ラベルを超えて:ランキングと選択クエリで情報効率を高めるヒューマン・イン・ザ・ループ二値分類学習
人を二値ラベルの「回答者」として扱うだけでは、1回の対話で得られる情報が最大でも1ビット程度に制限され、少ないデータで分類器を学びたい場面ほど対話回数と負担が増えやすいです。 / 本研究は、項目集合から代表例を選んでラベルも付ける選択クエリと、項目を強い順に並べて最後の正例位置まで示すランキングクエリを導入し、埋め込み空間での分類境界との距離が人の暗黙スコアに結び付くという観測に基づいて応答確率をモデル化します。 / シミュレーション注釈者でサンプル複雑度の大幅な削減を示し、さらに注釈コストを入れた情報レート最適化により、単語感情分類では従来のラベルのみ能動学習より学習時間が57%超短縮されたと報告しています。
TL;DR(結論)
- 人を二値ラベルの「回答者」として扱うだけでは、1回の対話で得られる情報が最大でも1ビット程度に制限され、少ないデータで分類器を学びたい場面ほど対話回数と負担が増えやすいです。
- 本研究は、項目集合から代表例を選んでラベルも付ける選択クエリと、項目を強い順に並べて最後の正例位置まで示すランキングクエリを導入し、埋め込み空間での分類境界との距離が人の暗黙スコアに結び付くという観測に基づいて応答確率をモデル化します。
- シミュレーション注釈者でサンプル複雑度の大幅な削減を示し、さらに注釈コストを入れた情報レート最適化により、単語感情分類では従来のラベルのみ能動学習より学習時間が57%超短縮されたと報告しています。
なぜこの問題か
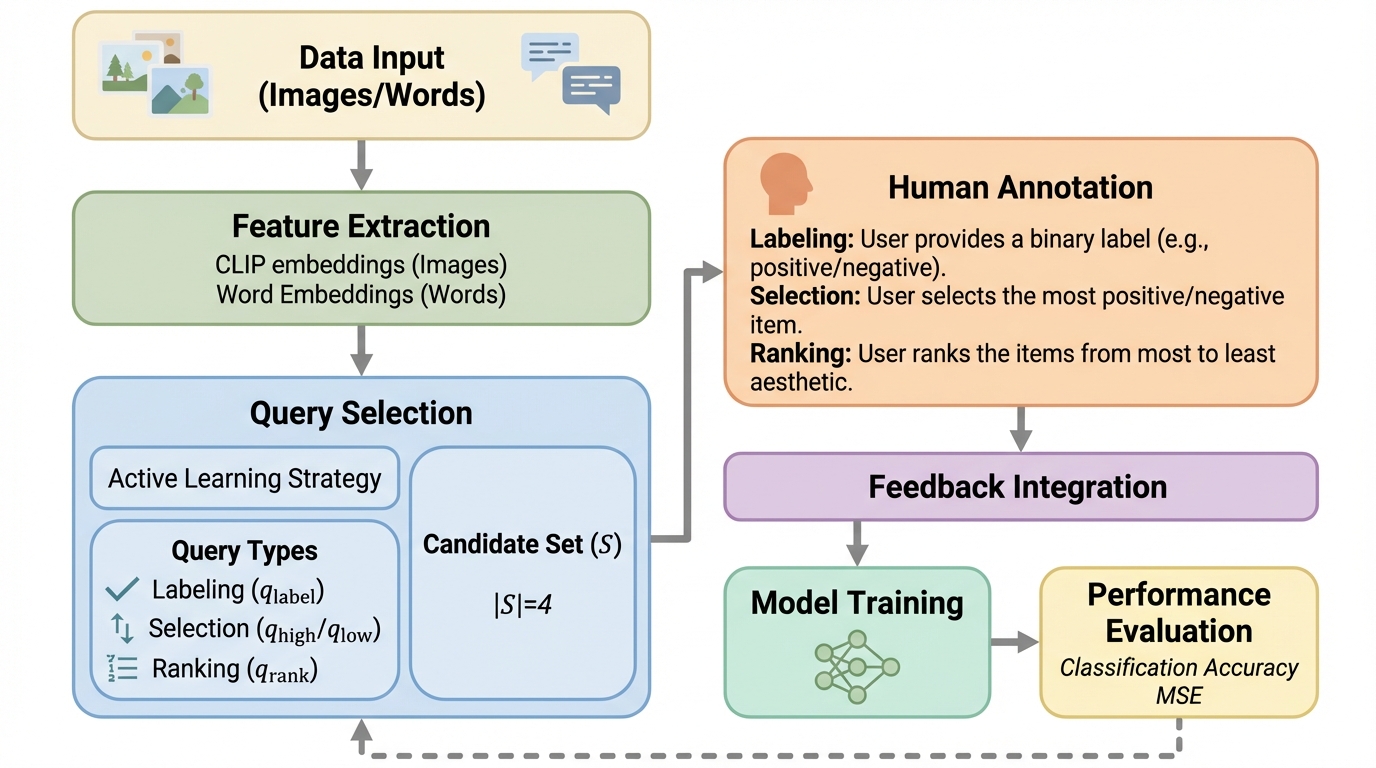
人の専門的判断を機械学習に取り込む際、専門家はしばしば「ラベルを返すだけの存在」として扱われますが、この形は人の判断のニュアンスを取りこぼしやすいです。論文が問題視するのは、二値分類のラベル応答が本質的に単純で、1回の応答が運ぶ情報量が最大でも1ビット程度に頭打ちになる点です。能動学習は、問い合わせる対象を工夫して必要なラベル数を減らす考え方ですが、問い合わせ形式自体が二値ラベルに固定されている限り、この情報ボトルネックが残ります。 一方で、人は二値判断を求められても、実際には比較や参照点の想起を通じて強弱を捉えることがあると説明されています。たとえば「今週で最悪に近い」といった相対的な位置づけを使うように、頭の中では順位付けや代表例の選択に近い処理が起き得ます。それにもかかわらず、多くのヒューマン・イン・ザ・ループ手法は、比較や順位といった直感的な操作を切り捨て、ラベルの入出力に閉じてきました。 そこで本研究は、「ラベル以外の、より豊かなクエリ」によって、1回の対話からより多くの学習信号を引き出せないかを問います。…
核心:何を提案したのか
本研究が提案する中心は、二値分類器を学ぶヒューマン・イン・ザ・ループの枠組みにおいて、二値ラベル以外の「豊かなクエリ型」を第一級の要素として扱うことです。導入するクエリは大きく2種類で、(1)項目集合からスコアが最も高い(または低い)項目を選び、その項目のラベルも返す選択クエリ、(2)集合内の項目を高い順に並べ、さらに「最後の正例」がどこかを示すランキングクエリです。ランキングでは順序そのものに情報があるだけでなく、最後の正例位置が閾値として働き、集合内の各項目ラベルをまとめて回収できる形になります。 重要なのは、これらを単なる入力インターフェースの工夫としてではなく、人の応答がどのような確率で生じるかを明示的にモデル化し、そのモデルに基づいて能動学習を設計している点です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related