モデルリポジトリに眠る「隠れた名作」の発掘
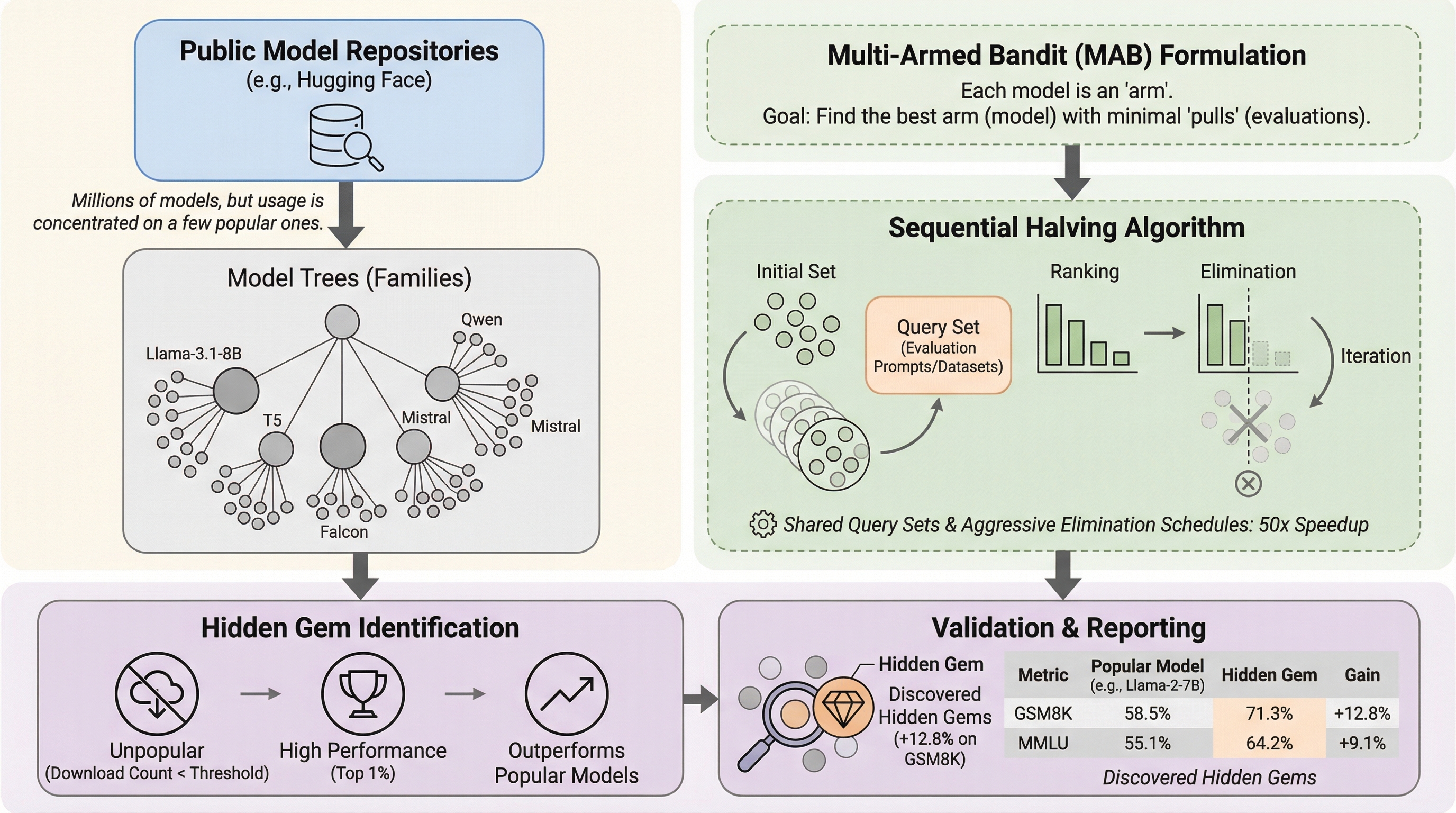
Hugging Face等の公開リポジトリには数百万のモデルがホストされているが、利用実態は極めて一部の公式モデルに集中しており、優れた性能を持ちながらも月間ダウンロード数が極少数の「隠れた名作(Hidden Gems)」が膨大に埋もれている実態を、2,000以上のモデル評価を通じて明らかにした。 Llama-3.
TL;DR(結論)
Hugging Face等の公開リポジトリには数百万のモデルがホストされているが、利用実態は極めて一部の公式モデルに集中しており、優れた性能を持ちながらも月間ダウンロード数が極少数の「隠れた名作(Hidden Gems)」が膨大に埋もれている実態を、2,000以上のモデル評価を通じて明らかにした。 Llama-3.1-8Bにおいて数学性能を83.2%から96.0%へ劇的に向上させる無名モデルや、Mistral-7Bにおいて数学性能を40%以上改善するモデルを発見し、ダウンロード数などの人気指標が必ずしもモデルの真の性能や価値を反映していないことを客観的な数値データに基づき証明した。 膨大な候補からこれらを効率的に見つけ出すため、マルチアームバンディット理論に基づく加速型Sequential Halvingアルゴリズムを提案し、モデルあたりわずか50クエリという従来の網羅的評価の50倍以上の高速さで、トップクラスのモデルを確実に特定する実用的な探索手法を確立した。
なぜこの問題か
現在、Hugging Faceに代表される公開モデルリポジトリは、200万を超えるチェックポイントをホストするまでに拡大し、AI開発の民主化に大きく貢献している。しかし、この膨大な選択肢の中で、ユーザーが自身のタスクに最適なモデルを選択することは極めて困難なボトルネックとなっている。統計データによれば、リポジトリ内のモデル利用は極端に中央集権化しており、全ダウンロードの95%がわずか0.0015%の特定のモデルに集中している。大多数のユーザーは、公式の基盤モデルやその公式な指示調整(Instruction fine-tuning)版をデフォルトとして選択しており、それ以外の90%以上のモデルは月間ダウンロード数が15回以下という休眠状態にある。 この現状に対して、本研究では二つの仮説を立てている。一つは、市場が効率的に機能しており、優れたモデルが自然に選別されているという「効率的発見仮説」である。もう一つは、情報の非対称性により、優れたモデルがロングテールの中に埋もれてしまっているという「情報非対称性仮説」である。…
核心:何を提案したのか
本研究の核心は、人気はないが既存の主要モデルを圧倒する性能を持つモデルを「隠れた名作(Hidden Gems)」と定義し、これらを計算資源を抑えつつ効率的に特定する新しい探索アルゴリズムを提案したことにある。まず、隠れた名作の定義を厳密に定めた。それは、ダウンロード数が上位1%に入らない「無名性」、性能が全モデルの中で上位1%に入る「卓越性」、そして最も人気のあるモデルの性能を明確に上回る「優越性」の三条件をすべて満たすモデルである。この定義に基づき、2,000以上のモデルを精査することで、実際にこうしたモデルが多数存在することを実証した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related