ProRAG: 検索拡張生成のためのプロセス監視型強化学習
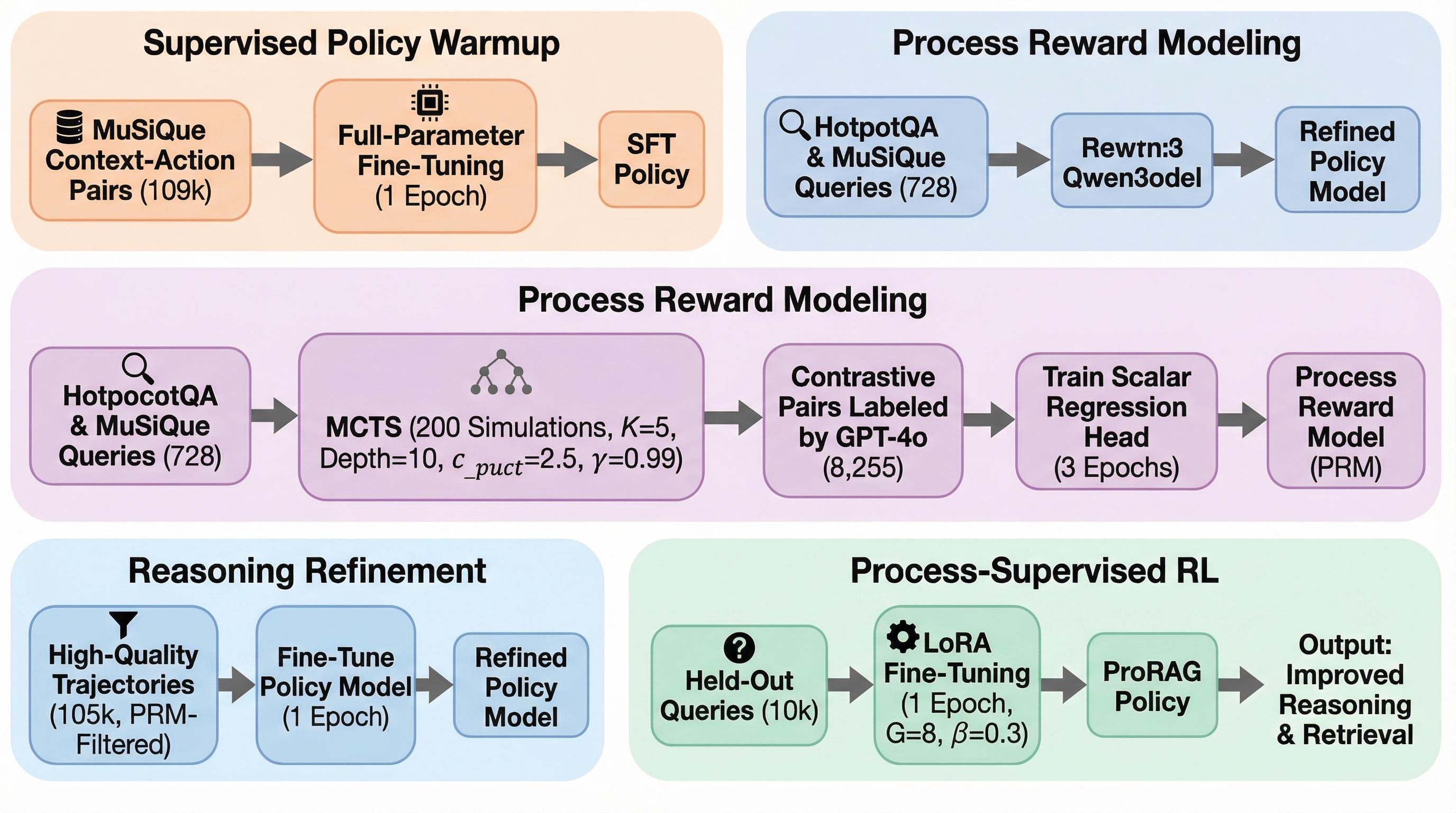
従来の検索拡張生成(RAG)における強化学習は、最終回答の正誤のみを報酬とするため、途中の論理が誤っていても正解に辿り着けば評価される「プロセスの幻覚」という課題を抱えていましたが、本研究が提案するProRAGは、モンテカルロ木探索(MCTS)を用いて構築したプロセス報酬モデル(PRM)を活用し、推論の各ステップに対して詳細なフィードバックを与える「プロセス監視型強化学習」の枠組みを導入しました。 この手法は、ステップ単位のプロセス報酬と最終的な結果報酬を組み合わせる「二重の粒度を持つアドバンテージメカニズム」により、複雑な多段階推論タスクにおいて従来のモデルを凌駕する高い性能、論理的正確性、および推論効率を実現しており、モデルは単に答えを当てるだけでなく、正しい思考プロセスそのものを内面化することが可能になります。 5つのマルチホップ推論ベンチマークを用いた広範な実験の結果、ProRAGは結果ベースの強化学習や既存のプロセス認識手法よりも優れた性能を示し、特に長い推論過程を必要とする困難なタスクにおいて、きめ細やかなプロセス監視が疎な結果報酬よりも効果的な最適化信号を提供することを実証しました。
TL;DR(結論)
従来の検索拡張生成(RAG)における強化学習は、最終回答の正誤のみを報酬とするため、途中の論理が誤っていても正解に辿り着けば評価される「プロセスの幻覚」という課題を抱えていましたが、本研究が提案するProRAGは、モンテカルロ木探索(MCTS)を用いて構築したプロセス報酬モデル(PRM)を活用し、推論の各ステップに対して詳細なフィードバックを与える「プロセス監視型強化学習」の枠組みを導入しました。 この手法は、ステップ単位のプロセス報酬と最終的な結果報酬を組み合わせる「二重の粒度を持つアドバンテージメカニズム」により、複雑な多段階推論タスクにおいて従来のモデルを凌駕する高い性能、論理的正確性、および推論効率を実現しており、モデルは単に答えを当てるだけでなく、正しい思考プロセスそのものを内面化することが可能になります。 