セミカスケード型全二重対話システムのためのユニットベースのエージェント
本研究では、複雑な音声対話を「対話ユニット」という最小単位に分解し、マルチモーダル大規模言語モデル(MLLM)が「継続」か「切り替え」かを判断することで、人間のように自然な同時双方向(全二重)対話を実現する新しいフレームワークを提案しました。
TL;DR(結論)
本研究では、複雑な音声対話を「対話ユニット」という最小単位に分解し、マルチモーダル大規模言語モデル(MLLM)が「継続」か「切り替え」かを判断することで、人間のように自然な同時双方向(全二重)対話を実現する新しいフレームワークを提案しました。 このシステムは、音声認識(ASR)の結果を補助的な文脈として利用しつつ、MLLMがユーザーの音声波形から直接音響情報を読み取って意思決定を行う「セミカスケード」設計を採用しており、特定のデータによる追加学習を必要とせず、既存のコンポーネントを組み合わせて即座に運用できる高い実用性を備えています。 検証の結果、従来のテキストベースのシステムと比較して応答遅延を大幅に短縮し、ユーザーの割り込みや相槌を正確に識別できることを証明し、国際的なチャレンジである「人間のような音声対話システム・チャレンジ」の全二重相互作用部門において、全参加チーム中第2位という極めて優れた成績を収めました。
なぜこの問題か
現実世界における人間同士の音声対話は、単に交互に言葉を交わすだけではなく、相手の話を聞きながら相槌を打ったり、重要な場面で言葉を挟んだりする「全二重」の性質を持っています。しかし、従来の音声対話システムの多くは、一方が話し終えるまでもう一方が待機する「半二重」方式に依存しており、これが人間と機械のコミュニケーションにおける不自然さの大きな原因となっていました。この課題を解決するために、主に「エンドツーエンド・モデル」と「カスケード・パイプライン」という2つの手法が研究されてきましたが、それぞれに一長一短があります。エンドツーエンド・モデルは、音声の感情や抑揚といったパラ言語情報を保持しやすい反面、膨大な学習データと計算資源を必要とし、特定のタスクへの適応が困難です。一方で、音声認識、大規模言語モデル、音声合成を繋ぎ合わせるカスケード・パイプラインは、既存の優れた技術を統合しやすく実用的ですが、各段階での処理によって音響的なニュアンスが失われやすく、さらに各モジュールの処理時間が積み重なることで応答に深刻な遅延が発生するという問題を抱えています。…
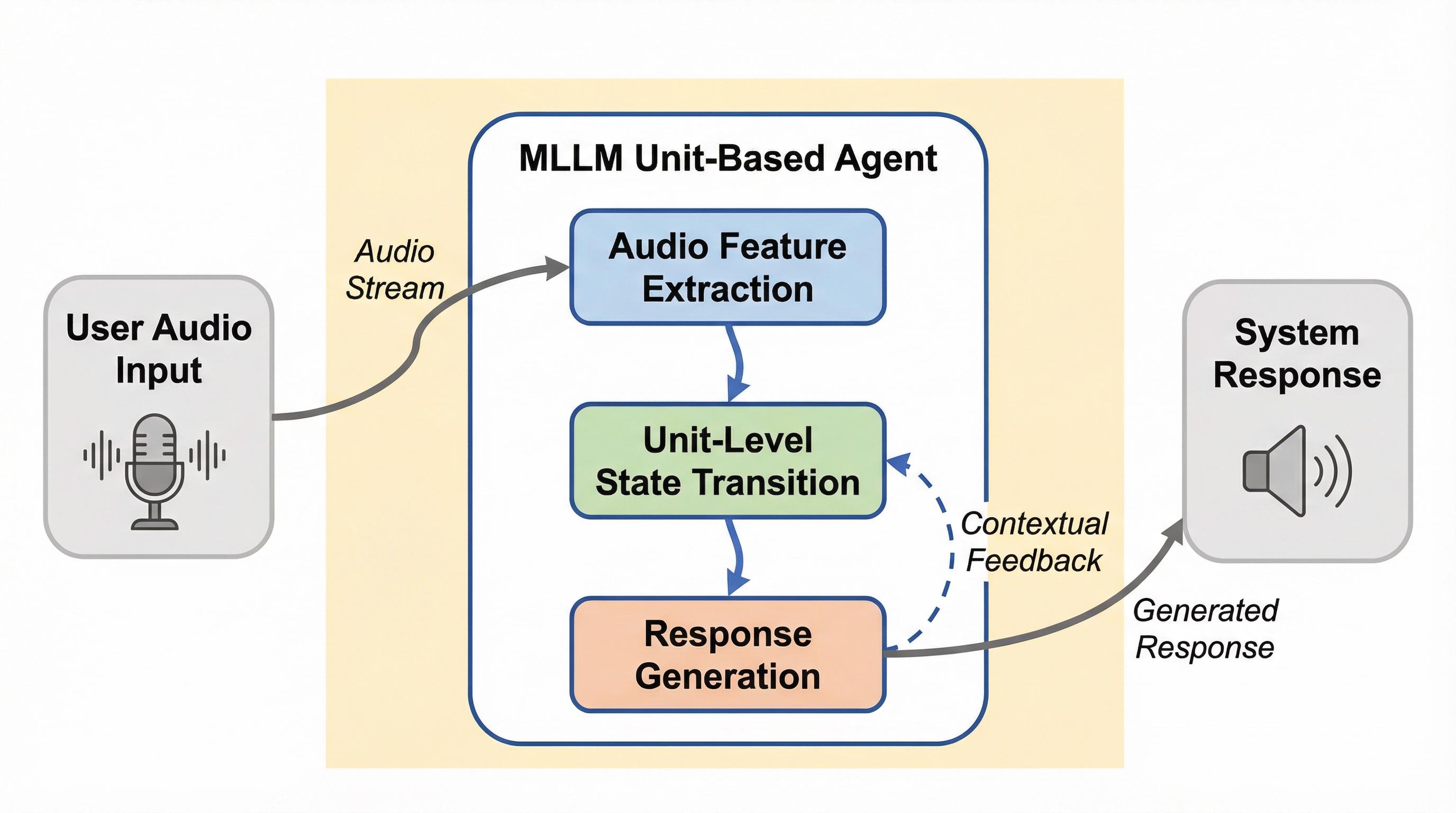
核心:何を提案したのか
本論文では、対話の流れを「対話ユニット」という最小の構成単位に分解して管理する、革新的なユニットベースの全二重対話フレームワークを提案しています。このフレームワークの核心は、複雑な対話プロセスをユニットごとの独立した処理として定義し、各ユニット内での「聞く(Listen)」状態と「話す(Speak)」状態の遷移を、マルチモーダル大規模言語モデル(MLLM)による単一の意思決定空間で制御する点にあります。この設計は「セミカスケード」と呼ばれ、従来のテキストのみを介在させる方式とは一線を画します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related