AI生成プルリクエストの品質とレビュアーの感情に関する調査
AIエージェントは人間と比較して既存コードの再利用を軽視する傾向があり、機能は同じでも構文が異なる「意味的な重複(タイプ4クローン)」を約1.87倍も多く生成していることが判明しました。 それにもかかわらず、人間のレビュアーはAIが作成したコードに対して、人間が書いたものよりも中立的または肯定的な感情を抱きやすく、深刻な冗長性や設計上の欠陥を見逃している可能性があります。 この「品質と感情の乖離」は、AIコードが表面上は正しく動作して見えるために警戒心が下がり、長期的には修正困難な「静かな技術的負債」が大規模に蓄積していくリスクを強く示唆しています。
TL;DR(結論)
AIエージェントは人間と比較して既存コードの再利用を軽視する傾向があり、機能は同じでも構文が異なる「意味的な重複(タイプ4クローン)」を約1.87倍も多く生成していることが判明しました。 それにもかかわらず、人間のレビュアーはAIが作成したコードに対して、人間が書いたものよりも中立的または肯定的な感情を抱きやすく、深刻な冗長性や設計上の欠陥を見逃している可能性があります。 この「品質と感情の乖離」は、AIコードが表面上は正しく動作して見えるために警戒心が下がり、長期的には修正困難な「静かな技術的負債」が大規模に蓄積していくリスクを強く示唆しています。
なぜこの問題か
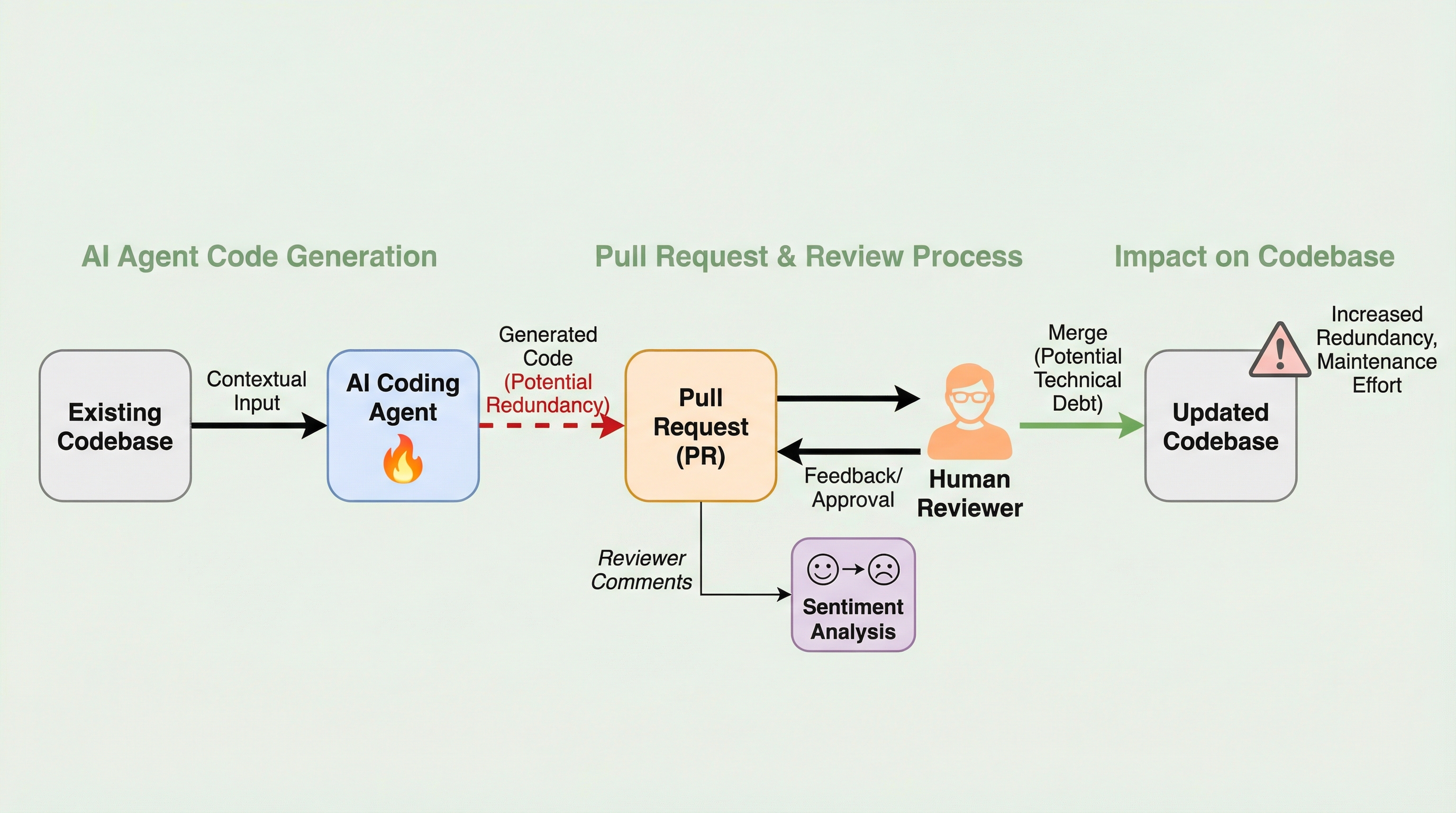
ソフトウェア開発の分野は、大規模言語モデル(LLM)を活用したエージェントが単なる補助ツールから、自律的にタスクを遂行するチームメイトへと進化する「SE 3.0」と呼ばれる新しい時代に突入しています。現在、多くの開発現場でAIエージェントがプルリクエストを自動生成し、開発速度を劇的に向上させていますが、その一方で生成されたコードが長期的な保守性や可読性にどのような影響を与えるかについては、まだ十分に解明されていません。これまでの評価指標の多くは「テストの合格率」などの短期的な指標に偏っており、コードベース全体の健全性を測る視点が欠けていました。 特に懸念されるのが、ソフトウェア工学において「不吉な臭い」として忌避されるコードの重複(冗長性)の問題です。人間は既存のコードをコピー・アンド・ペーストすることで形式的な重複を作ることが多いですが、LLMはその確率的な性質から、既存のロジックと同じ機能を持ちながら異なる変数名や構文を使用する「意味的な重複(タイプ4クローン)」を生み出しやすいという特性があります。このような重複は、従来のキーワード一致に基づくツールでは検出が極めて困難です。…
核心:何を提案したのか
本研究は、AIエージェントが作成したプルリクエスト(Agentic-PR)の品質を、内部的な「コードの質」と外部的な「レビュアーの反応」という二つの側面から多角的に評価する新しいフレームワークを提案しました。内部的な評価においては、従来の「コード行数」や「循環的複雑度」といった静的な指標に加え、新たに「最大重複スコア(Max Redundancy Score: MRS)」という指標を導入しました。これは、AIが既存のコード資産をどれだけ有効に再利用できているか、あるいは無駄に再発明してしまっているかを定量化するためのものです。 この指標の算出には、コードの意味的な文脈を捉えることができる高度な埋め込みモデル「CodeSage-Large」を活用しています。これにより、単なる文字列の比較ではなく、機能的な類似性に基づいた「タイプ4クローン」の検出を可能にしました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related