5つのマルチホップ推論ベンチマークを用いた広範な実験の結果、ProRAGは結果ベースの強化学習や既存のプロセス認識手法よりも優れた性能を示し、特に長い推論過程を必要とする困難なタスクにおいて、きめ細やかなプロセス監視が疎な結果報酬よりも効果的な最適化信号を提供することを実証しました。
なぜこの問題か
大規模言語モデル(LLM)の急速な進化に伴い、外部知識を動的に取り入れる検索拡張生成(RAG)は、単なる情報の取得と生成のパイプラインから、モデルが自律的に検索戦略を立ててツールを操作する「エージェント型システム」へと進化を遂げています。しかし、このような動的なワークフローを最適化することは極めて困難な課題です。特に、複数の情報を組み合わせて回答を導き出すマルチホップな推論タスクでは、どのタイミングで何を検索し、得られた情報をどう解釈して次の一手を打つべきかという中間的な意思決定が、最終的な回答の質を左右する極めて重要な要素となります。これまでの研究では、最終的な回答の正誤をスカラー値の報酬としてモデルを最適化する強化学習が主流でしたが、これには「報酬の疎性」と「クレジット割り当て」という深刻な問題がつきまといます。 長い推論の過程において、最終的な答えが偶然正解であったとしても、その途中の論理展開が支離滅裂であったり、不要な検索を繰り返していたり、あるいは検証されていない仮定に基づいている場合があります。…
核心:何を提案したのか
本論文では、マルチホップRAGにおけるクレジット割り当て問題を根本から解決するために、学習されたステップレベルの監視をオンライン最適化ループに直接統合する革新的なフレームワーク「ProRAG」を提案しています。ProRAGの核心は、単なる結果の報酬に依存するのではなく、推論の各段階に対して即時かつ精密なフィードバックを提供する仕組みを構築した点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related