言語モデルにおける連続トークン表現のための分離可能なアーキテクチャ
従来の小規模言語モデル(SLM)において、パラメータ予算の多くを占有していた離散的な埋め込み行列(ルックアップテーブル)を、連続的な関数近似を行う「分離可能なニューラルアーキテクチャ(SNA)」を用いた生成器に置き換える新手法「Leviathan」が提案されました。
TL;DR(結論)
従来の小規模言語モデル(SLM)において、パラメータ予算の多くを占有していた離散的な埋め込み行列(ルックアップテーブル)を、連続的な関数近似を行う「分離可能なニューラルアーキテクチャ(SNA)」を用いた生成器に置き換える新手法「Leviathan」が提案されました。 この手法により、語彙サイズとモデル容量の線形な依存関係が解消され、節約されたパラメータをモデルの深さに再投資することで、実際のパラメータ数の1.47倍から2.11倍に相当する有効なモデル容量(Effective Size)を達成し、標準的なLLaMA型アーキテクチャを一貫して上回る性能を示しました。 特に大規模な語彙を使用する環境や、学習が進んだ「過学習」の段階においてその優位性は顕著であり、計算上のオーバーヘッドはあるものの、サンプル効率の劇的な向上によって、同じ検証損失を達成するために必要な総計算コストを大幅に削減できることが実証されました。
なぜこの問題か
現代のAIの基盤であるTransformerアーキテクチャのスケーリング則においては、通常、パラメータはモデルのどこに追加しても同等の効果を持つと仮定されています。しかし、100億パラメータ未満の小規模言語モデル(SLM)の領域では、この前提が崩れることが指摘されています。具体的には、単語やトークンをベクトルに変換するための「埋め込み行列」が、モデル全体のパラメータ予算を不当に圧迫しているという「語彙税(Vocabulary Tax)」の問題があります。例えば、5万語を超える語彙を持ち、隠れ層の次元が1024のモデルでは、埋め込み行列だけで5000万パラメータを消費してしまい、1億パラメータ規模のモデルでは容量の半分が単なる辞書の保持に費やされてしまいます。 この問題に対し、従来は入力の埋め込み層と出力のソフトマックス層で重みを共有する「重み共有(Weight Tying)」が一般的に行われてきました。しかし、これは入力の認識空間と出力の予測空間が同じ幾何学的構造を持つという、機能的な非対称性を無視した制約を課すことになります。…
核心:何を提案したのか
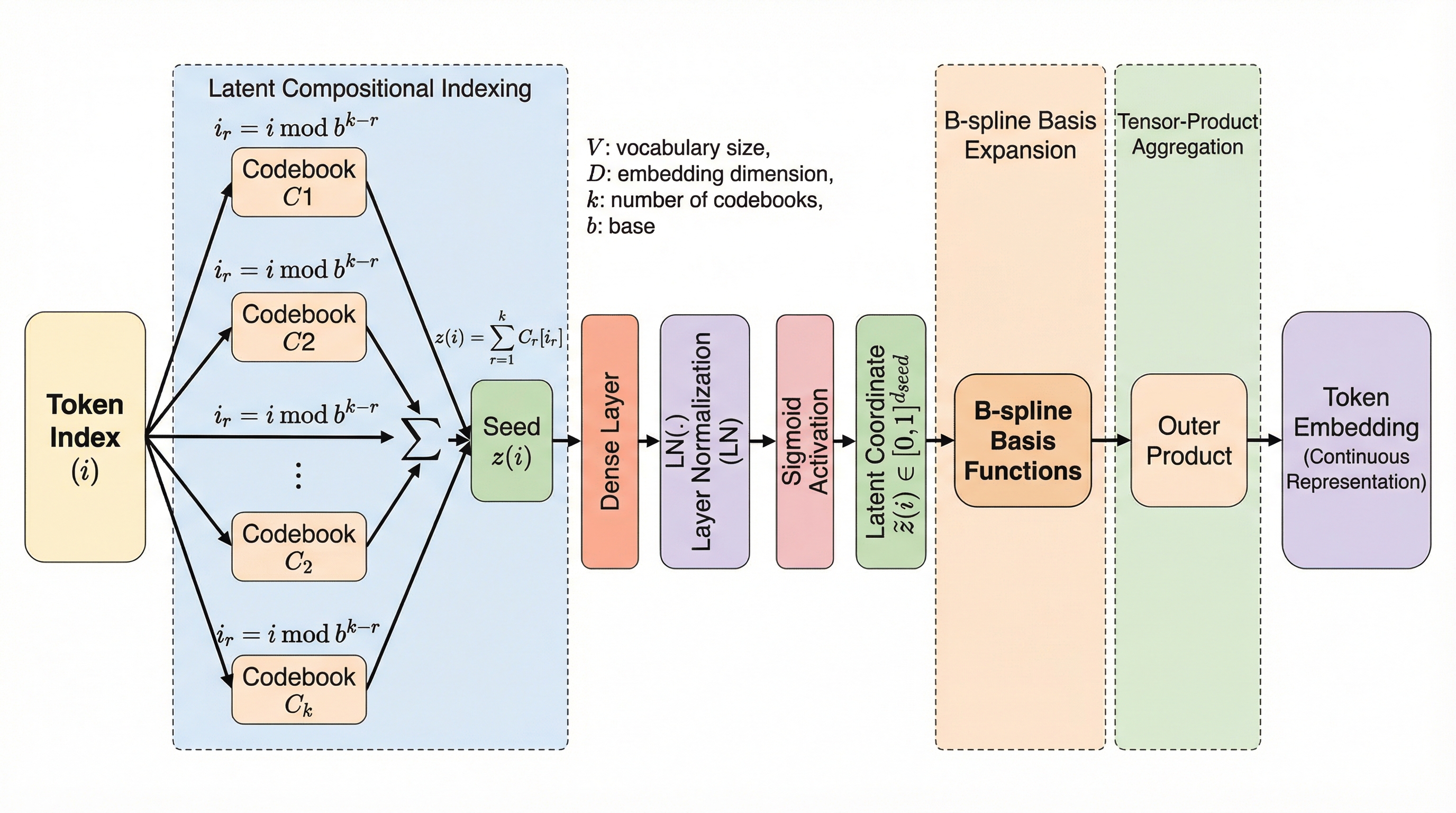
本研究が提案する「Leviathan」は、従来の離散的なルックアップテーブルを、連続的なトークン生成器(Continuous Token Generator)に完全に置き換えた新しいアーキテクチャです。この生成器は、分離可能なニューラルアーキテクチャ(SNA)を採用しており、語彙空間を滑らかな連続的な表面としてパラメータ化します。最大の特徴は、語彙サイズ $V$ とモデル容量の間の線形な依存関係を打破し、パラメータのスケーリングを $O(\sqrt[3]{V} \cdot D)$ という極めて低いオーダーにまで圧縮した点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related