UEval: 画像とテキストの両方を生成する統合モデルのためのベンチマーク
本研究は、テキストの問いかけに対して画像とテキストの両方で回答する「統合マルチモーダル生成」を評価するための新しいベンチマーク「UEval」を提案しました。専門家が厳選した1,000件の質問と、それに対する10,417件の検証済み評価基準(ルーブリック)を用いることで、従来の画像理解や画像生成のみの評価では捉えきれなかった、複雑な推論を伴うマルチモーダルな応答能力を詳細に測定することが可能になります。検証の結果、最新のGPT-5-Thinkingでも100点満点中66.4点に留まり、オープンソースモデルの最高値は49.1点であるなど、現在の統合モデルにとって非常に難易度が高い課題であることが明らかになるとともに、推論プロセスが生成品質の向上に寄与することが示されました。
TL;DR(結論)
本研究は、テキストの問いかけに対して画像とテキストの両方で回答する「統合マルチモーダル生成」を評価するための新しいベンチマーク「UEval」を提案しました。専門家が厳選した1,000件の質問と、それに対する10,417件の検証済み評価基準(ルーブリック)を用いることで、従来の画像理解や画像生成のみの評価では捉えきれなかった、複雑な推論を伴うマルチモーダルな応答能力を詳細に測定することが可能になります。検証の結果、最新のGPT-5-Thinkingでも100点満点中66.4点に留まり、オープンソースモデルの最高値は49.1点であるなど、現在の統合モデルにとって非常に難易度が高い課題であることが明らかになるとともに、推論プロセスが生成品質の向上に寄与することが示されました。
なぜこの問題か
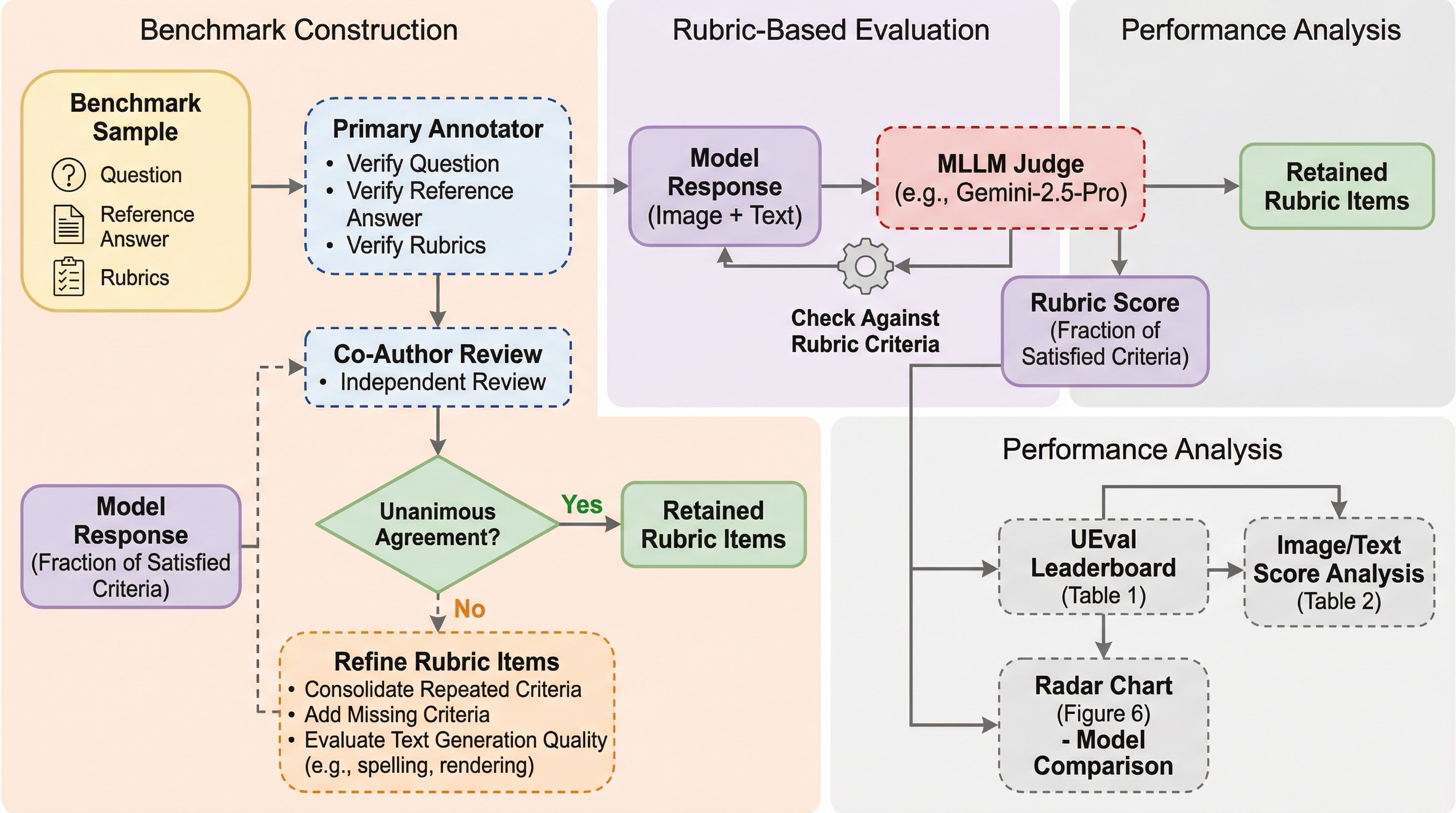
現在のマルチモーダルモデルの評価は、主に二つの枠組みに限定されています。一つは、入力された画像に対してテキストで回答する「視覚的質問応答(VQA)」であり、もう一つは、テキストの説明から画像を生成する「テキストからの画像生成(T2I)」です。しかし、現実世界の複雑なタスクにおいては、一つの問いに対して画像で概念を図示しながら、同時にテキストでその視覚的要素を説明するという、画像とテキストが密接に連携した応答が求められる場面が多く存在します。これまでのベンチマークは、言語と視覚の豊かな相互作用を十分に捉えることができていませんでした。例えば、自由形式のマルチモーダル生成を評価する場合、単純な「LLMを審判とする手法」では、生成された画像とテキストの間の微妙なニュアンスや整合性を見落とす可能性があります。 また、既存の評価手法の多くは、特定のデータに依存しない汎用的なプロンプトを用いて採点を行っていますが、これでは個別の質問に含まれる固有の文脈や詳細な要求を正確に評価することが困難です。…
核心:何を提案したのか
本研究では、統合モデルを評価するための挑戦的なベンチマークである「UEval」を提案しました。UEvalは、モデルがユーザーの複雑なクエリに対して、画像と自然言語の両方を用いて推論し、応答することを要求します。このベンチマークは、8つの現実世界のタスクから構成される1,000件の専門家厳選の質問を含んでいます。これらの質問は、ステップバイステップのガイドから教科書の解説まで、幅広い推論タイプをカバーしています。UEvalの最大の特徴は、データ依存型のルーブリック(評価基準)に基づいたスコアリングシステムを採用している点です。各質問に対して、参照となる画像とテキストの回答が用意されており、これをもとにマルチモーダル大規模言語モデル(MLLM)が初期のルーブリックを生成します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related