表形式データのための人間とLLMの協調による特徴量エンジニアリング
大規模言語モデルを特徴量候補の提案役に特化させ、その選択プロセスをベイズ最適化に基づく効用モデルと分離することで、モデルの内部的な直感に頼った非効率な探索を排除し、低収益な操作の繰り返しを抑制する新しいフレームワークを提案した。
TL;DR(結論)
大規模言語モデルを特徴量候補の提案役に特化させ、その選択プロセスをベイズ最適化に基づく効用モデルと分離することで、モデルの内部的な直感に頼った非効率な探索を排除し、低収益な操作の繰り返しを抑制する新しいフレームワークを提案した。 効用推定が困難な初期段階において、専門家のドメイン知識をペア比較形式の選好フィードバックとして適応的に取り入れる仕組みを導入し、人間の認知負荷を最小限に抑えながら、限られた試行回数の中でより効果的な特徴量変換を特定することを可能にした。 多様なテーブルデータセットを用いた合成実験および実際のユーザーを対象とした実験の結果、提案手法は既存の自動機械学習手法や言語モデル単独の手法を上回る予測性能を達成し、同時に専門家が特徴量設計プロセスで感じる精神的な負担を大幅に軽減することを確認した。
なぜこの問題か
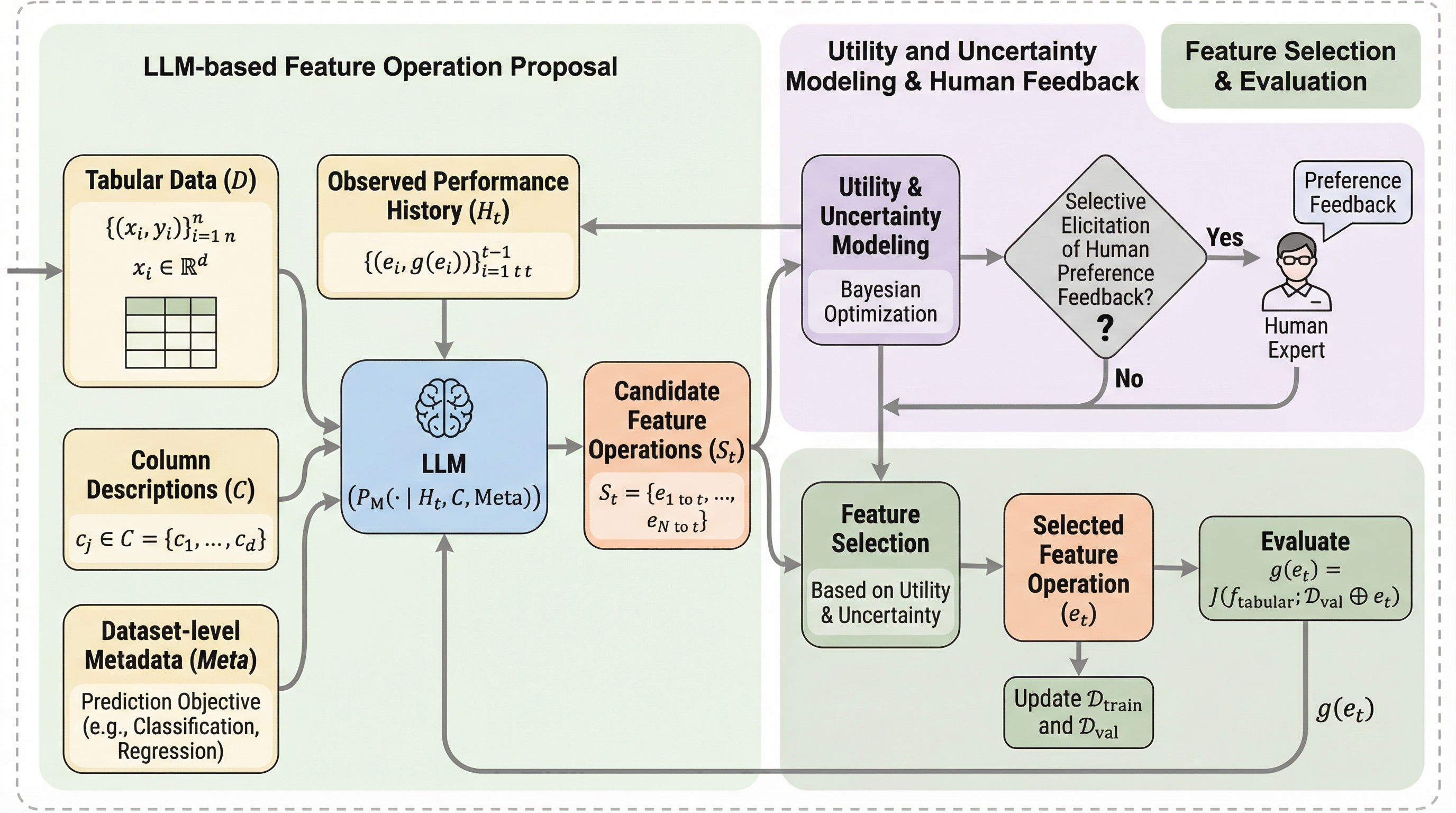
現代のAI活用において、不正検知やオンラインプラットフォームの推薦システムなど、多岐にわたる分野でテーブルデータは最も普及しているデータ形式の一つである。金融取引の記録やユーザーのプロフィールといった構造化された情報を扱う際、生のデータ列を意味のある表現に変換する特徴量エンジニアリングの質が、最終的な予測モデルの性能を左右する極めて重要な要素となる。しかし、このプロセスを自動化しようとする従来の自動機械学習(AutoML)の手法は、あらかじめ定義された演算子を機械的に適用するものが多く、タスク固有の文脈や意味的な理解を欠いているため、冗長な特徴量を生成しやすく、最適な性能に到達できないという課題があった。 近年、大規模言語モデル(LLM)が持つ高度な言語理解能力と推論能力を活用し、タスクの説明や特徴量の意味的な記述から、人間に近い感覚で特徴量を生成する試みが注目されている。しかし、既存のLLMを用いた手法の多くは、モデルを「ブラックボックスな最適化器」として扱い、特徴量の提案から選択までの全工程をモデル内部のヒューリスティクスに委ねている。…
核心:何を提案したのか
本研究では、人間とLLMが協調してテーブルデータの特徴量エンジニアリングを行うための新しいフレームワークを提案した。このフレームワークの最大の特徴は、特徴量変換操作の「提案」と「選択」のプロセスを明確に分離(デカップリング)した点にある。LLMは、その強力な意味的理解力を活かして多様な特徴量候補を生成する「提案者」としての役割に専念させる。一方で、提案された候補の中からどれを実際に採用するかという「選択」のプロセスは、各操作の効用と不確実性を明示的にモデリングするベイズ最適化の枠組みによって制御される。 この分離により、LLMの内部的なバイアスや不透明な判断に依存することなく、統計的な根拠に基づいた効率的な探索が可能になる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related