「Mine and Refine」:段階的関連度を前提にしたEC検索リトリーバ学習を整理します
EC検索の候補生成では、完全一致だけでなく代替品や補完品も許容されるため、関連度を段階で扱い、段階ごとに類似度スコアの境界が分かれるように学習しておくと、ハイブリッド混合やしきい値設定が安定しやすくなります。
TL;DR(結論)
- EC検索の候補生成では、完全一致だけでなく代替品や補完品も許容されるため、関連度を段階で扱い、段階ごとに類似度スコアの境界が分かれるように学習しておくと、ハイブリッド混合やしきい値設定が安定しやすくなります。
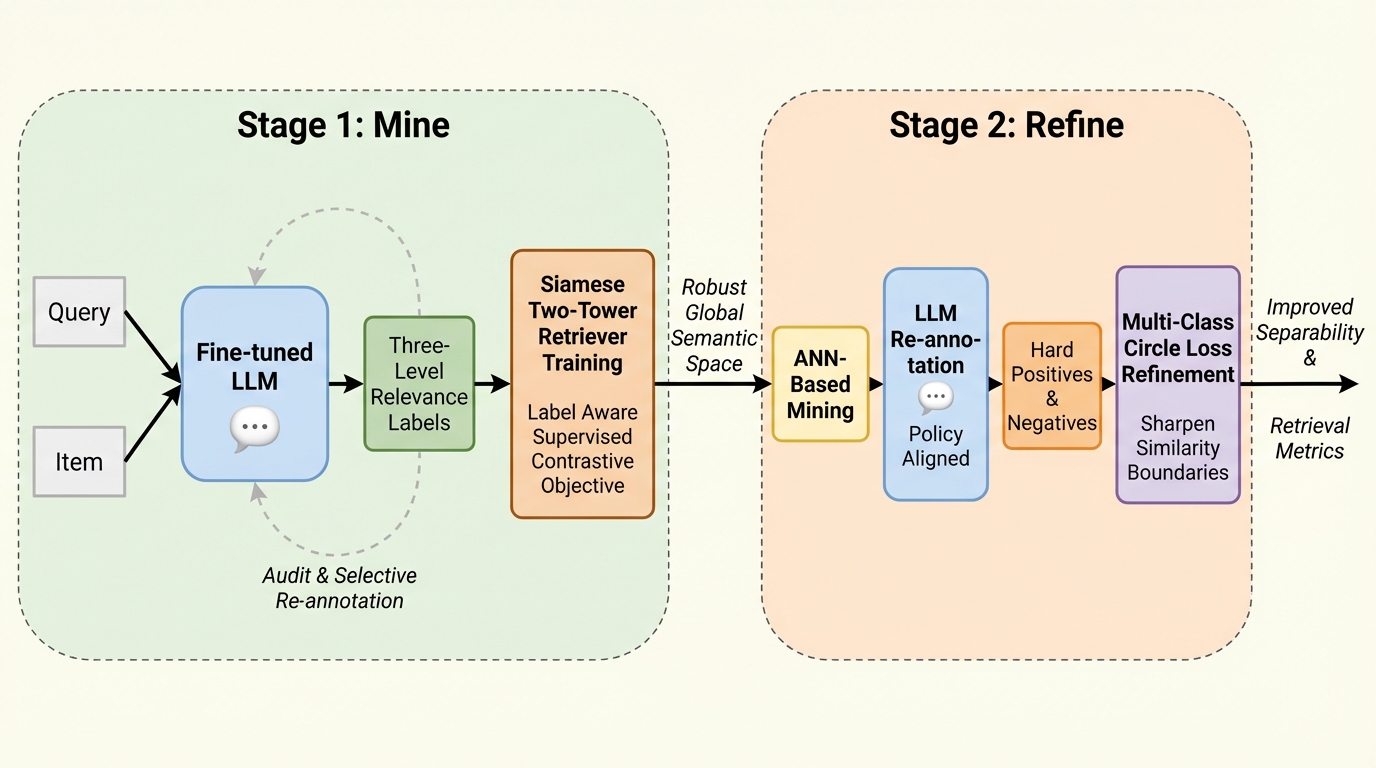
- そこで著者らは、人手注釈に沿った3段階の関連度を軽量な大規模言語モデルで大規模に付与し、利用状況のシグナルで不一致箇所を監査してノイズを減らしたうえで、2段階の対照学習「Mine and Refine」により多言語の二塔型リトリーバを鍛える枠組みを提案します。
- 近傍探索で紛らわしい候補を掘り起こして再注釈し、段階間の境界を明示的に鋭くする損失で洗練することで、オフラインの関連度指標と本番A/Bのエンゲージメントおよびビジネス影響の双方で統計的に有意な改善が示されたと報告されています。
なぜこの問題か
意味ベースの検索は、クエリと商品テキストが表記として一致しない場合でも、同義語や言い換え、暗黙の意図を手掛かりに候補を取り出せるため、現代のEC検索の中核になりつつあります。ところがマルチカテゴリのマーケットプレイスでは、商品タイトルや属性の整備状況が揃わず、在庫も変動し、さらに入力はロングテールでスペルミスや略語、ノイズ混じり、場合によっては多言語も混ざるため、埋め込みが汎化しにくい条件が重なります。加えて本番の候補生成は、レイテンシやメモリ、インデックス制約の下で動くため、クエリ埋め込みはリアルタイム計算、商品埋め込みは事前計算して近傍探索に載せる、といった運用上の制約も避けられません。候補集合が不安定だと下流のランキングやビジネスロジックが振り回されるため、単に当たるだけではなく、下流が扱いやすい「安定した候補」を返すことも重要になります。 このとき実務で効いてくる難点として、関連度が二値に収まりにくい点が挙げられています。買い物では、完全一致以外にも、別ブランドや別サイズといった代替品、あるいは近い購買意図を満たす補完品が受け入れられる一方で、無関連は避けなければ信頼を損ねます。…
核心:何を提案したのか
著者らは、マルチカテゴリのEC検索に向けて、意味埋め込みを学習する2段階の対照学習フレームワーク「Mine and Refine」を提案しています。狙いは、ロングテールでノイズの多いクエリにも一般化できる埋め込みを作りながら、プロダクトやポリシーの制約に整合する形で、教師データを現実的なコストで増やすことです。中心となる設計は、関連度を3段階(関連・中程度の関連・無関連)として扱い、その段階間で類似度スコアが明確に分かれるように最適化する点にあります。これにより、候補生成の出力が下流で扱いやすくなり、混合やしきい値の設定が安定しやすいという実務要請に応えます。 提案は学習手法だけではなく、教師信号の作り方も含みます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related