクを根本から排除し、規制当局が求める広告の明示的な開示も容易にする。 第二の戦略は、広告主による入札を個別のユーザークエリから切り離し、代わりに「ジャンル」と呼ばれる高レベルのセマンティック・クラスター(意味的な塊)を代理指標として利用することである。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related