質問しながら推論する:受動的な解決者から能動的な探求者へのLLMの変革
OpenAIのo1やDeepSeek-R1に代表される推論型モデルが、情報不足の状況でも強引に推論を進めてしまう「盲目的な自己思考」という課題に対し、本研究は能動的に質問を行うPIRフレームワークを提案しました。
TL;DR(結論)
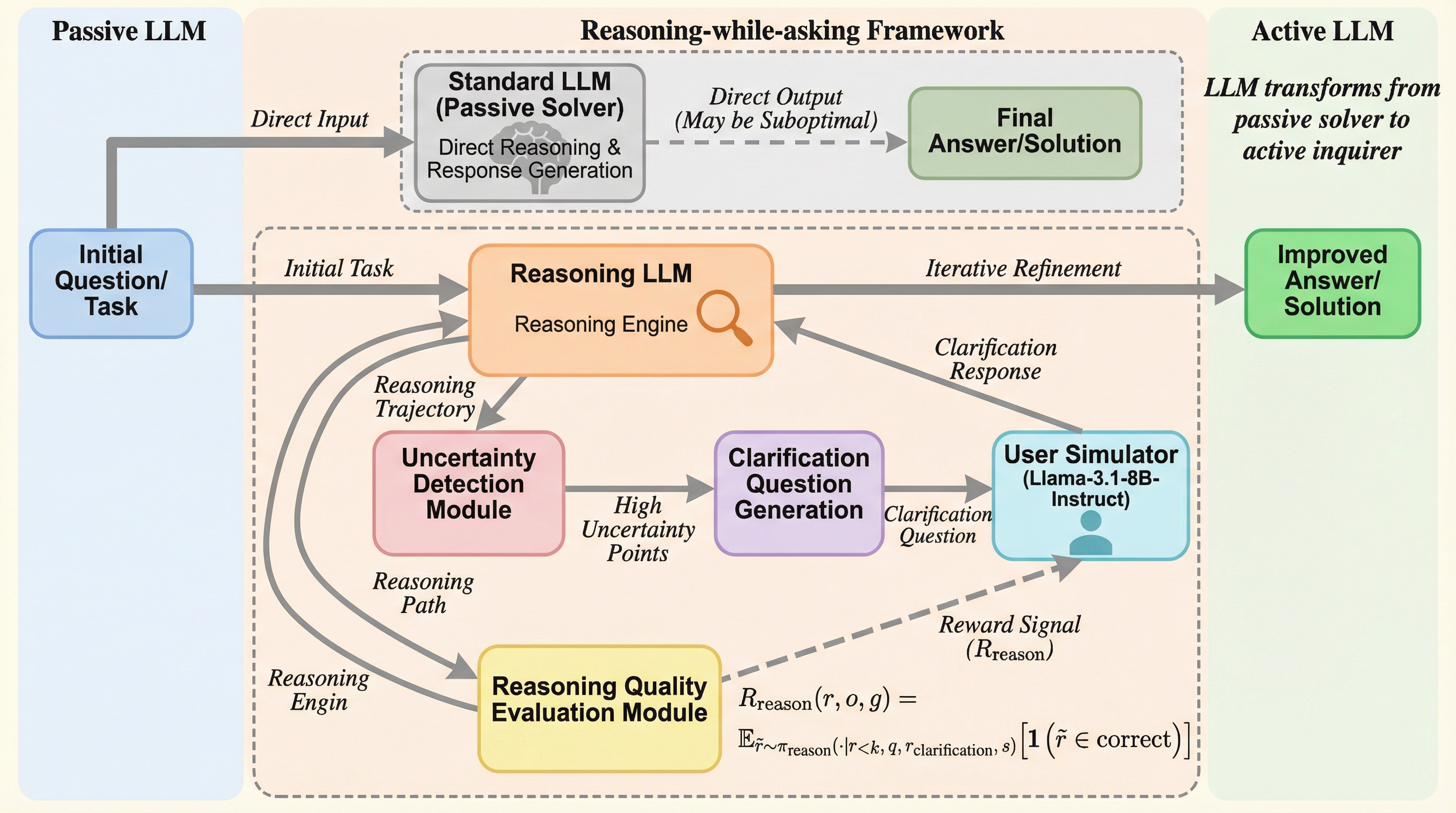
OpenAIのo1やDeepSeek-R1に代表される推論型モデルが、情報不足の状況でも強引に推論を進めてしまう「盲目的な自己思考」という課題に対し、本研究は能動的に質問を行うPIRフレームワークを提案しました。 PIRは、モデル内部の不確実性を検知して推論の途中で自律的にユーザーへ確認を行う仕組みであり、不確実性に基づく教師あり微調整と、ユーザーシミュレータを用いた強化学習(US-GRPO)の二段階で対話能力と意図の整合性を最適化します。 実験の結果、数学やコード生成において精度が最大32.70%向上し、不要な推論計算を約2000トークン削減しながら対話回数を半分に抑えるなど、正確性と効率性の両面で従来の手法を大きく上回る性能を実証しました。
なぜこの問題か
OpenAIのo1やDeepSeek-R1といった最新の推論指向の大規模言語モデルは、思考の連鎖(Chain-of-Thought)を用いることで、複雑な数学的問題やプログラミングタスクにおいて驚異的な成果を上げてきました。しかし、これらのモデルには「盲目的な自己思考(blind self-thinking)」と呼ばれる、実用上の重大な欠陥が依然として存在しています。これは、ユーザーからの指示が曖昧であったり、重要な前提条件が欠落していたりする場合でも、モデルがその不備を認識せずに、内部で長大な推論を強行してしまう現象を指します。現実の利用シーンでは、ユーザーが最初から完璧で詳細な指示を与えることは稀であり、情報が不完全なまま推論を開始すると、モデルは根拠のない仮定に基づいた過剰思考に陥りやすくなります。 このような状況下では、モデルがハルシネーション(幻覚)を引き起こしたり、最終的にユーザーの意図とは全く異なる、誤った結論を出力したりするリスクが極めて高くなります。その結果、ユーザーは出力された後に何度も修正指示を出さなければならず、対話の効率が著しく低下し、膨大な計算リソースが無駄に消費されることになります。…
核心:何を提案したのか
本研究は、大規模言語モデルを受動的な問題解決者から、能動的な探求者へと変革する「Proactive Interactive Reasoning(PIR)」という新しい推論パラダイムを提案しました。PIRの核心的なアイデアは、モデルが推論の過程で自らの不確実性をリアルタイムで検知し、必要に応じてユーザーに具体的な質問を投げかけ、得られた回答を即座に推論の軌道修正に反映させる仕組みにあります。このフレームワークは、単なるプロンプトエンジニアリングではなく、モデルの学習プロセスそのものを変革する二つの主要な段階で構成されています。 第一段階は「対話能力の活性化」であり、モデルが「いつ」「どのように」質問すべきかを学習するための、不確実性を考慮した教師あり微調整(SFT)を実施します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related