エージェントのための推論報酬モデル「Agent-RRM」の探求
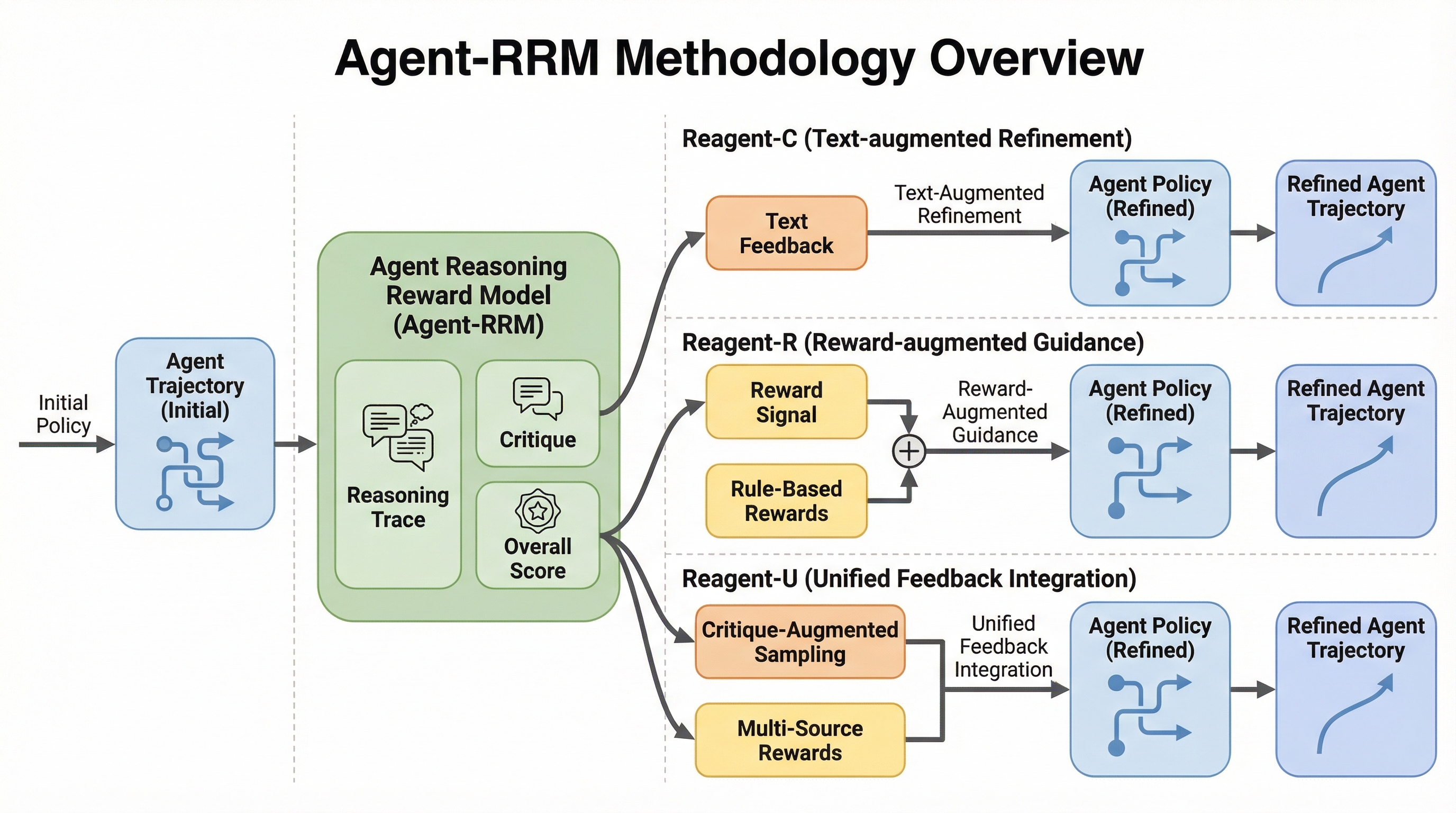
従来のエージェント学習が最終結果の正誤のみに依存する稀薄な報酬に頼っていたのに対し、本研究は推論の過程を詳細に評価する「Agent-RRM」を提案しました。 このモデルは、推論の論理性を分析するトレース、具体的な欠陥を指摘する批判、全体的な品質スコアという3つの構造化されたフィードバックを生成し、エージェントに多角的な学習信号を提供します。 12種類のベンチマークを用いた検証の結果、提案手法の「Reagent-U」はGAIAで43.7%、WebWalkerQAで46.2%という高い性能を達成し、複雑なタスクにおける推論報酬モデルの有効性が証明されました。
TL;DR(結論)
従来のエージェント学習が最終結果の正誤のみに依存する稀薄な報酬に頼っていたのに対し、本研究は推論の過程を詳細に評価する「Agent-RRM」を提案しました。 このモデルは、推論の論理性を分析するトレース、具体的な欠陥を指摘する批判、全体的な品質スコアという3つの構造化されたフィードバックを生成し、エージェントに多角的な学習信号を提供します。 12種類のベンチマークを用いた検証の結果、提案手法の「Reagent-U」はGAIAで43.7%、WebWalkerQAで46.2%という高い性能を達成し、複雑なタスクにおける推論報酬モデルの有効性が証明されました。
なぜこの問題か
現在の大規模言語モデルを用いたエージェントの開発において、強化学習は複雑な推論やツールの利用能力を向上させるための重要な手法となっています。しかし、既存のエージェント向け強化学習の多くは、最終的な回答が正しいか否かという「結果ベースの稀薄な報酬」に過度に依存しているという課題があります。このような報酬設計では、最終ステップでわずかなミスをしただけの軌跡と、最初から全く見当違いな行動をとった軌跡を区別することができず、学習の効率が最適化されません。特に、複数のステップにわたってツールを使い分ける必要がある長期的なタスクでは、中間段階での推論の質を評価できないことが、エージェントの性能向上を阻む大きな要因となっています。 また、より詳細なフィードバックを提供するためにステップ単位の報酬モデルを導入する試みもありますが、これには膨大なアノテーションコストがかかるだけでなく、報酬ハッキングと呼ばれる現象に対して脆弱であるという問題が指摘されています。…
核心:何を提案したのか
本研究の核心は、エージェントの軌跡に対して構造化されたフィードバックを生成する多面的な評価モデル「Agent-RRM(Agent Reasoning Reward Model)」の提案です。このモデルは、従来の報酬モデルのように単一のスカラー値を出力するのではなく、以下の3つのコンポーネントからなる詳細な判断を下します。第一に、軌跡の論理的な一貫性を分析する内部推論トレース(think)です。第二に、推論や実行における具体的な欠陥を特定し、洗練のためのガイダンスを提供する標的型批判(critique)です。第三に、プロセスのパフォーマンスを総合的に評価する全体的な品質スコア(score)です。これにより、グローバルな最適化のためのスカラー報酬と、明示的なエラー修正のためのテキスト批判を組み合わせた、透明性の高い粒度の細かい評価が可能になります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related