「より良い」プロンプトが逆効果になる時:LLMアプリのための評価主導型反復プロセス
LLMの出力は非決定論的でモデル更新に敏感なため、従来の決定論的なテスト手法では不十分であり、「定義・テスト・診断・修正」の4フェーズからなる評価主導型の反復ワークフローを導入することで、場当たり的な調整から再現可能なエンジニアリングプロセスへの転換を提案する。
TL;DR(結論)
LLMの出力は非決定論的でモデル更新に敏感なため、従来の決定論的なテスト手法では不十分であり、「定義・テスト・診断・修正」の4フェーズからなる評価主導型の反復ワークフローを導入することで、場当たり的な調整から再現可能なエンジニアリングプロセスへの転換を提案する。 汎用、RAG、エージェントの各用途向けに最小限必要な評価要素を階層化した「MVES(Minimum Viable Evaluation Suite)」フレームワークを提示し、自動チェック、人間による基準、LLMを評価者とする手法を統合して、正確性や根拠性などの多角的な次元で品質を検証する。 実証実験では、良かれと思って導入した汎用的な改善プロンプトが、Llama 3の抽出精度を100%から90%へ、RAGの遵守率を93.3%から80%へ低下させる現象を確認し、特定のタスクにおける改善が他での回帰を招くリスクと、タスク固有の評価スイートによる検証の重要性を明らかにした。
なぜこの問題か
LLMアプリケーションの評価は、従来のソフトウェアテストとは根本的に異なる困難さを抱えている。従来のAPIであれば、特定の入力に対して決定論的な出力が返るため、期待値との完全一致を確認するだけで検証が可能であった。しかし、LLMの出力は確率的であり、同じ入力に対しても実行ごとに結果が変動する非決定性を持っている。これはハードウェアの数値計算やデコードの実装、並列処理、あるいはモデル自体の更新に起因する。また、自然言語による出力は高次元であり、意味的に正しくても表現が異なる場合があるため、単純な文字列比較では品質を測ることができない。例えば「フランスの首都はパリだ」と「パリはフランスの首都として機能している」は意味的に同一だが、テキストとしては異なる。さらに、ユーザーの期待値は文脈に依存する暗黙的な仕様であることが多く、何をもって「良い回答」とするかを形式化することが難しい。モデルの更新も頻繁に行われ、昨日まで正常に動作していたプロンプトが、モデル側の変更によって突然期待外れの挙動を示すリスクも存在する。 このような背景から、場当たり的なプロンプト調整ではなく、体系的かつ再現可能な評価手法の確立が急務となっている。…
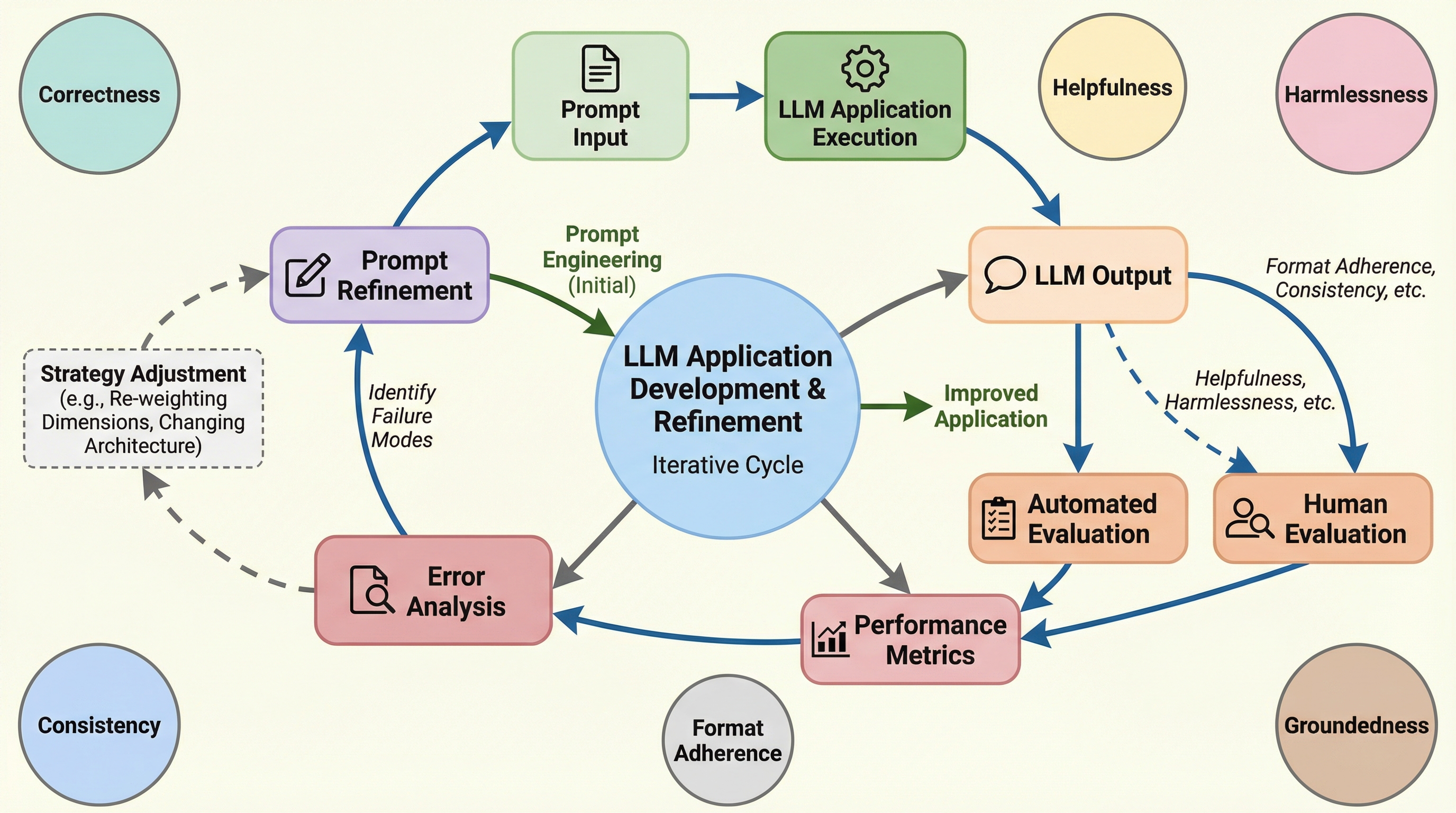
核心:何を提案したのか
本研究では、LLMアプリケーション開発における課題を解決するために、「定義(Define)」「テスト(Test)」「診断(Diagnose)」「修正(Fix)」の4つのフェーズを繰り返す評価主導型のワークフローを提案している。このサイクルの中心となるのが、最小実行可能な評価スイートである「MVES(Minimum Viable Evaluation Suite)」である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related