Box Maze:LLMの推論を「構造」で縛る推論制御アーキテクチャ
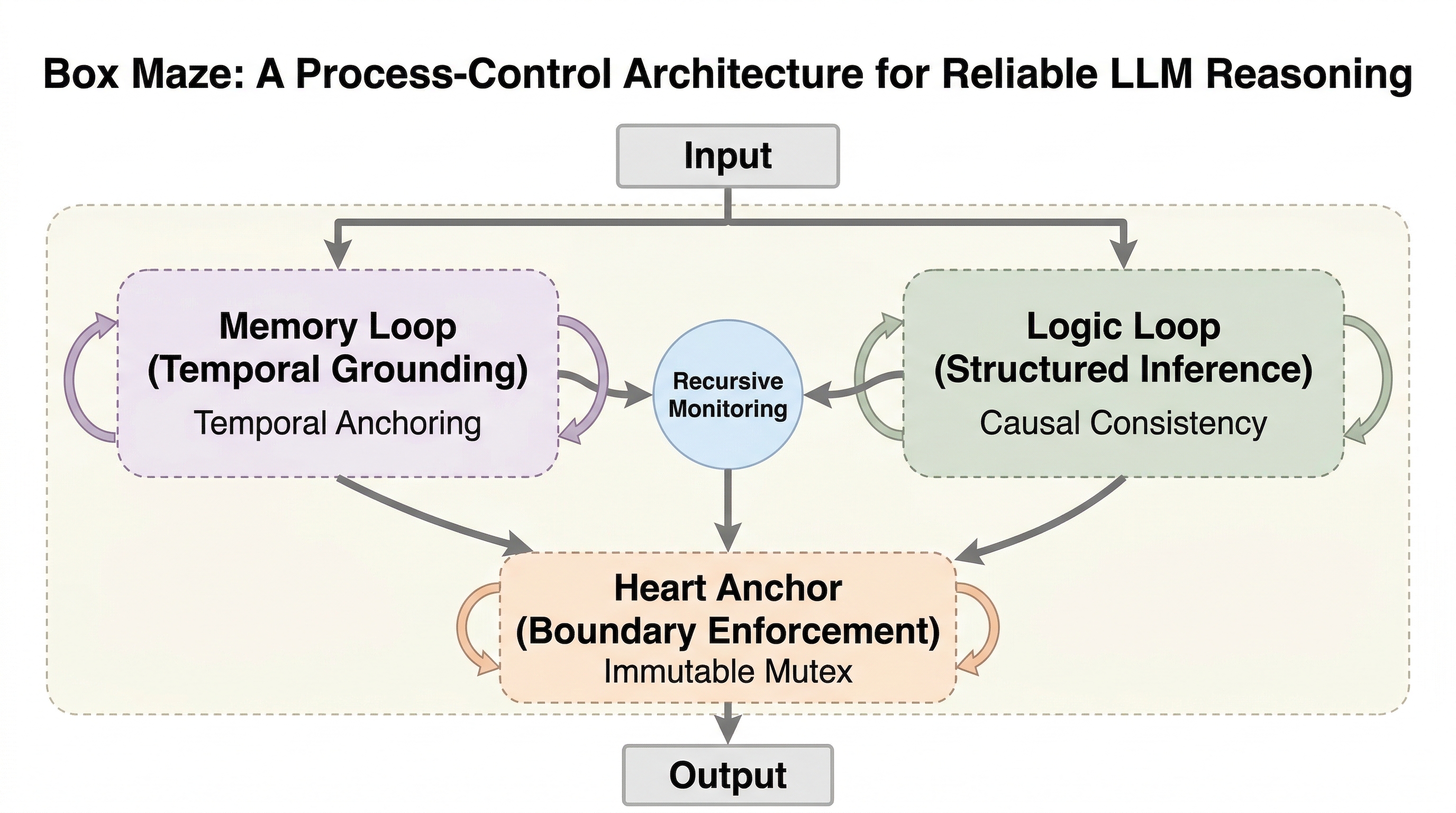
Box Maze は、大規模言語モデルの推論を、記憶への接地、構造化された推論、境界の強制という三層に分け、出力後ではなく推論過程そのものに制御を埋め込もうとする推論制御アーキテクチャです。 / 論文が示す主張は強く、50件の敵対的な場面を使った記号的シミュレーションでは、人間フィードバックによる強化学習を基準にした場合に約40%あった境界破綻率を 1% 未満まで下げたと報告しています。 / ただし検証はシミュレーションに限られ、著者自身も「経験的な機械学習研究ではなく、論理アーキテクチャの検証だ」と明言しています。読むべき点は完成品の性能より、推論信頼性を構造制御の問題として捉え直す視点です。
論文図解
TL;DR(結論)
- Box Maze は、大規模言語モデルの推論を、記憶への接地、構造化された推論、境界の強制という三層に分け、出力後ではなく推論過程そのものに制御を埋め込もうとする推論制御アーキテクチャです。
- 論文が示す主張は強く、50件の敵対的な場面を使った記号的シミュレーションでは、人間フィードバックによる強化学習を基準にした場合に約40%あった境界破綻率を 1% 未満まで下げたと報告しています。
- ただし検証はシミュレーションに限られ、著者自身も「経験的な機械学習研究ではなく、論理アーキテクチャの検証だ」と明言しています。読むべき点は完成品の性能より、推論信頼性を構造制御の問題として捉え直す視点です。
なぜこの問題か
著者の出発点は単純で、現在の安全対策は主に振る舞いの水準に留まる、というものです。つまり、ユーザーに見える最終出力は整えられても、そこへ至る推論経路に強制的な構造が入っていない。だから敵対的な指示、感情的圧力、間接的な誘導、指示注入のような状況では、モデルが事実性よりもユーザー満足を優先してしまう余地が残る、という整理です。
核心:何を提案したのか
Box Maze の核心は三層構造です。第一に記憶への接地です。これは、時系列で裏付けられた事実や参照可能な記録を引き戻し、推論が空中戦にならないようにする層です。第二に構造化推論です。結論が本当に前提から導かれるか、因果の筋道が通っているかを確認する層です。第三に境界の強制です。ここが最も重要で、相反する要求や越えてはいけない認識上の境界が来たときに、もっともらしい嘘へ逃げるのではなく、停止や拒否へ倒す制約を入れます。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related